研究背景与目的
滑坡灾害突发性强、分布范围广,对当地基础设施、生态环境和居民生命财产安全造成了巨大威胁。我国西部山区地形起伏较大、地质构造活跃、季节性降雨集中,滑坡灾害频发。国家减灾委员发布的《"十四五"国家综合防灾减灾规划》中提到,我国亟需提高灾害风险管理水平,提升防灾减灾科技支撑能力。
滑坡易发性评价是地质灾害风险防治的重要组成部分,通过准确、可靠的评价技术,识别滑坡高易发性区域,可为防灾减灾工作提供科学依据。目前,滑坡易发性评价理论方法主要分成知识驱动和数据驱动。
研究目的:本文提出一种将统计方法、机器学习模型和聚类算法结合的滑坡易发性综合评价方法。选用众多学者使用较多的IV、CF和FR统计方法,分别与RF进行结合,引入ISO聚类分级方法,得到3种耦合模型(IV-RF-ISO、CF-RF-ISO、FR-RF-ISO),并与自然断点法和Kmeans聚类进行对比,探究不同聚类方法对易发性评价结果的影响。
研究方法分类
知识驱动法
基于专家经验的主观判断和定性分析评价方法
数据驱动法
基于统计分析和机器学习等技术,从大量数据中挖掘滑坡发生的规律
集成模型
将统计方法与机器学习模型结合,创建混合评价模型
研究方法
技术路线
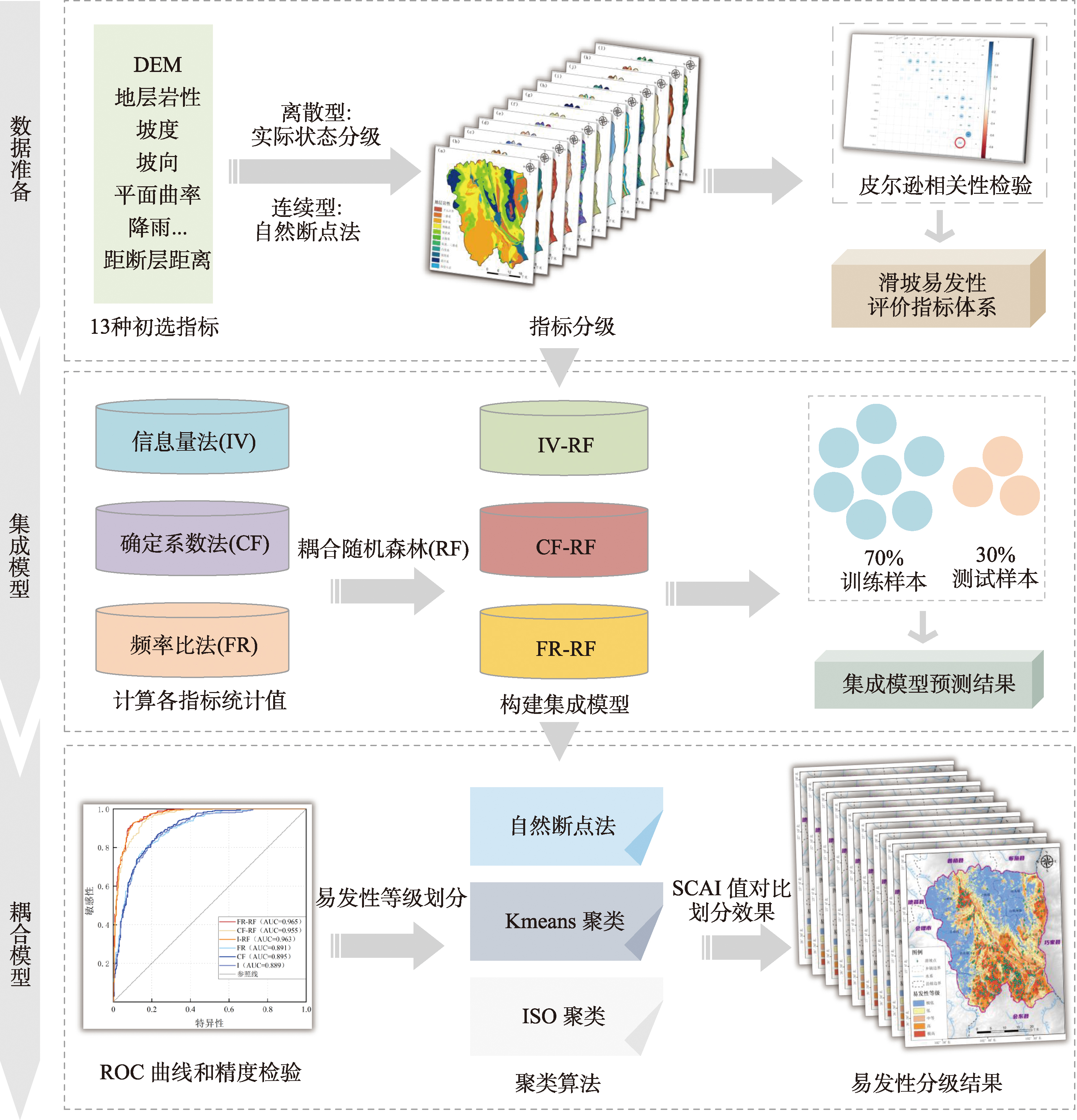
图1 耦合统计方法、机器学习模型与聚类算法的滑坡易发性评价技术路线
首先,在研究区内初选13种易发性评价指标并分级,通过皮尔逊相关性系数法对初选指标进行相关性检验,剔除强相关性因子,建立滑坡易发性评价指标体系。其次,将研究区376个滑坡点作为正样本,在滑坡点一公里缓冲区外选取376个随机点作为负样本,选取70%样本点作为训练样本,30%样本点作为验证样本,提取各影响因子的IV、CF和FR值,在R软件中构建RF滑坡易发性评价模型,对研究区1 865 178个格网进行预测,得到基于IV-RF、CF-RF和FR-RF 3种集成模型的宁南县滑坡易发性结果,再通过绘制ROC曲线使用准确率、精确率、召回率和F1分数对模型预测性能进行精度验证。最后,使用ISO聚类、自然断点法和Kmeans聚类对易发性进行分级,使用SCAI指数评估耦合模型的分级效果。
统计方法
- 信息量法(IV):以信息论为基础计算研究区内影响滑坡的各因子信息量值
- 确定性系数法(CF):根据滑坡点数据计算不同指标因子状态下滑坡发生的先验概率
- 频率比法(FR):计算评价因子对滑坡发生的相对影响程度
随机森林模型(RF)
一种集成学习模型,由多个分类与回归树(CART)组成,可以应对高维数据和大量特征的情况,能够评估特征的重要性,具有良好的泛化能力和鲁棒性。
聚类算法
- K-means聚类:将数据集划分为K个不同的簇
- ISO聚类:基于自组织数据分析技术的聚类方法
- 自然断点法:根据数据分布特点进行分类
精度评价
混淆矩阵指标
- 准确率(Accuracy):正确预测的样本比例
- 精确率(Precision):正确预测的滑坡样本占所有预测为滑坡样本的比例
- 召回率(Recall):正确预测的滑坡样本占所有实际滑坡样本的比例
- F1分数:精确率和召回率的调和平均值
其他评价指标
- ROC曲线:评价模型的分类性能
- AUC值:ROC曲线下的面积,值越大模型性能越好
- 种子单元面积指数(SCAI):评估滑坡灾害易发性评价精度
研究区概况
宁南县地处于四川省西南部,位于102°27′44″E—102°55′09″E,26°50′12″N—27°18′34″N之间,总面积为1 670 km²,地形以山地为主,海拔高度531~3 865 m。气候类型为亚热带季风气候,季节干湿明显,年均降雨量约为1 074 mm。
宁南县地质环境十分复杂,地形地貌条件多变,地处于横断山东北部和青藏高原东南边缘,地势特点为两山夹一槽,地势西北高、东南低,沟壑纵横,崇山峻岭连绵不断。
研究区内断裂带主要包括则木河断裂、宁南-会理断裂、大桥河断裂、迴龙弯断裂等。宁南县2022年地质灾害普适型项目调查结果显示,宁南县地质灾害以滑坡为主,自然和人为因素导致的滑坡地质灾害隐患点高达376处。
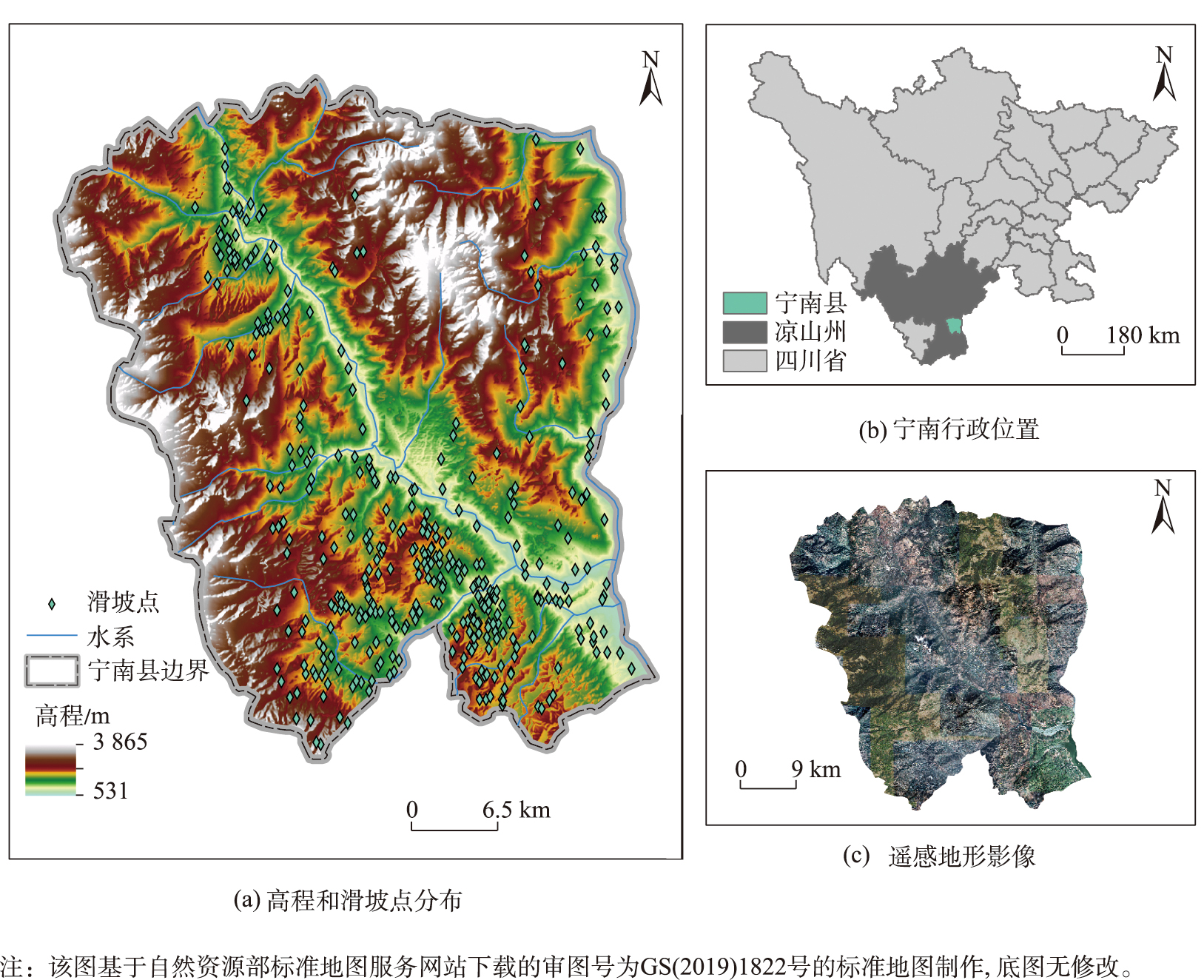
图2 宁南县地理概况
评价指标体系
本文以30 m×30 m的栅格作为基础评价单元,从以下五个方面选取了13个滑坡影响因子:
地质环境
地层、断裂带
地形地貌
高程、坡度、坡向、剖面曲率、平面曲率
气象水文
年降水量、距水系距离
植被土壤
NDVI、土壤质地
人类工程活动
距道路距离、土地利用
对于连续性因子距道路距离、距水系距离、距断层距离、高程按等间距进行分级,离散型因子按实际状态分级,其余因子按自然断点法分级。
研究结果
在进行滑坡易发性评价时,需考虑滑坡影响因子之间的相关性,影响因子的相关性过强时会造成数据的冗余,从而对评价模型的准确性造成影响。本文使用皮尔逊相关性系数(r)确定影响因子之间的相关程度,r的取值在-1~1之间,r的绝对值越接近1,影响因子的相关性越强;若r的绝对值大于0.5,表明影响因子具有强相关性。
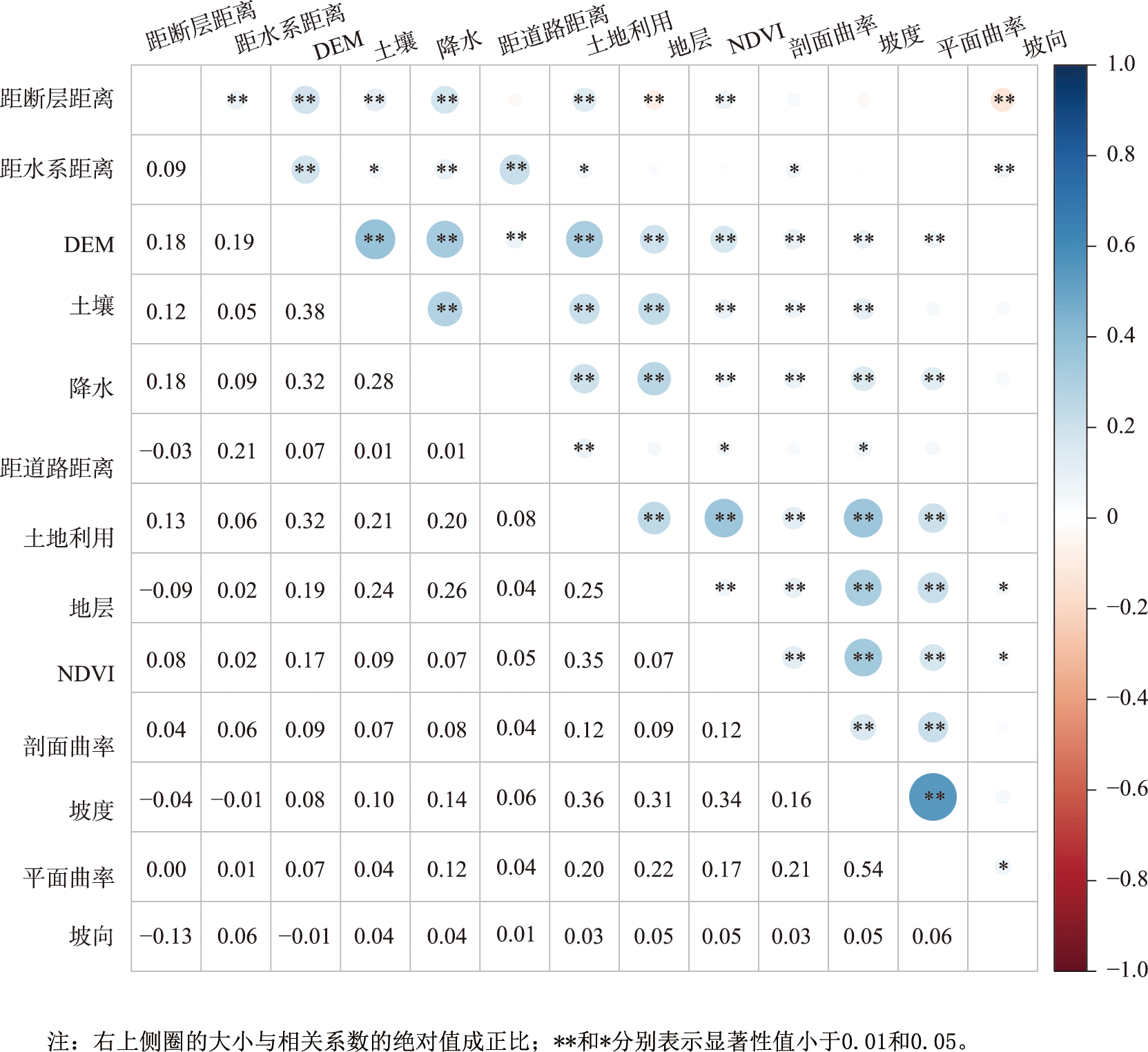
图3 相关性系数矩阵
相关系数计算结果显示,平面曲率和坡度的相关性系数为0.54,具有较强相关性,故在后续滑坡易发性建模过程中剔除平面曲率。
结果分析:统计方法耦合随机森林后的评价精度各方面表现均优于单一模型,准确率和F1分数均大于0.85,AUC值均大于0.9,表明3种集成模型具有良好的拟合精度和预测性能,均有效的评价了宁南县滑坡易发性。且IV模型和CF模型的精确率明显小于召回率,即预测正确的非滑坡样本比例明显小于预测正确的滑坡样本比例,说明模型对非滑坡样本进行了较多的错误分类,此情况在耦合随机森林模型后,得到较好解决。3种集成模型的准确率、F1分数和AUC值的大小排序均为FR-RF>IV-RF>CF-RF,其中FR-RF模型表现最优,其准确率、F1分数和AUC值分别为0.911、0.912和0.965,较单一模型分别提升了0.095、0.096和0.074。
结论
- 集成模型性能优势: IV-RF、CF-RF和FR-RF 3种集成模型性能均优于单一模型,其准确率和F1分数均大于0.85,AUC值均大于0.9,集成模型较好的解决了IV模型和CF模型对非滑坡样本进行了较多的错误分类问题。3种集成模型的综合性能排序为FR-RF>IV-RF>CF-RF,FR-RF模型预测效果最优,其准确率、F1分数和AUC值分别为0.911、0.912和0.965,较单一模型分别提升了0.095、0.096和0.074。
- 聚类算法优势: ISO聚类法的高低易发区SCAI值的比值更大,差异更为显著,综合分级效果优于自然断点法和Kmeans聚类法,其中FR-RF-ISO模型分级效果最好。
- 空间分布特征: IV-RF-ISO、CF-RF-ISO和FR-RF-ISO模型的评价结果在空间分布上大体类似,极高和高易发性区域主要集中在宁南县南部、东部和中部部分区域。评价结果可以为当地滑坡防治和灾害管理提供科学依据。
讨论
不确定性分析
集成模型由统计方法和机器学习模型耦合构成,统计方法能够定量计算影响因子对滑坡易发性的空间影响,将其作为机器学习模型的输入条件。不同统计方法中,CF比IV和FR预测精度更高(AUC=0.895),更能反映影响因子对滑坡发育的空间信息差异。
自然断点法是使用最多的易发性分级方法,它基于数据的分布特点,将数据按照自然分界点分成不同的组,本研究中SCAI值结果显示,它的分级效果具有较好的精度。ISO聚类算法表现出最优秀的分级能力,SCAI值的高低易发性等级差异最显著。
研究存在的问题及展望
由于滑坡的演化机制复杂,影响滑坡的因素众多,相关数据获取困难,本文所使用的易发性评价指标可能并不全面,后期可考虑气象、地下水、岩性、气温、地震等因子,建立更全面的指标体系,提高评价结果准确性。
未来的研究可以考虑引入更多种类的统计方法、聚类方法和机器学习模型,如证据权法、信息熵、回归模型、支持向量机、深度学习、期望最大化(EM)聚类、高斯混合模型(GMM)聚类等,开展相关模型对比研究。