1. 引言
数字高程模型(DEM)作为自然资源三维立体一张图的时空基底,为数字城市建设提供了统一的空间定位框架和分析基础。目前,立体摄影测量和干涉合成孔径雷达(InSAR)等遥感技术是全球尺度DEM(GDEM)数据获取的主要手段,而且多种30m分辨率的GDEM产品可免费获取,如SRTM、ASTER、AW3D、NASADEM、COPDEM等。
然而,由于城区建筑物等地面物体对雷达和光信号的反射,现有的GDEM产品都不可避免地包含建筑物等高度信息。为此,国内外学者提出了大量关于城区GDEM产品质量修正方法,其可大致归纳为3类:直接法、数理统计法和机器学习法。
相比前2种方法,机器学习因能较好拟合自变量和因变量复杂的非线性关系,广泛应用于GDEM修正。然而,现有方法存在以下问题:(1)忽略了特征变量过多造成的信息冗余问题,容易造成模型过拟合;(2)训练的机器学习模型均为全局模型,忽略了自变量与因变量空间关系的异质性,导致构建的预测模型在局部区域可能会出现偏差。
针对上述瓶颈,本文提出了一种顾及空间异质性和SHAP特征筛选的城区GDEM修正方法。
2. 研究方法
为了提升城区GDEM精度,本文构建了一种顾及空间异质性和SHAP特征筛选的城区GDEM修正方法,主要包括以下3个步骤:
数据预处理
包括机载LiDAR数据处理、Sentinel-2A MSI数据处理等,确保数据质量和一致性。
模型构建
考虑空间异质性进行分区,基于SHAP特征筛选构建随机森林修正模型。
精度评价
通过多种指标评估修正效果,并与现有方法进行比较。
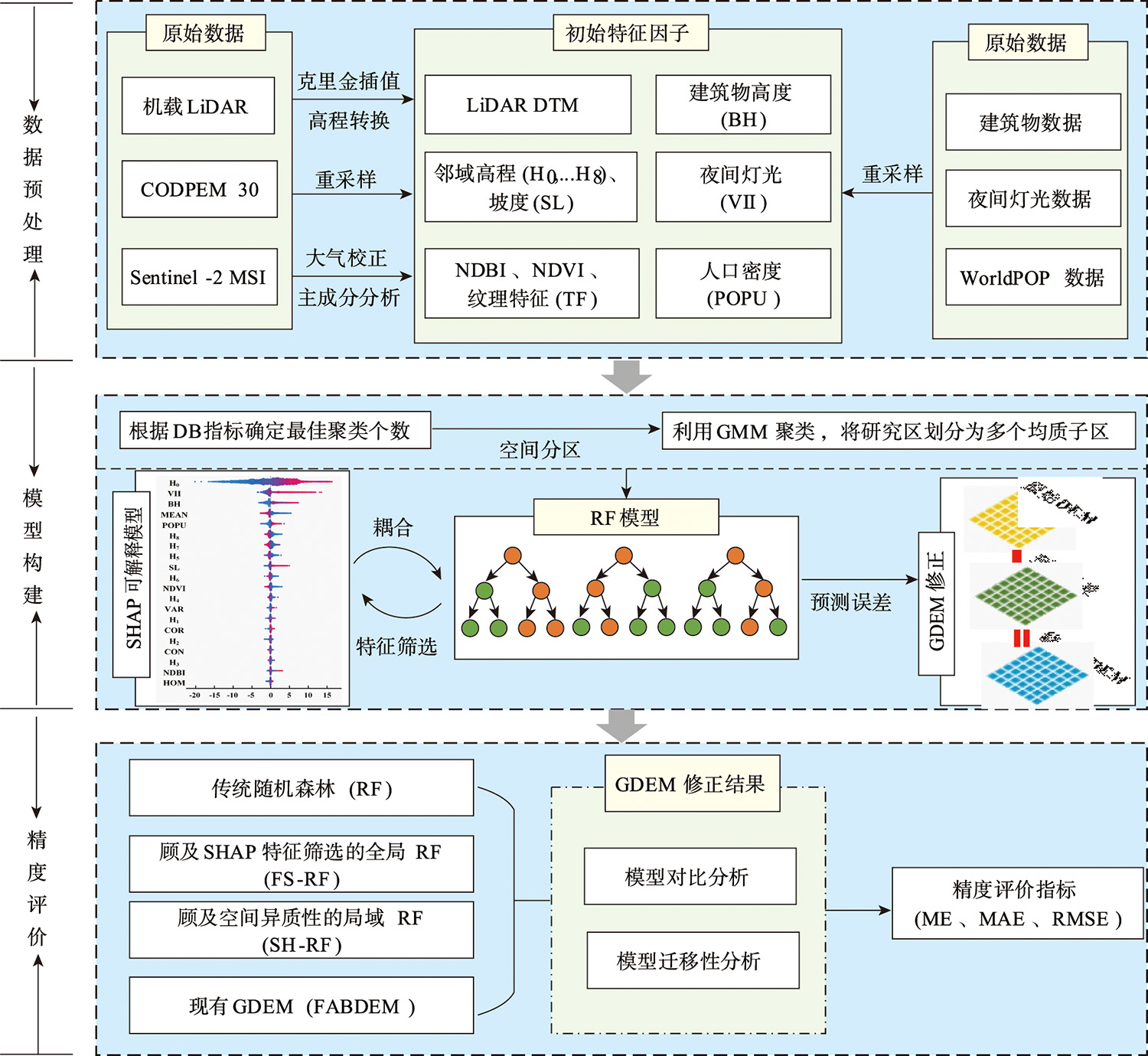
图1 实验方法流程
3. 实验区概况和数据源
3.1 实验区概况
纽约市位于美国纽约州东南部大西洋沿岸,总面积为1214km²,其中425km²为水域,789km²为陆地,下设曼哈顿区、布鲁克林区、皇后区、布朗克斯和斯塔滕岛5个区。
选择该研究区的主要原因:一是该研究区具有典型的城市环境特征,如建筑物密集、楼层高且形状复杂多变;二是整个研究区LiDAR点云数据以及与GDEM修正相关的基础数据可免费获取。
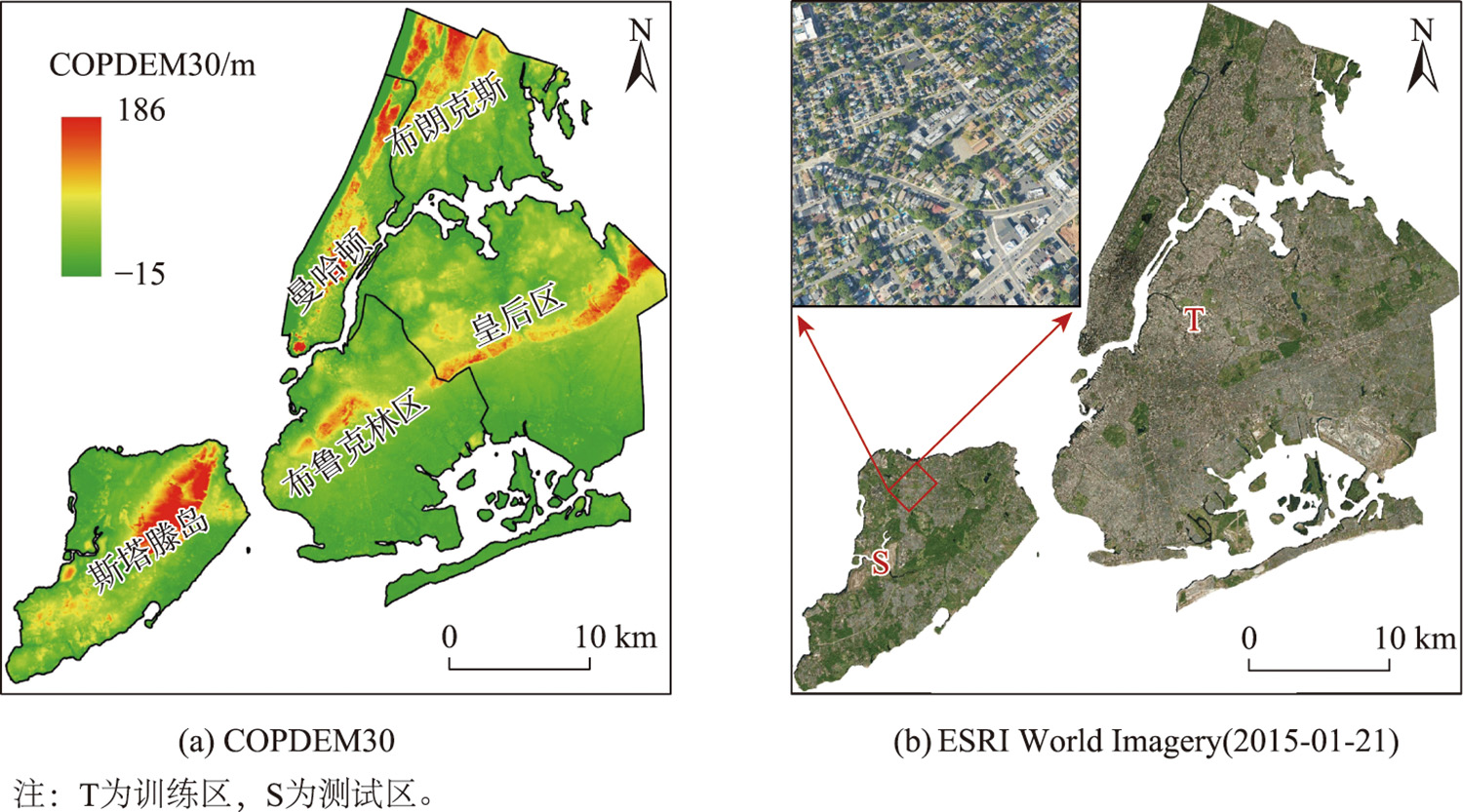
图2 研究区域GDEM及遥感影像
3.2 数据来源
本研究采用的基础数据主要包括:
表1 数据来源与数据类型
| 基础数据 | 数据来源 | 数据类型 | 数据年份 | 分辨率 |
|---|---|---|---|---|
| 机载LiDAR | NOAA海岸管理办公室 | 矢量 | 2014 | - |
| COPDEM30 | Opentopography网站 | 栅格 | 2010-2015 | 30m |
| Sentinel-2A MSI | 欧洲航天局 | 栅格 | 2015 | 10m、20m |
| 建筑物数据 | 纽约公共数据网站 | 矢量 | 2016 | - |
| WorldPOP | 佛罗里达大学提供 | 栅格 | 2015100m | |
| 夜间灯光 | 美国国家地球物理数据中心 | 栅格 | 2015 | 500m |
4. 实验结果与分析
4.1 GMM聚类与空间分区
为了得到最佳聚类个数,选取DBI作为评价指标。表3显示了训练区和测试区不同聚类数目下的DBI值。可以看出,当训练区和测试区聚类数分别为3和2时,DBI值最小,此时聚类效果最优。
表32 不同聚类数目下的DBI值
| 指标 | 研究区 | 聚类数目/个 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DBI | T | 3.224 | 2.524 | 2.882 | 2.930 | 3.357 | 3.818 | 3.791 | 3.907 | 4.018 | |
| S | 2.021 | 2.851 | 2.559 | 3.435 | 2.910 | 2.946 | 4.269 | 3.691 | 3.550 |
因此,本文使用GMM和泰森多边形将训练区分为3个子区,包括高层类建筑区、中层密集型建筑区和低层密集型建筑区;同时,将测试区分为2个子区,包括中低层密集型建筑区和低层类建筑区。
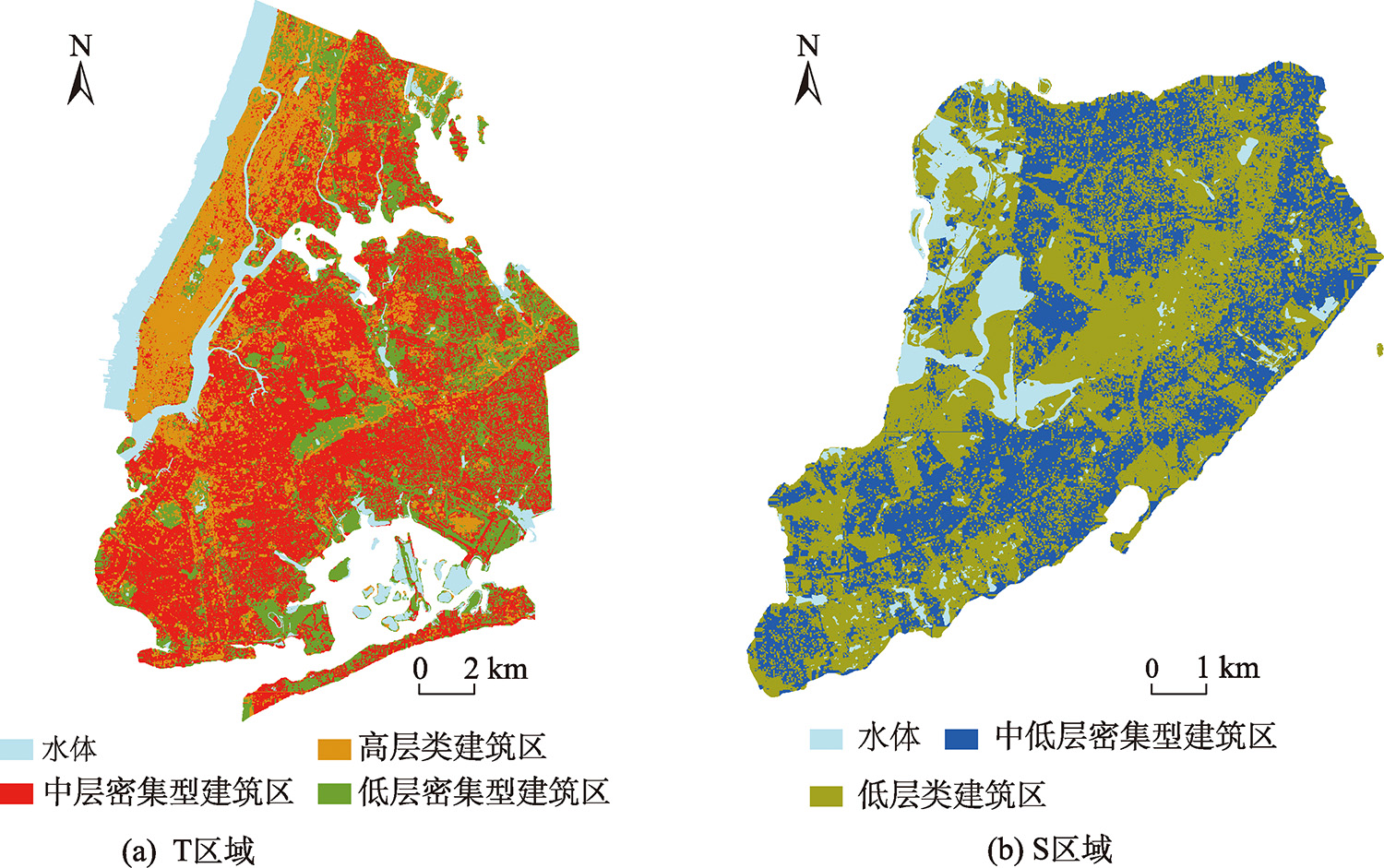
图3 空间分区结果
4.2 特征影响分析与筛选
图4显示了训练区特征变量根据重要性(SHAP值的平均绝对值)从高到低的排序结果。SHAP值为正代表影响因素对模型产生正向影响。
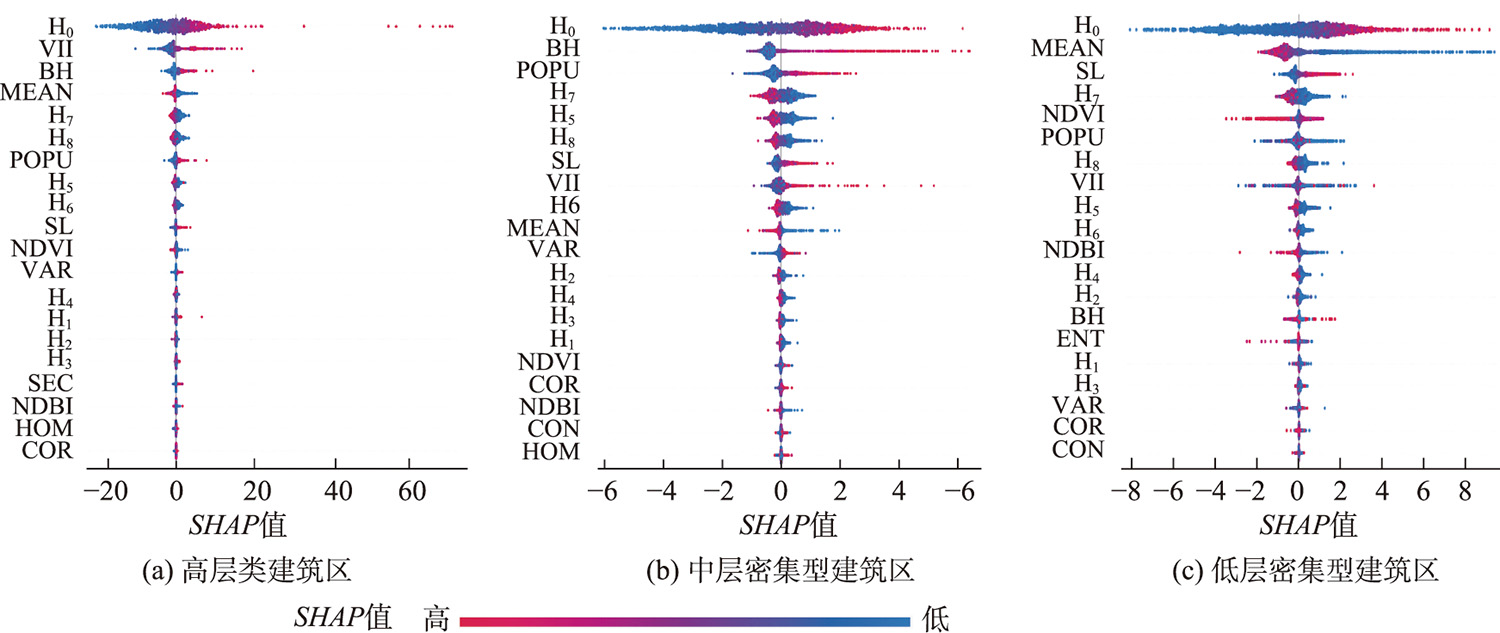
图4 训练区SHAP特征分析
从图中可以看出:
- 高层类建筑区具有显著影响的前5个特征为H₀、VII、BH、MEAN、H₇,表明该区域误差受建筑物影响明显
- 中层密集型建筑区除了H₀、BH、POPU、H₇外,SL排名也靠前,说明该区域同时受到建筑物和地形因素的影响
- 低层密集型建筑物区则明显不同,对其影响最大的5个因素是H₀、MEAN、SL、H₇、NDVI,表明该区域误差主要是受地形和植被因素影响
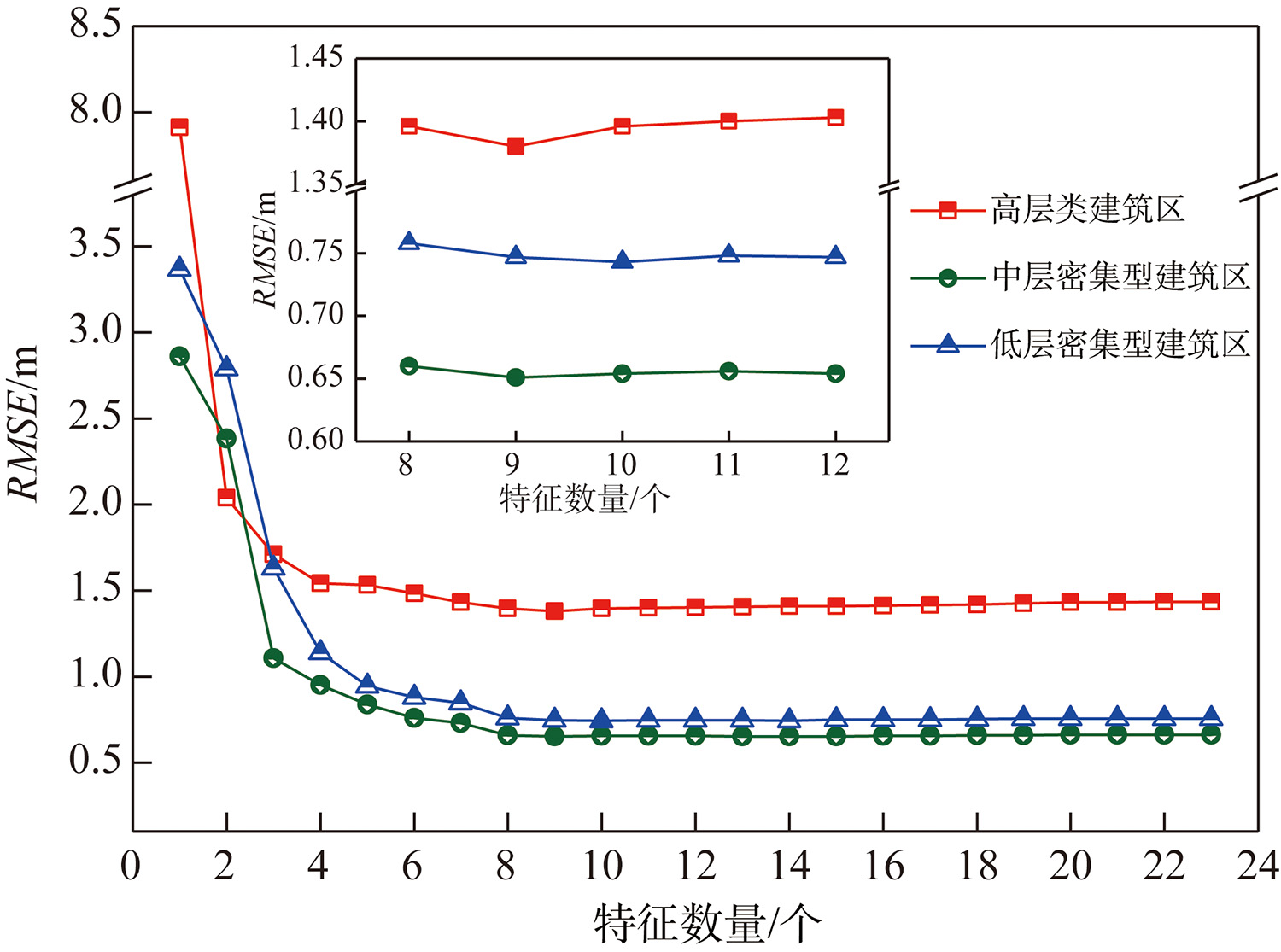
图5 训练区特征数量与模型精度关系
图5为不同特征组合下的模型预测精度。可以看出,特征数由1增加到23时,曲线出现了明显转折,RMSE显著下降。最终确定各子区的最优特征子集如下:
高层类建筑区最优特征子集:
H₀、VII、BH、MEAN、H₇、H₈、POPU、H₅、H₆
中层密集型建筑区最优特征子集:
H₀、BH、POPU、H₇、H₅、H₈、SL、VII、H₆
低层密集型建筑区最优特征子集:
H₀、MEAN、SL、H₇、NDVI、POPU、H₈、VII、H₅、H₆
5. 结论与讨论
5.1 结论
为提高城区GDEM产品精度,本文提出了一种顾及空间异质性和SHAP特征筛选的城区GDEM修正方法。将本文方法用于纽约市COPDEM30修正,并与传统方法比较表明:
- 不同子区内特征变量重要性排序各不相同,即特征变量与GDEM误差的关系表现出明显的空间异质性。
- 相较于SH-RF、FS-RF和RF,本文方法的MAE至少降低了14.8%,RMSE至少降低了13.2%。相较于FABDEM,本文方法的MAE和RMSE分别降低42.3%和63.2%。
- 本文方法应用于测试区后,COPDEM30精度得到有效提升。修正后COPDEM30的ME集中在0m附近,MAE降低了50.5%,RMSE降低了50.4%,说明该方法具有一定的泛化能力。
5.2 讨论
本文提出的方法有效提高了城区GDEM精度,但仍存在以下局限性:
- 大数量训练样本不仅会导致机器学习模型训练耗时而且其中低价值的样本甚至会对模型产生干扰。如何识别并选择高价值样本的学习策略对模型进行优化是日后需要解决的关键技术问题。
- 建筑物高度与密度是导致城区GDEM误差的主要因素,本文使用的建筑高度数据在时间尺度上与GDEM并不一致。如能获得与GDEM时间尺度一致的特征因子,可进一步提升修正效果。
- 本文基于SHAP特征重要性排序进行特征筛选,而高度相关的特征其SHAP值可能会受到多重共线性的影响,在后续工作中将进一步探究。
* 以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。