研究背景
地图是按一定的数学法则将图形、符号相结合以表达人类所认识的自然与人文环境的一种记录方式。自媒体时代的快速发展赋予了地图新的维度,即普通大众希望从用图者的角色向制图者转变。
为满足这一需求,闫浩文提出了面向自媒体的微地图——一种"草根"地图,允许用户随时随地参与地图制作,实现快速、灵活、多变、低门槛的交互传播与应用。微地图的特点在于其对通用地图符号的强烈需求,即对那些不受传统规范束缚、更具创造性和个性化符号表达的需求。
手绘地图特点
- 独特的艺术性和个性化表达
- 超越传统地图符号的规范限制
- 展现对地理特征和地方的独特认知
现有问题
- 微地图基础数据库不够完善
- 现有符号提取技术主要面向历史地图
- 手绘地图符号更具个人特色和不规则性
研究方法
本文将手绘地图集作为符号提取的数据源,使用目标检测中的YOLOv5模型用于点符号提取,将获取到的点符号用于扩充微地图点符号库,最终为微地图下游任务提供数据基础以及为微地图用户提供多样且个性的点符号。
技术路线图
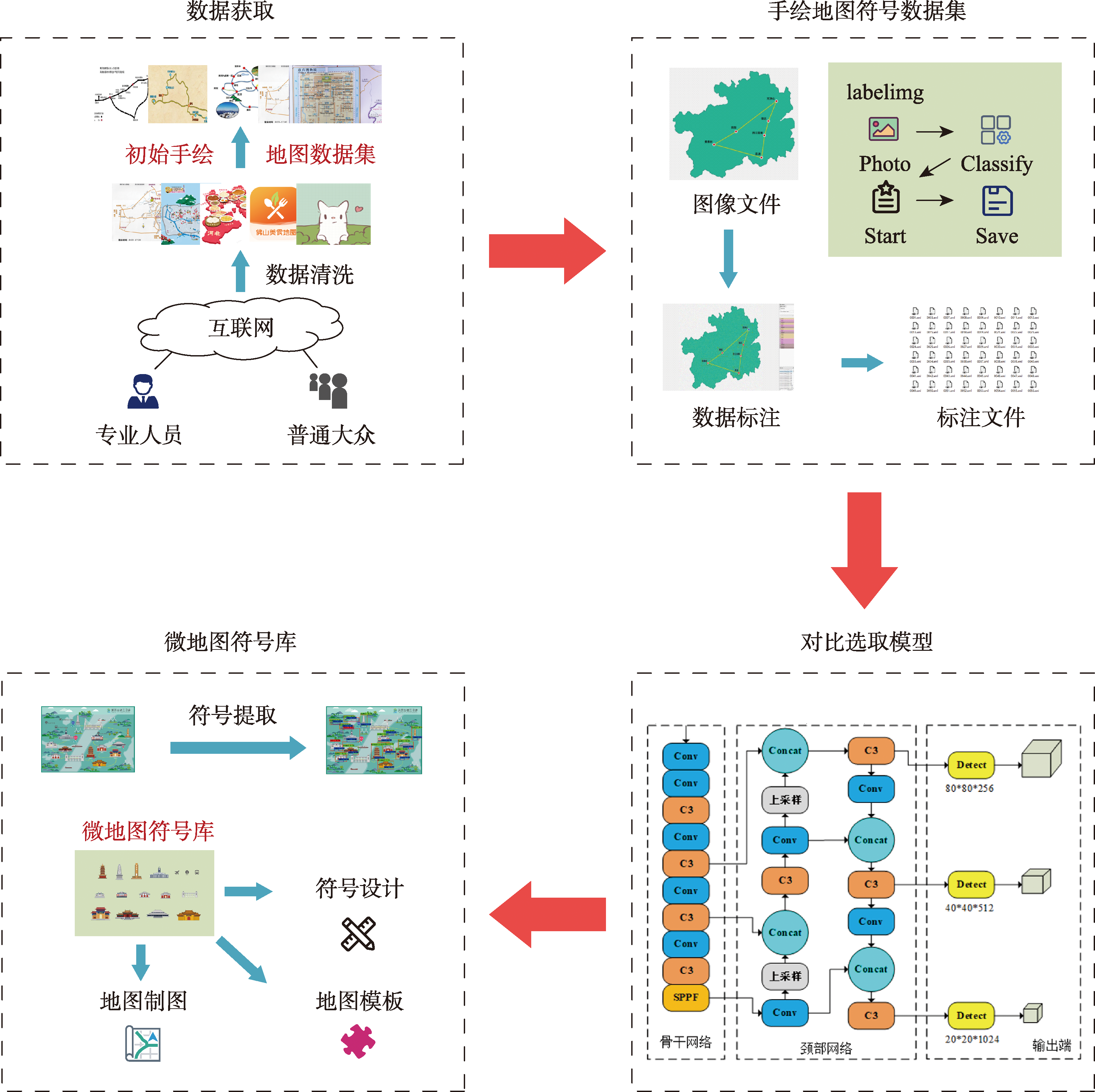
图1 符号提取技术路线
手绘地图数据集
在微地图符号提取研究中,数据集的构建至关重要。本研究选择从互联网上获取手绘地图作为实验所需的数据集,以确保数据的多样性和丰富性,涵盖不同地域、风格和内容。
数据集分类
| 地图分类 | 地图数量/张 | 分类示例 |
|---|---|---|
| Area | 117 | 面状要素为主 |
| Hand_2D | 1002 | 二维手绘符号 |
| Hand_25D | 266 | 2.5维手绘符号 |
| Standard | 618 | 标准地图符号 |
数据标注
每张图片按照人工判读的形式共标注了point、symbol和label3个类别:
- point类:符号的整体信息
- symbol类:符号本身
- label类:符号的标注信息
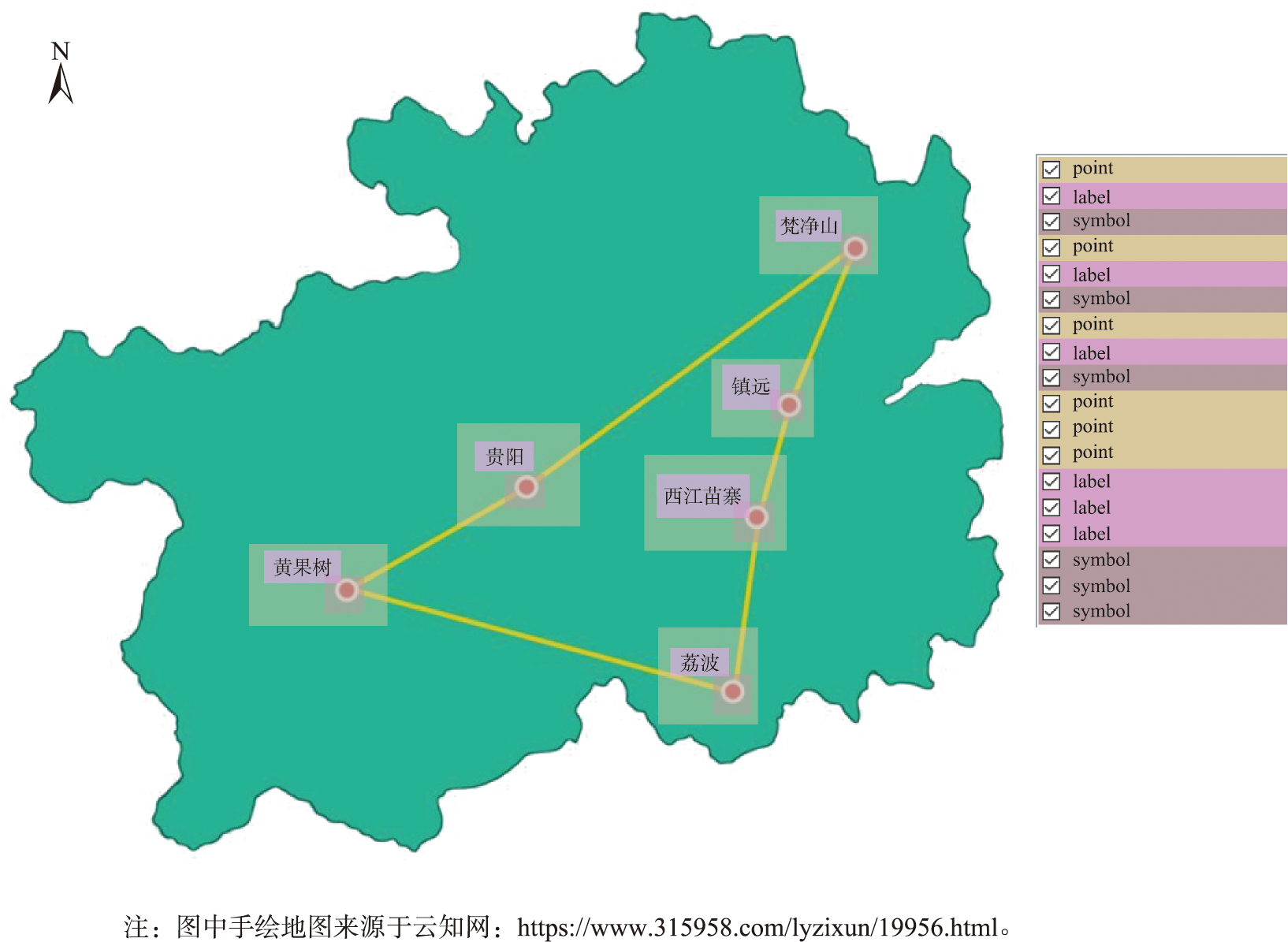
图2 数据标注示例
符号提取模型
YOLO模型作为单阶段目标检测器,以其卓越的目标检测性能而闻名。这些模型采用了卷积神经网络等深度学习技术,可以自主学习图像特征,无需手动提取。它们的端到端架构能够学习复杂的特征来表示图像,从而提高了地图要素的自动识别效率。
| 模型 | AP/% | params/M | FLOPs@640/B |
|---|---|---|---|
| YOLOv5-n | 28.0 | 1.9 | 4.5 |
| YOLOv5-s | 37.4 | 7.2 | 16.5 |
| YOLOv5-m | 45.4 | 21.2 | 49 |
| YOLOv5-l | 49.0 | 46.5 | 109.1 |
| YOLOv5-x | 50.7 | 86.7 | 205.7 |
| YOLOv8-n | 37.2 | 3.2 | 8.7 |
| YOLOv8-s | 44.9 | 11.2 | 28.6 |
| YOLOv8-m | 50.2 | 25.9 | 78.9 |
| YOLOv8-l | 52.9 | 43.7 | 165.2 |
| YOLOv8-x | 53.9 | 68.2 | 257.8 |
模型选择
通过AP(Average precision)、精确度、召回率、F1分数评估指标来评估模型的性能。训练样本用于训练YOLOv5模型,验证样本用于确定训练后的模型是否符合要求。
YOLOv5各个模型的损失函数均在迭代次数为70次左右时突然下降,且在整个训练过程中振荡,这是由于本次实验采用了Adam优化函数,该函数在训练过程中自适应调整学习率,当学习率满足一定的阈值时,其会下降直至趋近于0,以获取更好的模型识别效果。由表3可知,YOLOv5-X模型在准确率,召回率和F1得分中均有好的表现,故最终采用YOLOv5-X模型训练数据。
实验与分析
3.1 实验环境及模型参数
为确保实验的有效进行,本研究采用了一台配置高性能GPU的服务器,搭载NVIDIA A100 80G GPU,以提高YOLOv5模型的训练和推理效率。在软件环境方面,选择了PyTorch 2.0.1框架作为YOLOv5模型的深度学习框架。
硬件配置
- GPU: NVIDIA A100 80G
- 内存: 256GB DDR4
软件配置
- PyTorch 2.0.1
- Python 3.8
模型参数设置
-
输入尺寸: 640像素×640像素
-
学习率: 0.001
-
迭代次数: 100次
-
批尺寸: 16
-
优化算法: Adam
-
Momentum: 0.937
3.2 模型训练可视化
本文使用类别热力图(Class Activation Mapping,CAM)来解释YOLOv5-X模型在手绘地图通用地图符号提取中的预测过程。CAM热力图突出输入图像中影响输出类别的像素,从而帮助理解模型是如何识别和定位地图中点符号的过程。
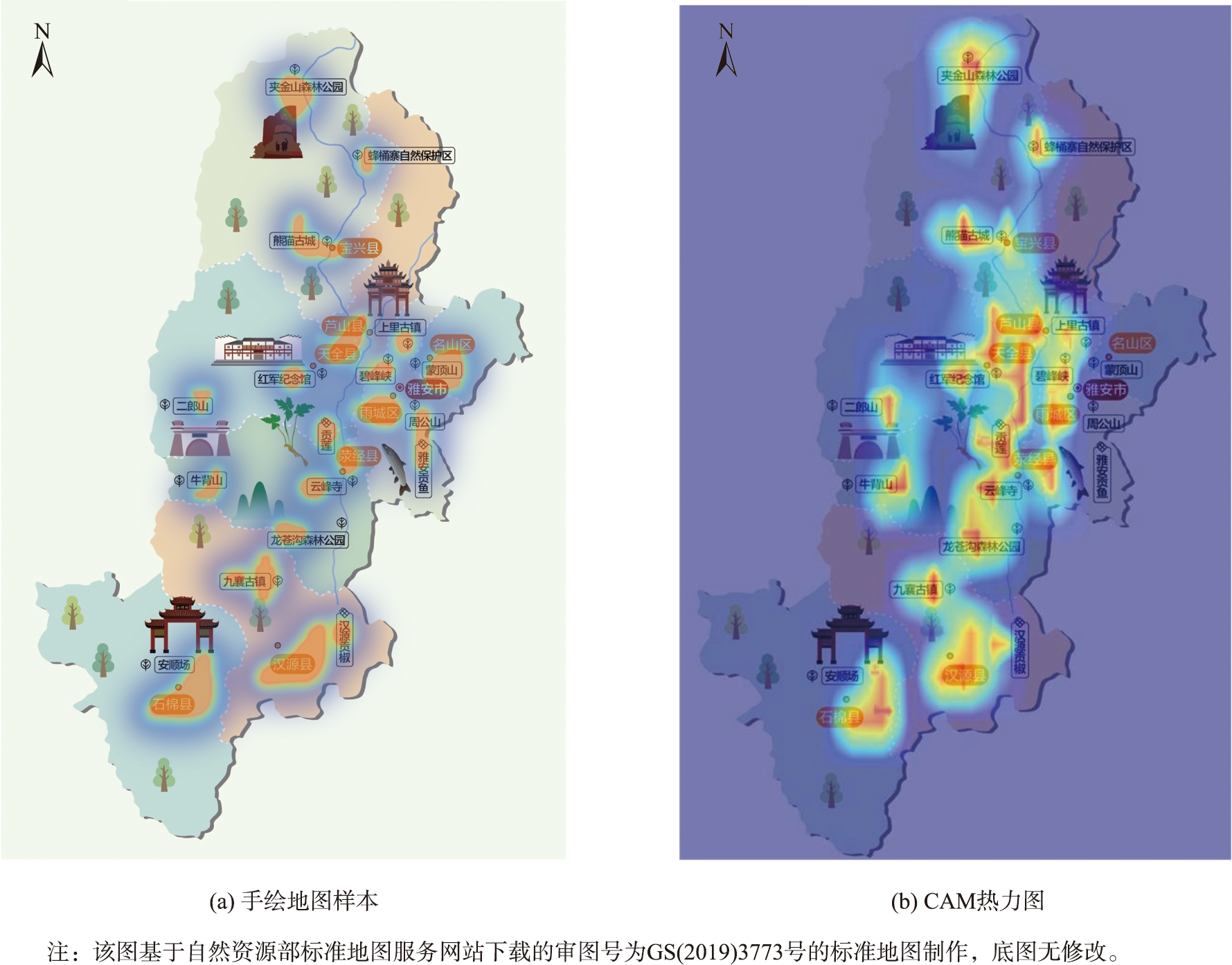
图3 CAM热力图示例
图3(a)为原始的手绘地图样本,图3(b)展示了相应的CAM热力图,其中热力图的颜色深浅表示模型关注区域的强度。从图3(b)可以观察到,模型在预测不同符号时,主要关注了符号的中心区域和边缘轮廓,这表明模型能够有效地捕捉到符号的关键特征。
3.3 模型泛化能力验证
Quick Draw数据集作为目前全球最大的涂鸦数据集,与本研究所构建的微地图点符号库有许多相似之处。二者作为手绘图标,不仅都具有艺术性和独特表达,而且都受到个体创作者的影响,呈现出多样性和个性化。
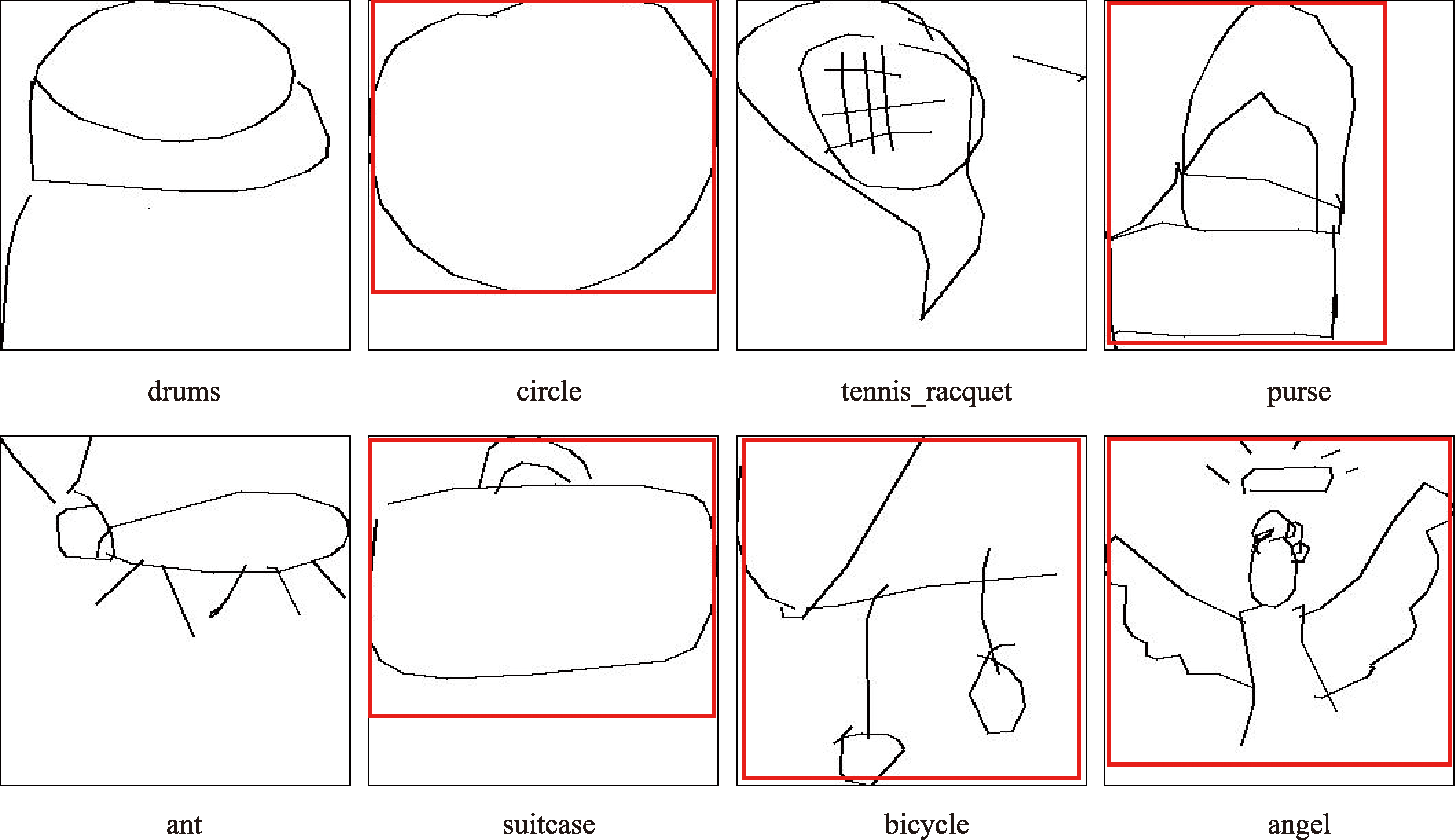
图4 Quick Draw数据集符号提取效果
本次选取的Quick Draw数据集所有类别的数据量总计3450张,成功识别的共有1439张,识别成功率为41.71%,在此基础上进一步选取了识别效果良好的类别,其中部分类别在本模型上识别效果出色,如cake、cow、toaster、zebra等类别。
3.4 对比实验
为了验证模型的有效性,本文使用手绘地图自建数据集中point类别训练深度学习领域中常见的主流检测模型,并记录相应的实验结果。将这些结果与本文模型进行对比,对比结果如表5所示。
| 模型 | AP | 精确率 | 召回率 | F1 |
|---|---|---|---|---|
| Retinanet | 73.94 | 92.81 | 59.17 | 72 |
| SSD | 68.77 | 92.04 | 36.03 | 52 |
| YOLOv5-X | 97.85 | 98.42 | 94.72 | 97 |
通过对比可知,本文所使用的YOLOv5-X模型对于手绘地图自建数据集的point类别有更高的精度,并且在手绘地图自制数据集符号检测方面表现出更高的针对性。与Retinanet相比,YOLOv5-X模型的检测精度提高了5.61%,相比SSD```html 提高了6.38%。在多种不同模型的算法对比中表现出了一定的优越性。总体而言,本文所采用的方案具备相当的优越性。
3.5 符号提取结果
本研究所使用的方法利用图像处理和机器学习技术,从手绘地图中分离出通用地图符号。通过这些技术,本研究能够更好地满足用户的个性化需求,使地图符号的设计和应用变得更加灵活和便捷。
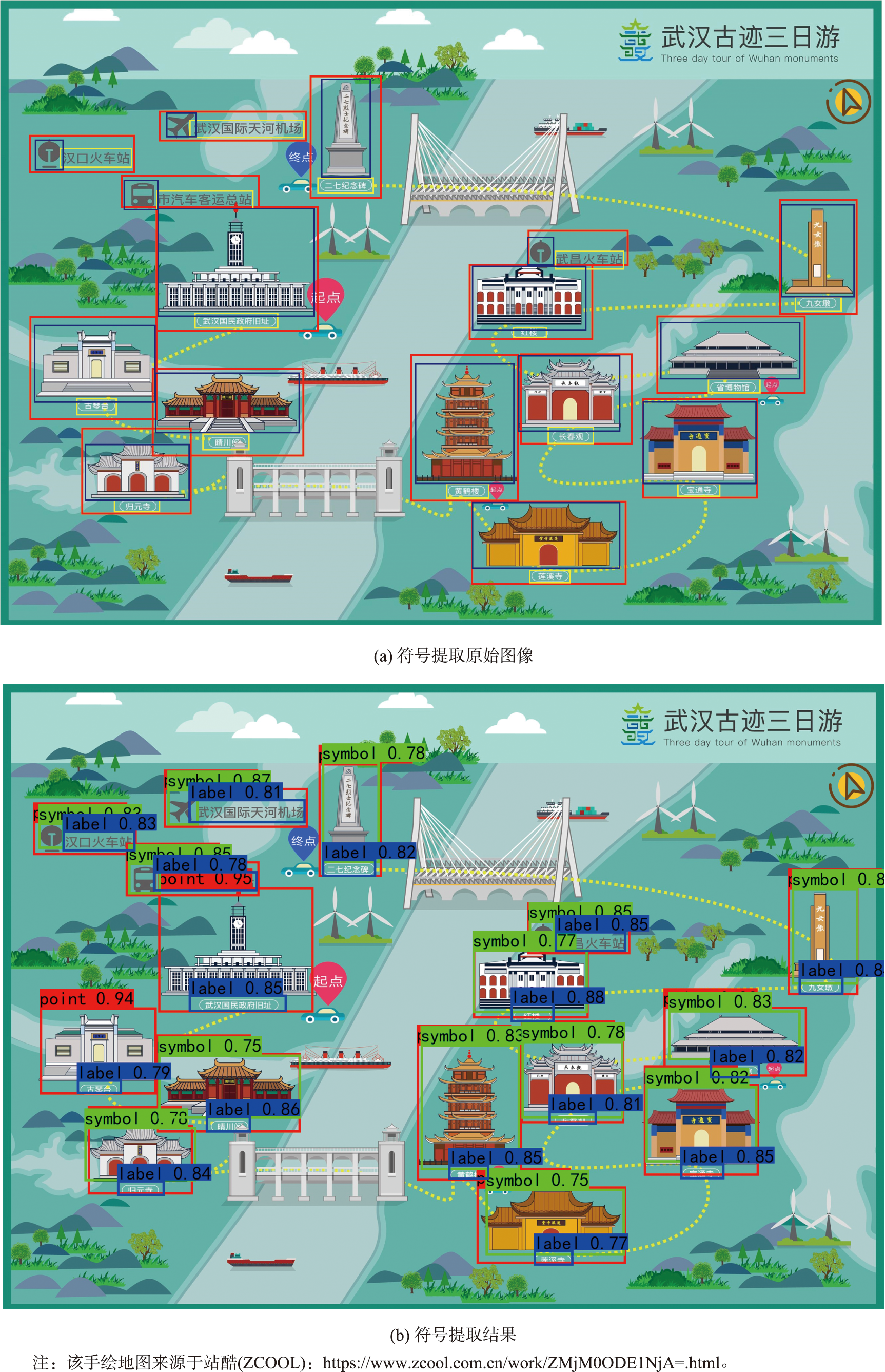
图5 符号提取效果
图5(a)中显示了原始微地图样本,为来自互联网的未经过模型训练的手绘地图,图5(b)中展示了模型提取符号的效果。该示意图很好地呈现了本研究进行符号提取的效果。
结论与展望
本文利用目标检测技术成功实现了手绘地图通用地图符号的自动提取。该方法克服了手绘地图中通用地图符号的复杂性和个性化导致的提取困难,进而提高了微地图制图的效率并扩展了微地图点符号库。
主要贡献
- 构建了包含多种类型和样式的手绘地图数据集
- 采用YOLOv5-X模型进行符号提取,精确度达98.42%
- 验证了模型在Quick Draw数据集上的泛化能力
- 为微地图制图提供了灵活和个性化的解决方案
未来工作
- 扩充数据集样本,提高符号提取精度
- 扩展到对点符号详细信息的提取
- 研究线、面符号的自动提取方法
- 优化模型架构,提高处理效率
尽管本文取得了初步成果,但由于数据集样本的有限,符号提取仍存在一定的局限性。未来将致力于提升提取算法的精度,并将研究扩展到对点符号详细信息的提取,以及线、面符号的获取等方面。这将有助于推动微地图制图领域的发展,使更多人能够参与并受益于微地图的制作和使用。