2 案例相似性度量模型构建
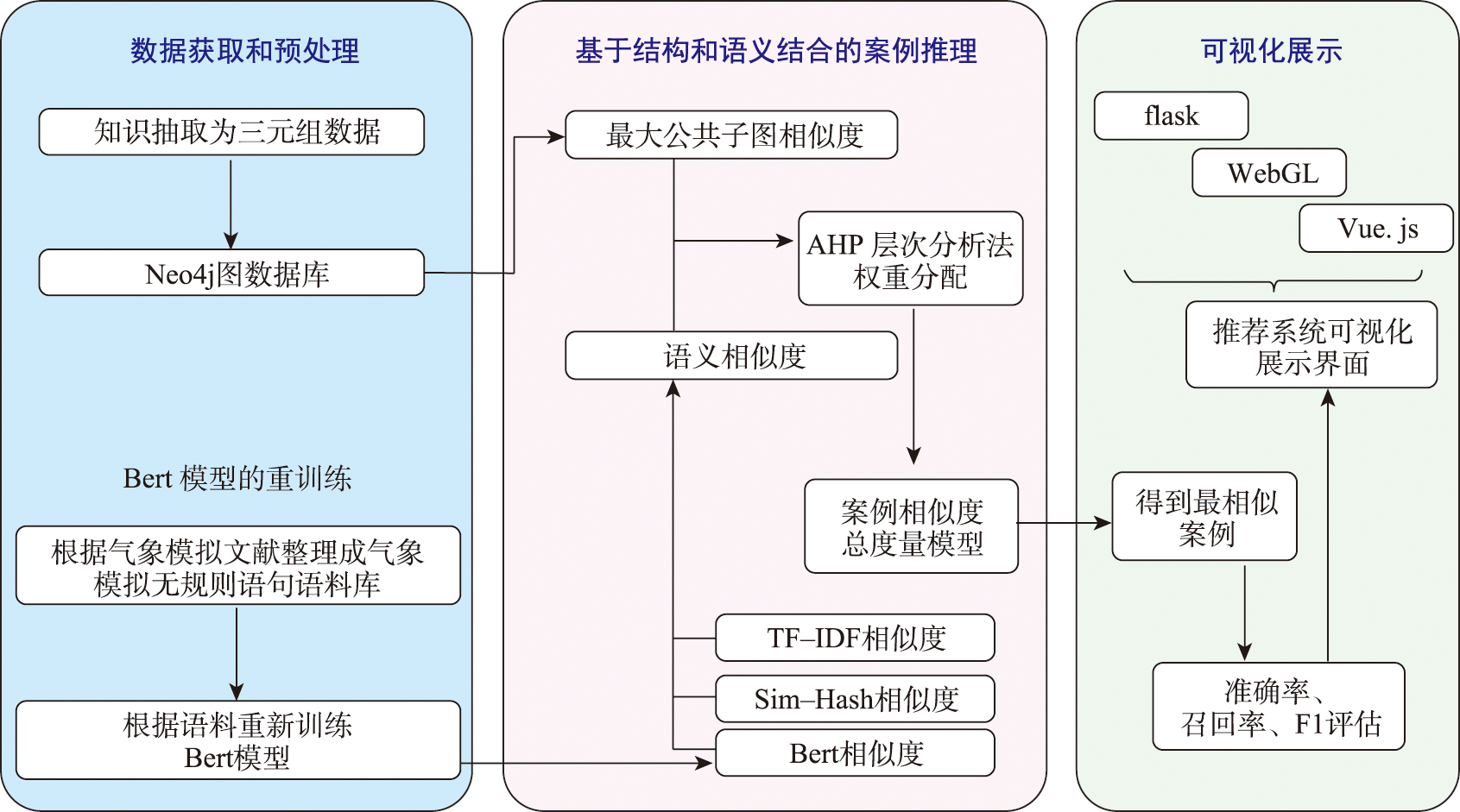
本文核心在于建立一个适于衡量气象模拟知识案例相似度的方法,并以此为基础构建气象模拟案例相似度模型以实现模拟知识的推荐。构建案例相似性度量模型的技术路线如图1所示。
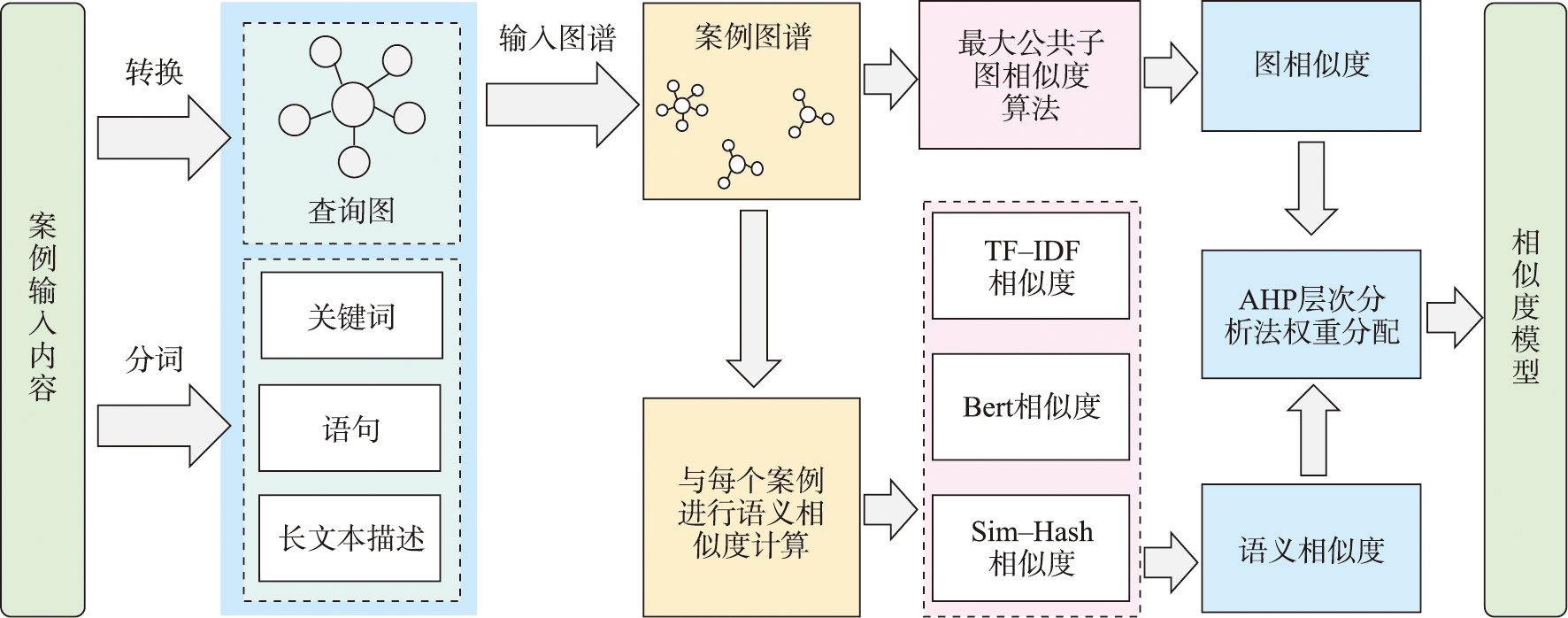
图1 案例相似性度量模型
2.1 案例相似性度量方法
在知识图谱案例库中每个案例都表示为一个图,其节点表示案例的名称、属性。节点之间的边表示节点之间的关系。因此综合考虑把案例相似度分为基于知识图谱结构相似度和基于案例本身的属性特征的语义相似度。
2.1.1 语义相似度度量方法
地理语义是指用于描述地理现象中的数据所对应的现实世界中事物之间的概念、含义和相互关系。借鉴路网层次化语义相似性度量模型,为了能对案例语义特征进行多维度的提取,本研究案例推荐的语义相似度由Bert语义相似度、TF-IDF相似度、Sim Hash相似度3种相似度组成。
Bert语义相似度
利用Bert预训练模型根据专业语料库再训练,将自然语句的语义信息用向量表示,用于相似度计算。
TF-IDF相似度
统计方法,结合词频(TF)和逆文本频率指数(IDF)来衡量文本相似度。
Sim Hash相似度
把文本数据映射成固定长度的二进制编码,用于文档间相似度计算,常用于文档去重或文本分类。
2.1.2 结构相似性度量方法
针对传统案例推理过程中对案例结构特征的忽视,本研究用知识图谱来存储气象模拟知识案例。一方面可以直观展示案例属性之间的关联,另一方面可以挖掘案例的结构特征。因此,本文在图数据库中利用案例结构特征进行最大公共子图的图匹配。
2.2 耦合语义和结构相似性的度量方法
气象模拟知识案例相似性度量模型由基于知识图谱的结构相似度和基于案例属性特征的语义相似度组成。式(9)为相似度公式,Sim(P,Q)来表示案例P和Q的相似度。Sim(P,Q)∈[0,1],该值越趋近于1代表2个案例越相似,越趋近于0代表2个案例越不相似。
Sim(P,Q) = αSimatt(P,Q) + (1-α)Simrel(P,Q)
Simatt(P,Q)表示语义相似度,Simrel(P,Q)表示结构相似度,α和(1-α)表示分别基于二者的权重。