研究方法
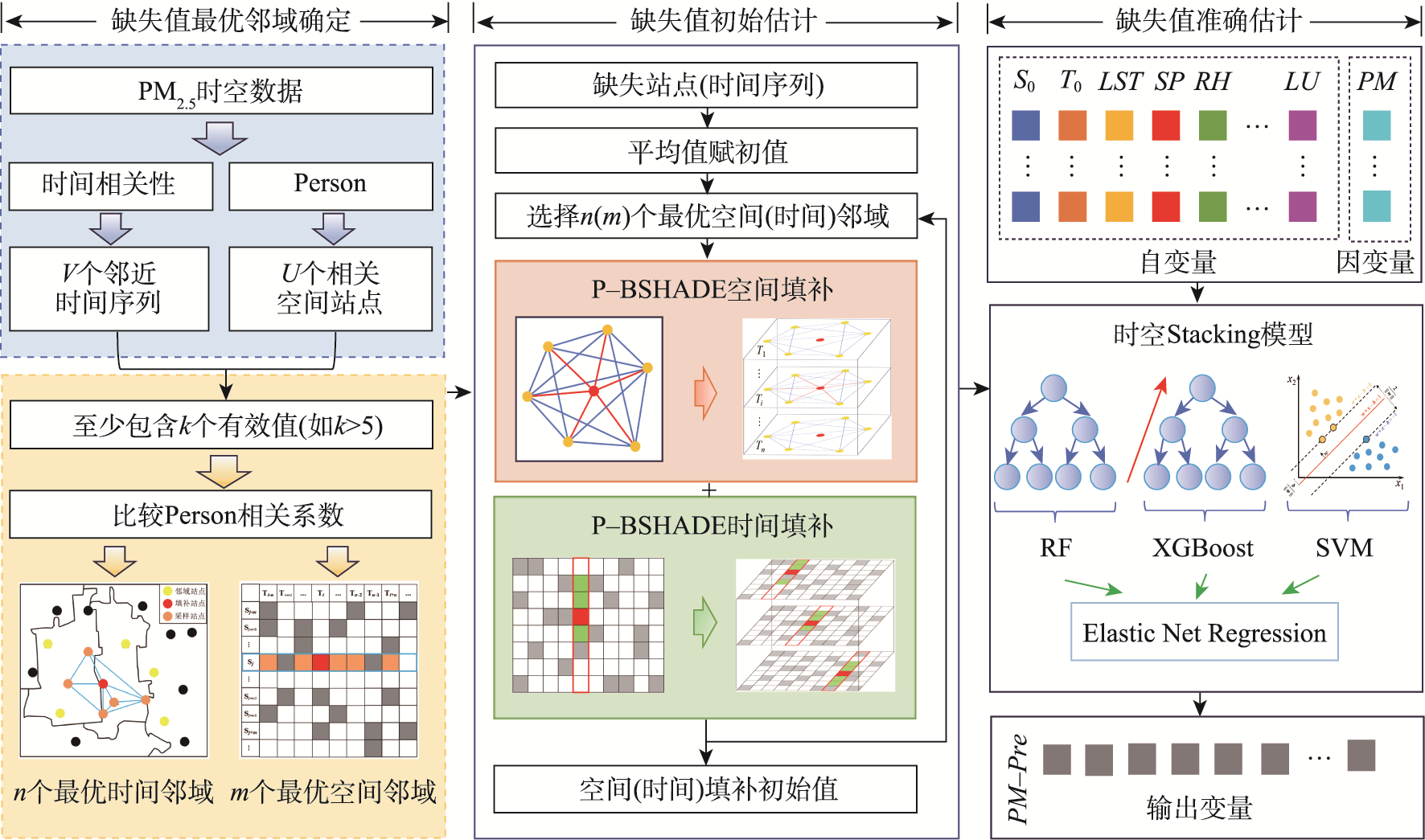
图1 顾及日周期性的PM2.5缺失值重构方法流程
缺失值最优邻域确定
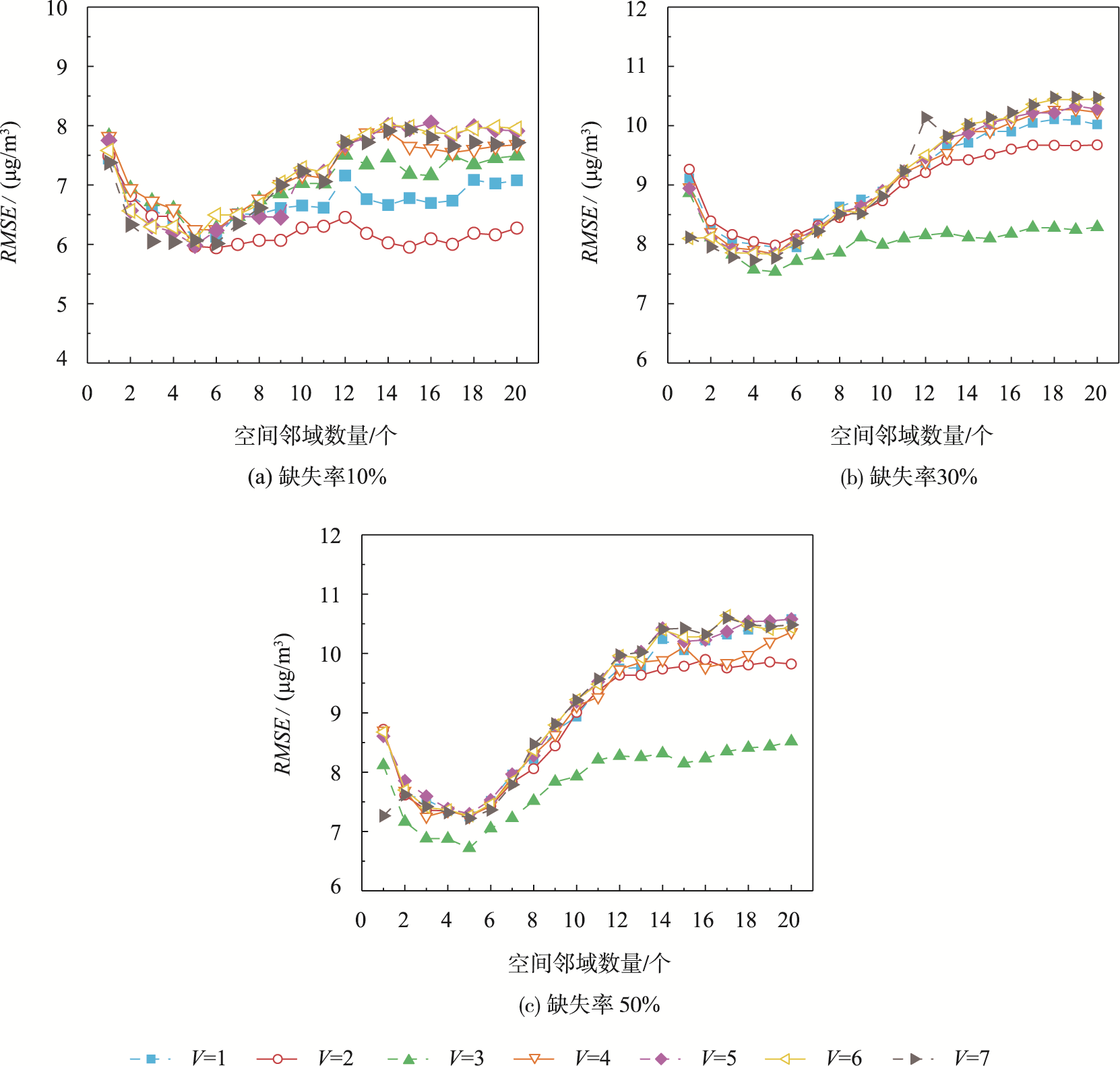
以日周期为处理单元,在空间维度上选择U个相关性最大的站点作为空间邻域,在时间维度上选择缺失位置前后V个时间间隔作为时间邻域。
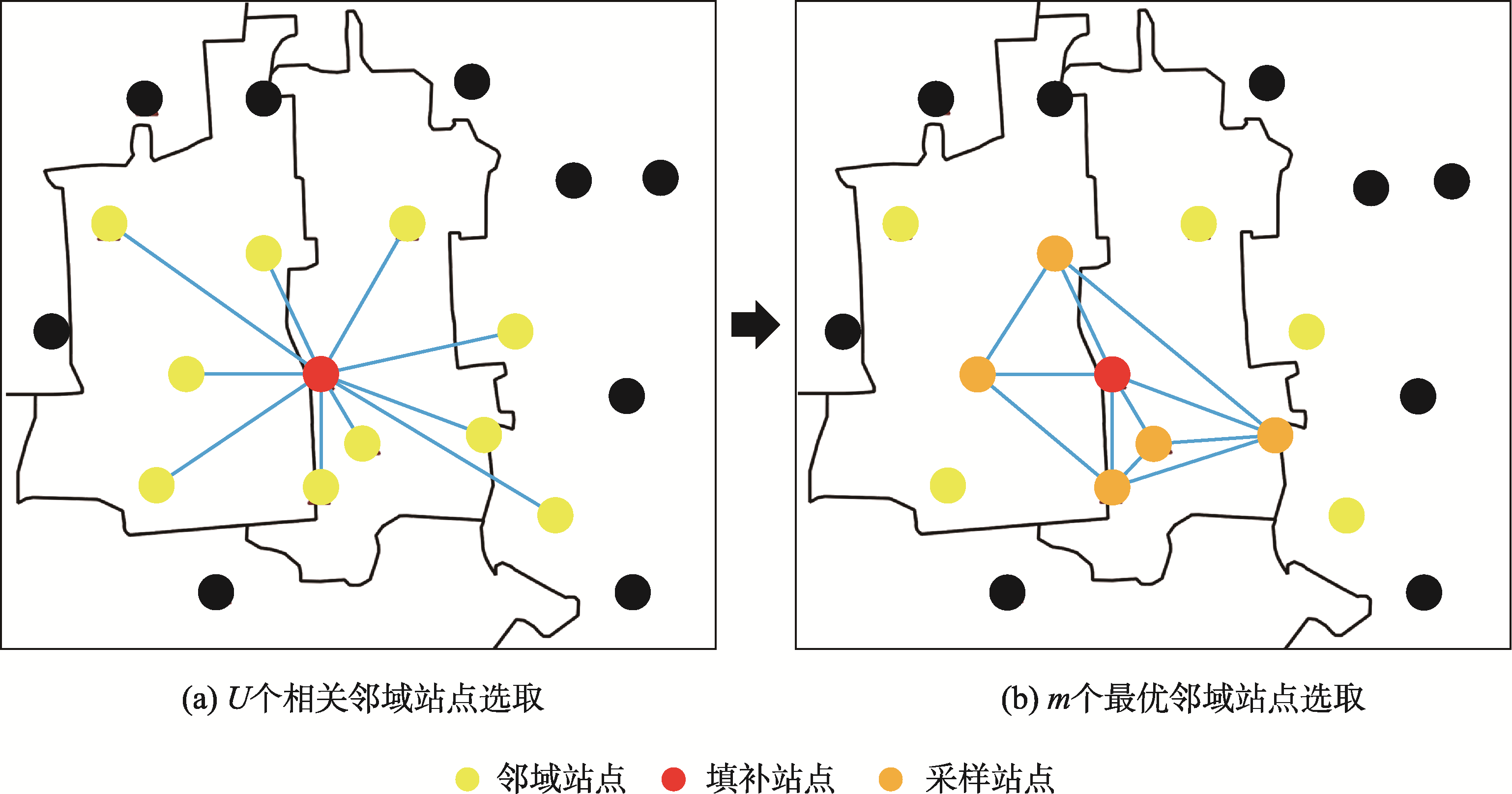
图2 缺失值空间最优邻域确定
缺失值初始估计
利用P-BSHADE方法在时间和空间2个维度上重构缺失值,以迭代方式进行空间和时间维度的初始填补,充分顾及时空自相关和时空异质性。
空间维度计算过程:
- 计算空间站点关系
- 求解空间权重
- 计算初始估计结果
缺失值准确填补
在上述时空填补初始值的基础上引入PM2.5影响因子构建Stacking集成学习模型,选择RF、SVM和XGBoost作为基学习器,逻辑回归作为元学习器。
随机森林
SVM
XGBoost
方法步骤详解
1. 缺失值最优邻域确定
在空间维度上,从U个初始邻域中选取每天至少包含k个有效值的m个相关性最大的站点作为最优邻域;在时间维度上,选择n个相关性最大且至少包含k个有效值的时间序列作为最优邻域。
2. 缺失值初始估计
对含有缺失值的站点,以该站点缺失值当天的已知观测值的平均值作为其初值;利用P-BSHADE方法对该天站点的PM2.5缺失值进行估算;重复直至所有站点所有天缺失值估算完毕。
3. 缺失值准确填补
将最优时空邻域中全部未缺失位置的空间和时空初始值、PM2.5相关影响因子作为自变量,对应的PM2.5观测值作为因变量输入到Stacking集成模型进行训练;将待计算站点缺失值时刻的空间初始估计值、时间初始估计值、PM2.5相关影响因子作为自变量输入到训练好的Stacking集成模型中,获得最终填补值。