1 引言
实景三维模型是一种数字虚拟空间,逼真地反映了人类的生产、生活和生态空间,已成为数字城市建设和智慧城市发展的重要支撑技术,也是新基建战略的重要组成部分。目前,实景三维的应用和研究在自动化建模、可视化展览和智慧城市等多个领域发挥了重要作用。
分利用实景三维模型的丰富信息,实现场景的自动理解与分析,是推动实景三维模型进行资源环境监测的基础,已经成为当前实景三维应用研究的重要方向。
目前实景三维模型的解译主要采用三维语义分割、基于多视影像的解译以及三维模型和二维影像结合解译等策略。三维语义分割方法包括基于点云的三维语义分割、基于mesh的三维语义分割等。该类方法可以利用实景三维模型中的几何、纹理等信息进行物体识别和分类,但是其对模型的精度和噪声敏感性要求较高。此外,由于其计算量大和泛化能力弱,在大规模城市场景下的实景三维模型解译的问题上仍然存在一定的局限性。
采用三维模型和二维影像解译相结合的策略则可以利用高分辨率遥感影像和地面采集的图像对实景三维模型进行补充和验证,降低解译难度,并且提高实景三维模型解译的精度和可信度。然而,该方法未对立体地物做进一步的分割,导致部分地物粘连、遮挡、边缘不准确等问题。
2 研究方法
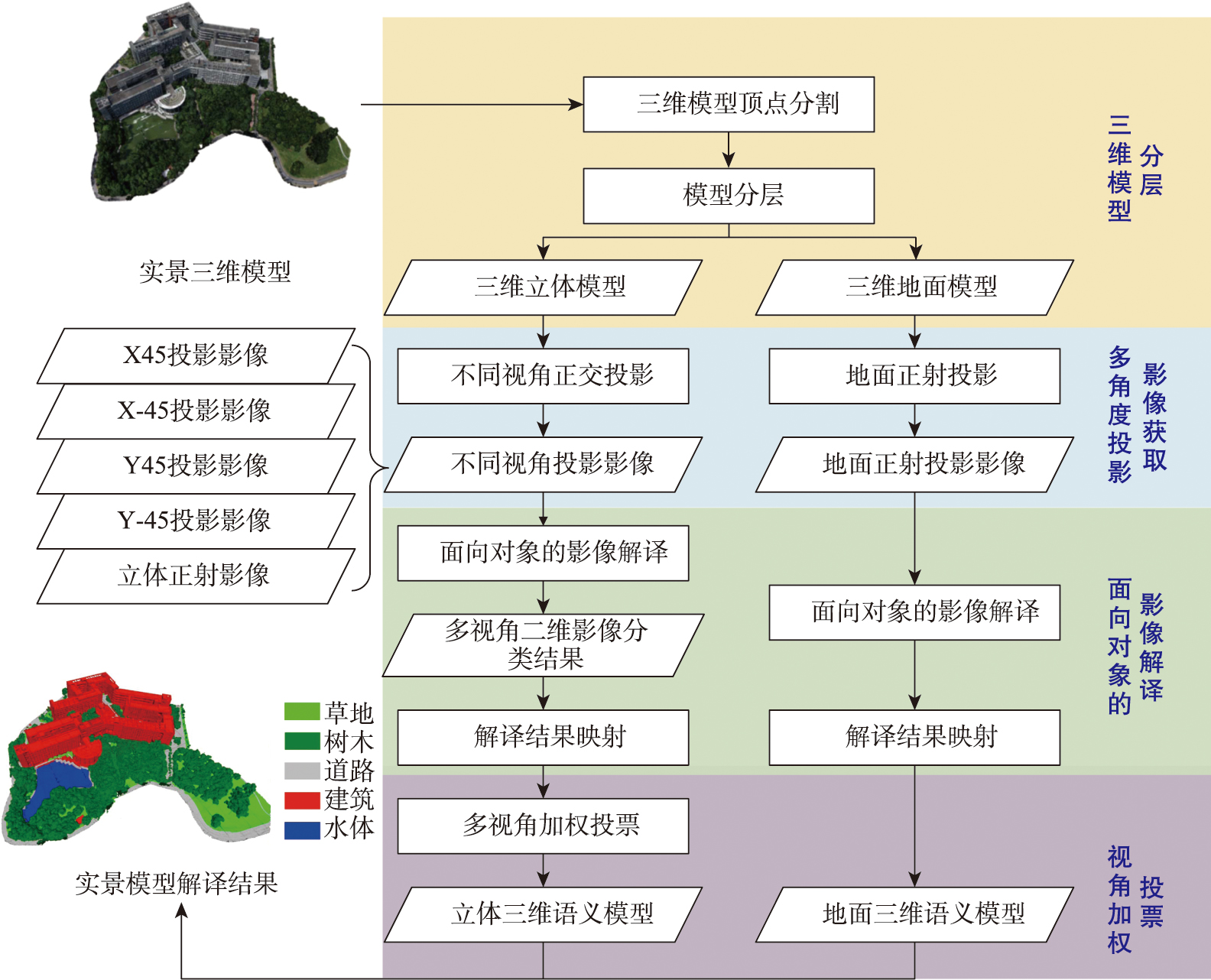
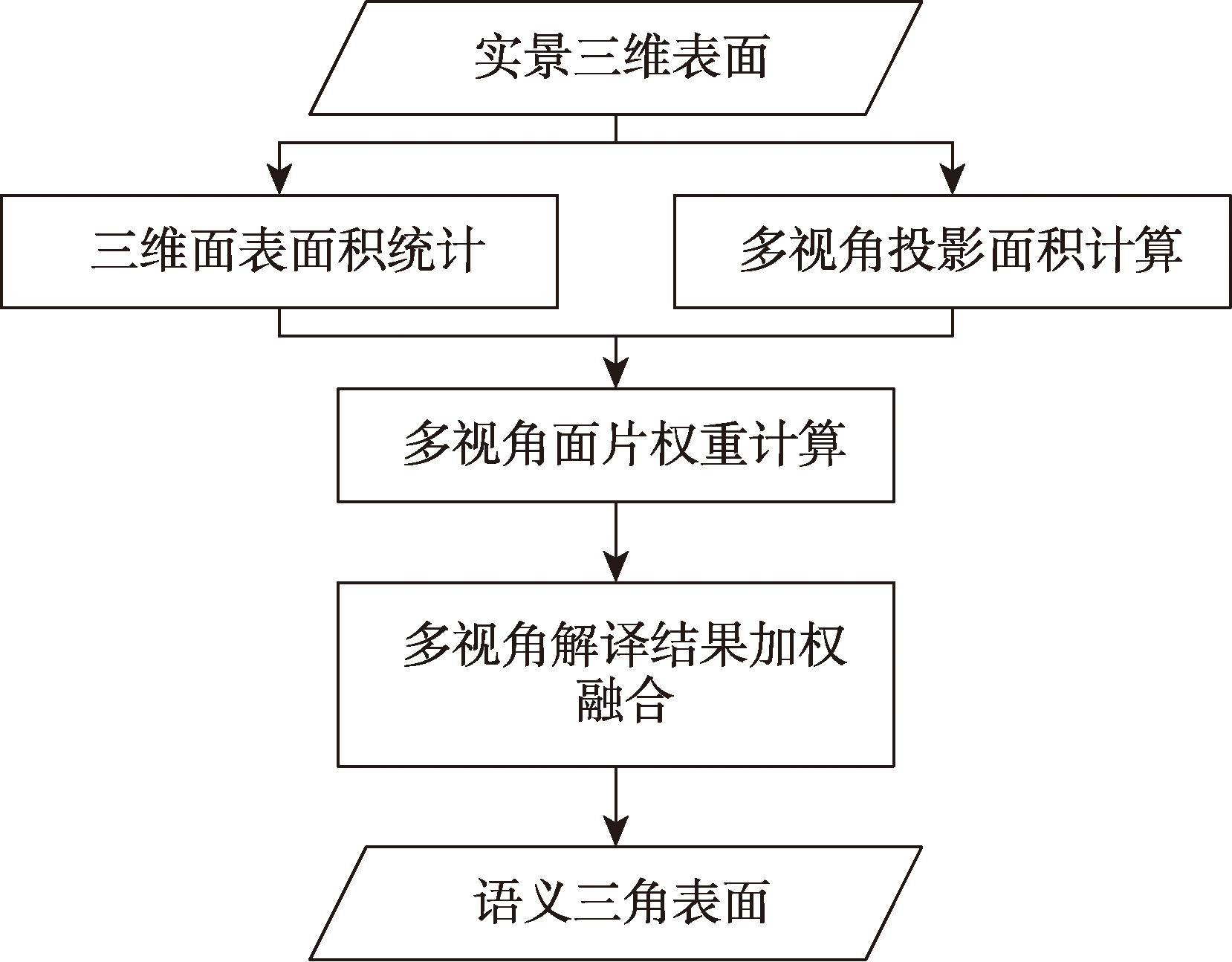
本研究总体技术路线如图1所示。实景三维模型采用层次分割方法实现平缓地表模型和三维立体地物的分层分割。
针对三维立体地物,首先采用多视角倾斜投影,获取多个视角下的二维影像;然后,对各视角影像采用面向对象的影像解译方法进行语义解译;最后,基于二维影像与三维模型的几何投影关系,将解译结果逆向投影到三维模型表面。其中,对于有多个解译结果的区域,本研究提出了多视角加权投票法综合不同观测视角下的三维语义信息,获得最优的解译结果。
2.1 三维模型分层
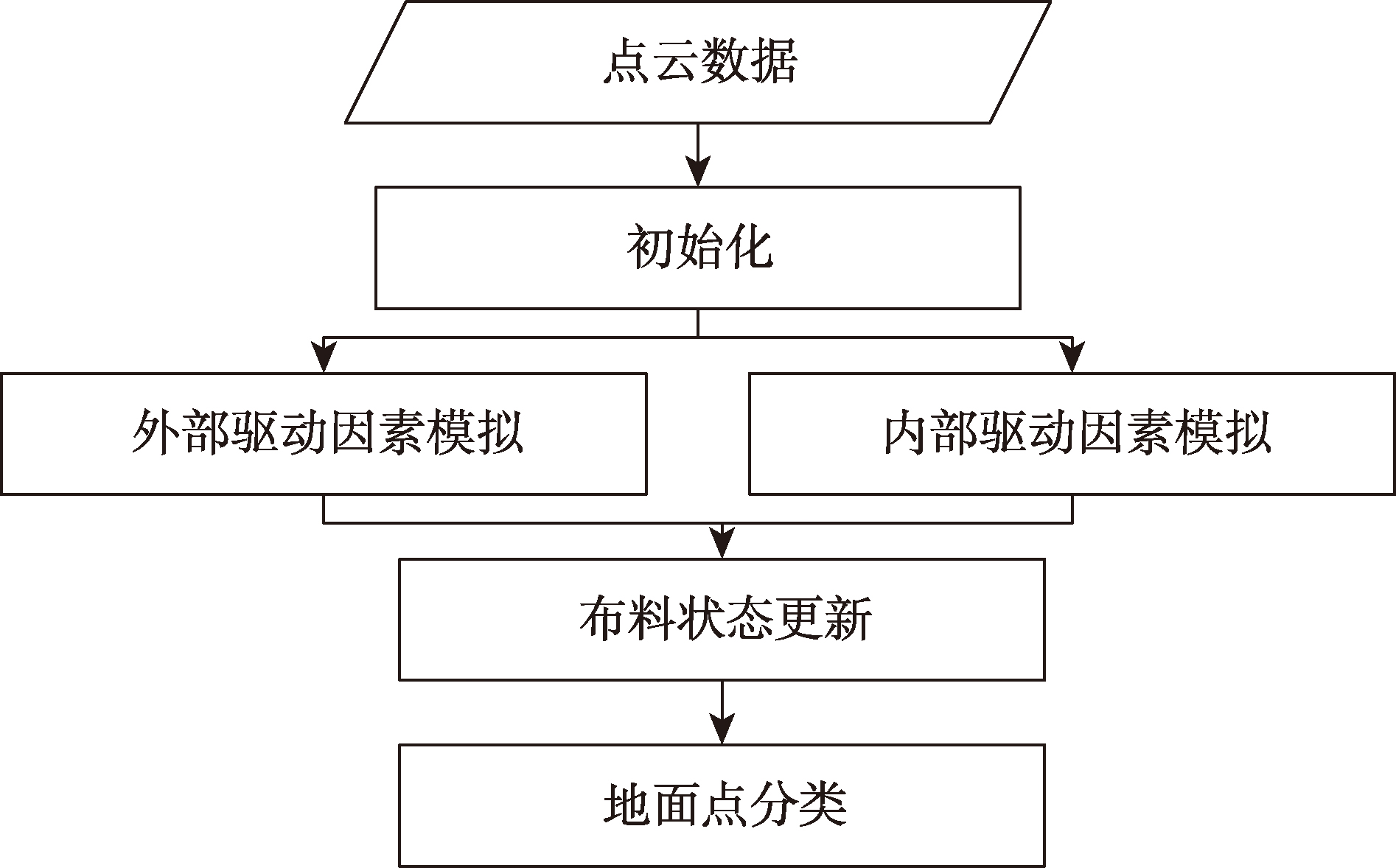
实景三维模型分层旨在将立体地物与起伏平缓的地形表面分开,以降低处理难度,提升精度和处理效率。本研究基于布料模拟滤波(Cloth Simulation Filtering, CSF)算法将实景三维模型的顶点分为地面和非地面点,进一步基于顶点分割结果将实景三维模型分成地形表面与立体地物两部分,并分别进行解译。
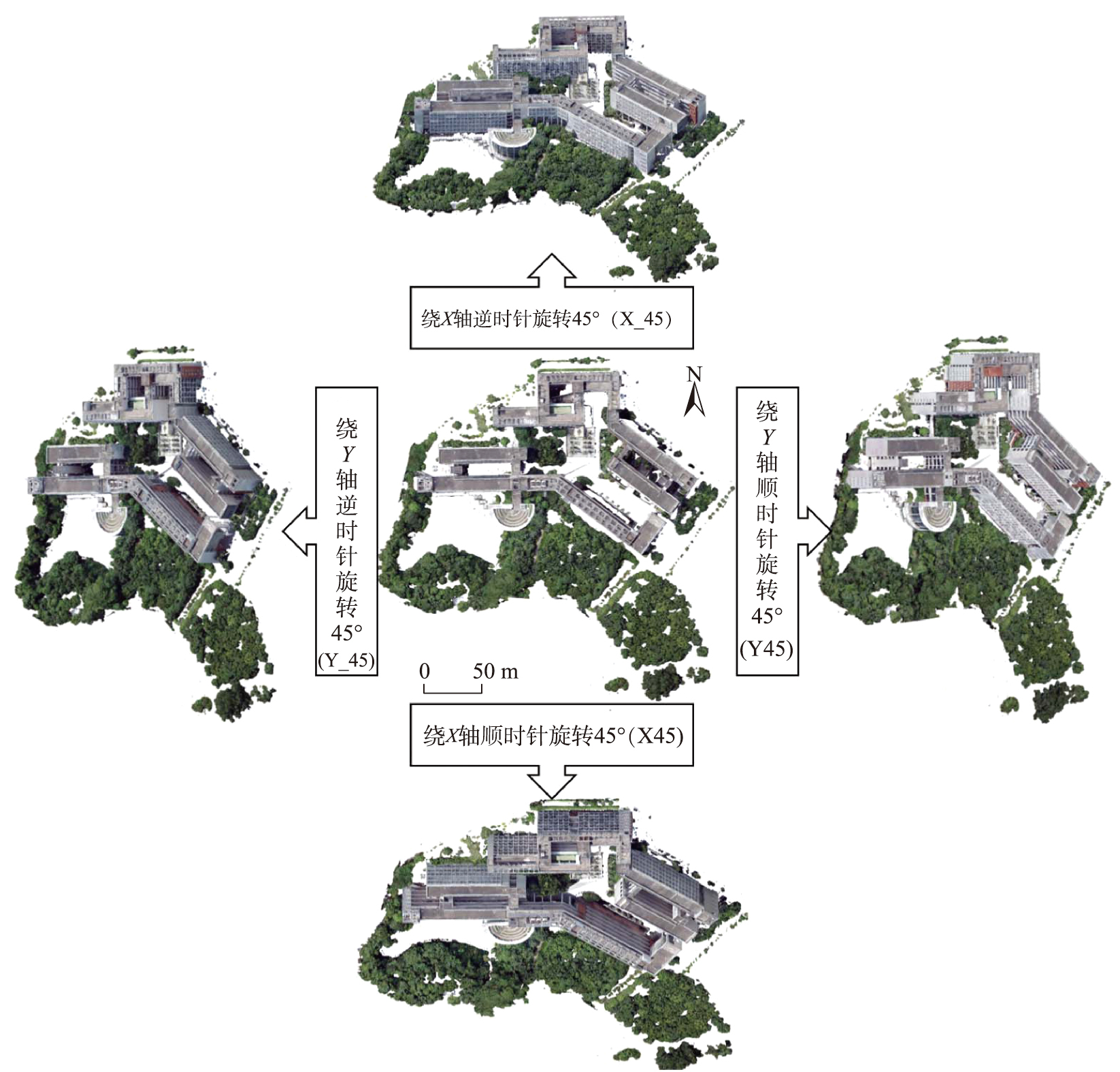
2.2 多角度投影影像获取
由于地物的立体分布层次差异,在某些视角下部分地物会被遮挡,造成无法被观测到。为了解决该问题,本研究使用多视角的策略进行解译,通过从多个视角观察同一场景,可以得到更全面的信息,从而提高对被遮挡物体的解译能力。
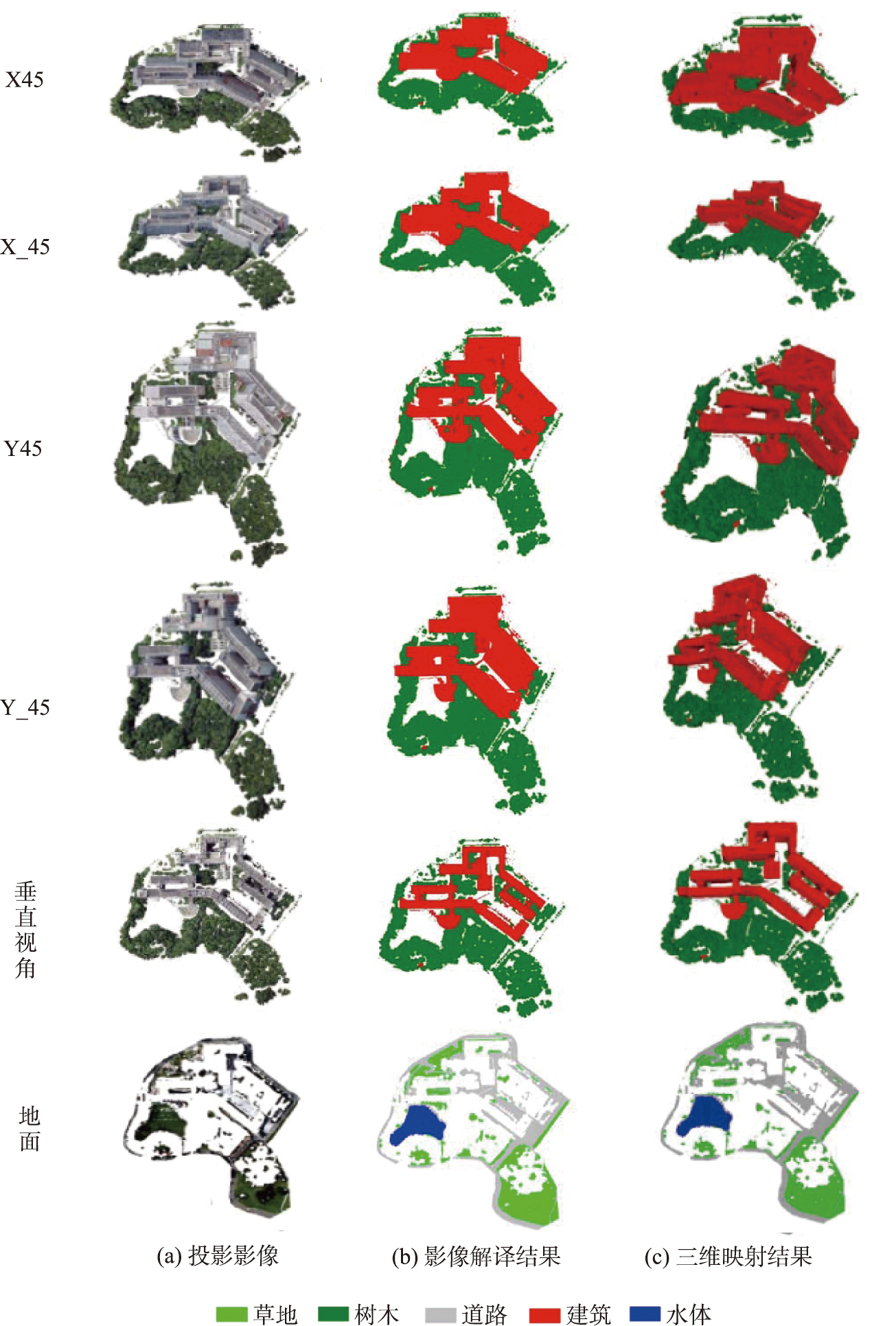
2.3 面向对象的二维投影影像解译
不同视角三维模型的解译,主要包括面向对象的投影影像分类和分类结果三维映射。本研究采用面向对象方法对二维投影影像进行分类,采用无尺度参数的尺度集遥感影像解译方法。这一方法主要包括影像分割、特征提取、机器学习分类以及尺度自动估算等。
2.4 视角加权投票法
视角加权投票法是一种多视角三维解译结果融合方法,主要用于融合来自不同视角的解译结果。对于一个实景三维模型,当观测视角位于模型的一侧时,部分面片可能会被其他部分遮挡,导致某些面片的可见性降低,从而降低了该视角的面积,解译结果的可靠性降低。
3 实验及结果分析
3.1 实验数据与参数设置
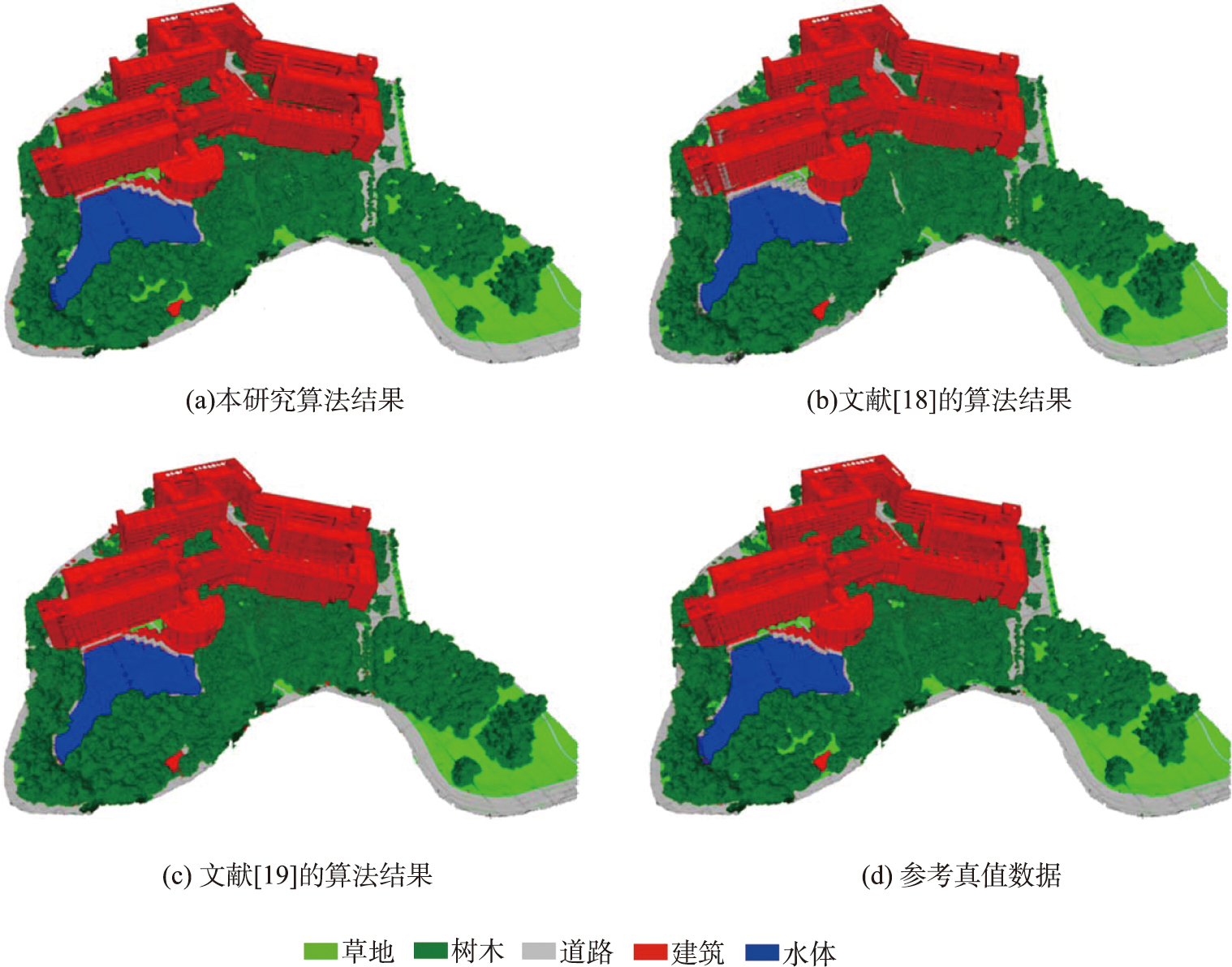
为验证三维模型解译方法的有效性,本研究使用无人机采集研究区(长宽分别约为300m和200m)倾斜相片,并重建实景三维模型(图10)。该场景地形具有一定起伏,包含建筑、树木、草地、水体以及道路等地物类型,且各种地物空间分布上高低错落,具有较好的代表性。
3.2 总体解译结果与精度
本文算法结果如图11(a)所示。为验证本算法的有效性和优势,将分类结果与文献[18]采用的算法、以及文献[19]用的分层解译结果进行比较。人工解译真值如图11(d)所示。
表1 本文算法混淆矩阵
| 类别 |
树木 |
建筑 |
草地 |
道路 |
水体 |
用户精度/% |
| 树木 |
1016152 |
36046 |
5571 |
3182 |
291 |
97.27 |
| 建筑 |
28429 |
1123208 |
1058 |
4328 |
112 |
96.88 |
| 草地 |
26 |
18 |
65763 |
66 |
0 |
90.80 |
| 道路 |
59 |
113 |
37 |
105467 |
17 |
93.30 |
| 水体 |
0 |
0 |
0 |
1 |
8539 |
95.31 |
| 生产者精度/% |
95.75 |
97.07 |
99.83 |
99.79 |
99.99 |
|
|
总体精度: 96.69% | Kappa系数: 0.942
|
3.3 算法原理与结果细节对比
文献[18]的算法以正射影像为主要数据,忽略了地物的立体分布层次,未充分利用地物高度、形状等特征,影响了解译的精度。此外,将二维解译的结果映射到三维模型时,未考虑地物遮挡问题,造成地物侧面、被遮挡地物的分类错误。
根据对表1-表3的精度比较,本研究的算法表现出比文献[18]和文献[19]的算法更高的精度。本研究的算法更适用于地物变化多样的复杂区域,多视角的方法能够更好的利用地物的侧面信息,对地物交界处通过多视角来改正,且对三维模型的精细度要求低于文献[19]的方法。
4 结论与讨论
本文提出了一种基于多视角二维投影的实景三维模型解译方法,通过正射投影、多角度倾斜投影的方法,将实景三维模型转换为多张二维影像,通过面向对象影像解译方法分类。进一步采用逆向投影将语义信息映射到三维模型,并采用加权投票策略实现不同视角语义信息的决策融合。
实验结果表明本方法能够准确地解译出实景三维模型的语义信息,解译的总体精度能够达到96.69%,Kappa系数达到了0.942。对比本文方法与已有同类方法发现,本文所提方法的语义解译精度显著高于已有同类方法。本文采用的多视角策略能够充分利用实景三维中不同视角中的三维侧面信息,有效提高语义解译的精度。
但本研究也有需进一步优化的地方,例如,由于加权投票不是基于面片的,可能会导致解译结果出现斑驳的现象。另外,由于本研究选取的视角是固定的,仍然存在一些侧面甚至底面信息观测不到的情况,导致错分。未来的研究可以针对上述问题,引入超面元和视角自适应的策略,进一步提升解译方法的准确性和鲁棒性。
* 以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。