1 引言
产业集聚理论可以追溯到马歇尔(Marshall)在1890年对产业区的论述。之后,韦伯(Webber)1909年创立的工业区位理论首次提出集聚经济的概念,揭示了工业企业在特定地域的集中分布现象及由此产生的正向经济效应。在单一产业集聚的理论基础上,随着产业关联、产业分工等理论的发展,两个或多个产业在同一特定区域内的地理集中现象被称为产业协同集聚,由Ellison和Glaeser于1997年首次关注和测度,产业协同集聚也逐渐成为集聚经济研究的一部分。
20世纪90年代,克鲁格曼(Krugman)的新经济地理学将空间要素纳入主流经济学的研究范畴,空间数据统计分析方法也被引入经济学研究中。以地理邻近为基本特征的集聚经济成为重要的研究对象并逐渐成为经济地理学与GIS的交叉研究领域。
基于以上背景,本文根据2008年和2018年经济普查数据,清洗企业级大数据后,采用DO指数测度京津冀协同发展战略提出前后制造业协同集聚的强度、尺度及其动态演化。本文的创新性主要体现在:
- 利用全国经济普查企业数据,采用多距离空间聚类分析方法测度产业协同集聚,提升了协同集聚模式挖掘的精度与可靠性;
- 弥补了国内应用DO指数对产业协同集聚实证研究的相对不足,丰富了集聚经济的研究内容;
- 研究结果揭示了京津冀地区制造业协同集聚的强度和尺度,以及在2008年和2018年的变化情况,可以为优化和调控京津冀地区制造业疏解与承接、推动地区协同发展提供科学依据。
2 研究方法与数据来源
点模式分析方法主要有2大类,分别是基于密度的点分析和基于距离的点分析,前者是根据选定区域中点的密度或频率分布的各种特征来研究点的空间模式,一般用来研究单一产业的集聚特征;后者是通过测度最近邻点的距离分析兴趣点空间分布模式的方法。Ripley's K函数方法确定要素(或与要素相关联的值)在某一距离范围内统计意义显著时的空间分布模式,属于基于距离的点分析。它最初由Arbia和Espa于1996年在经济文献中引入,DO指数在其基础上发展而来,主要区别有:
- K函数基于完全随机假设,DO指数则考虑了企业由于自然屏障、政治限制等因素无法完全随机分布的情况;
- K函数将企业点视为完全一致大小的,而DO指数增加了企业规模的控制,因此DO指数较K函数更适合在经济学领域中应用。

图1 基于DO指数测度制造业协同集聚的技术路线
2.1 研究方法
多距离空间聚类分析是以距离为依据,判断实际情况与随机分布的差异来识别兴趣点分布模式。DO指数继承了这一核心思想,通过建立反事实实验,即获得随机抽样下的某一行业中企业样本双边距离(Bilateral Distance),通过将真实企业之间的双边距离分布与随机抽样下的分布相比较,判断集聚、分散、随机的分布状态。具体可分为以下4个步骤:
(1)核密度函数估计
考虑到现实世界的复杂性,简单地计算企业点之间的平均欧氏距离可能导致结果被低估。采用核密度函数平滑的方法能够更有效地处理这个问题。假设nA家企业属于A行业,nB家企业属于B行业,则有nA×nB个双边地理距离。任意企业i与企业j的欧式距离为dij,采用高斯核函数f计算密度,带宽h设置参考Silverman,h=1.06×std(dij)×(nA×nB)-1/5。
(2)反事实实验构建
行业A和行业B企业位置信息组成集合A ∪ B,从中随机无放回抽取nA(nB)个数据作为行业A(B)企业空间分布的模拟,并根据式(1)计算核密度值。重复该过程1 000次。
(3)设置局部置信区间带
将每个距离d上的1 000次核密度计算值升序排列,选取5%分位点和95%分位点作为该距离d上置信区间的下限和上限,分别用K(A,B)(d)和K̄(A,B)(d)表示。在95%的置信水平下,当K̂(A,B)(d) > K̄(A,B)(d),认为A行业与B行业在距离d上表现为协同集聚;当K̂(A,B)(d) < K(A,B)(d),则认为表现为协同分散。
γ(A,B)(d)表示局部协同集聚指数
(4)设置全局置信区间带
全局置信区间相对于局部置信区间来说,是对数据的整体约束,根据D&O,如果想要获得全局水平上的5%置信水平,局部需要考虑99%甚至100%分位数。尽管实际全局置信区间带D&O如何设置未曾说明,但我们依然考虑了D&O的假设,并选择99%、1%分位数作为全局置信区间带的上限与下限,这与孟美侠的做法相一致。K̄̄(A,B)(d)和K(A,B)(d)分别表示全局置信区间的上限和下限。若在d0范围内存在一个距离,使得K̂(A,B)(d) > K̄̄(A,B)(d),则认为行业A与行业B是全局协同集聚的。
为了比较不同行业对协同集聚强度的差异,Duranton和Overman定义跨距离指数:每个行业对分别累加所有距离的强度,用于表征行业A与B在0~d0上的协同集聚/分散强度。
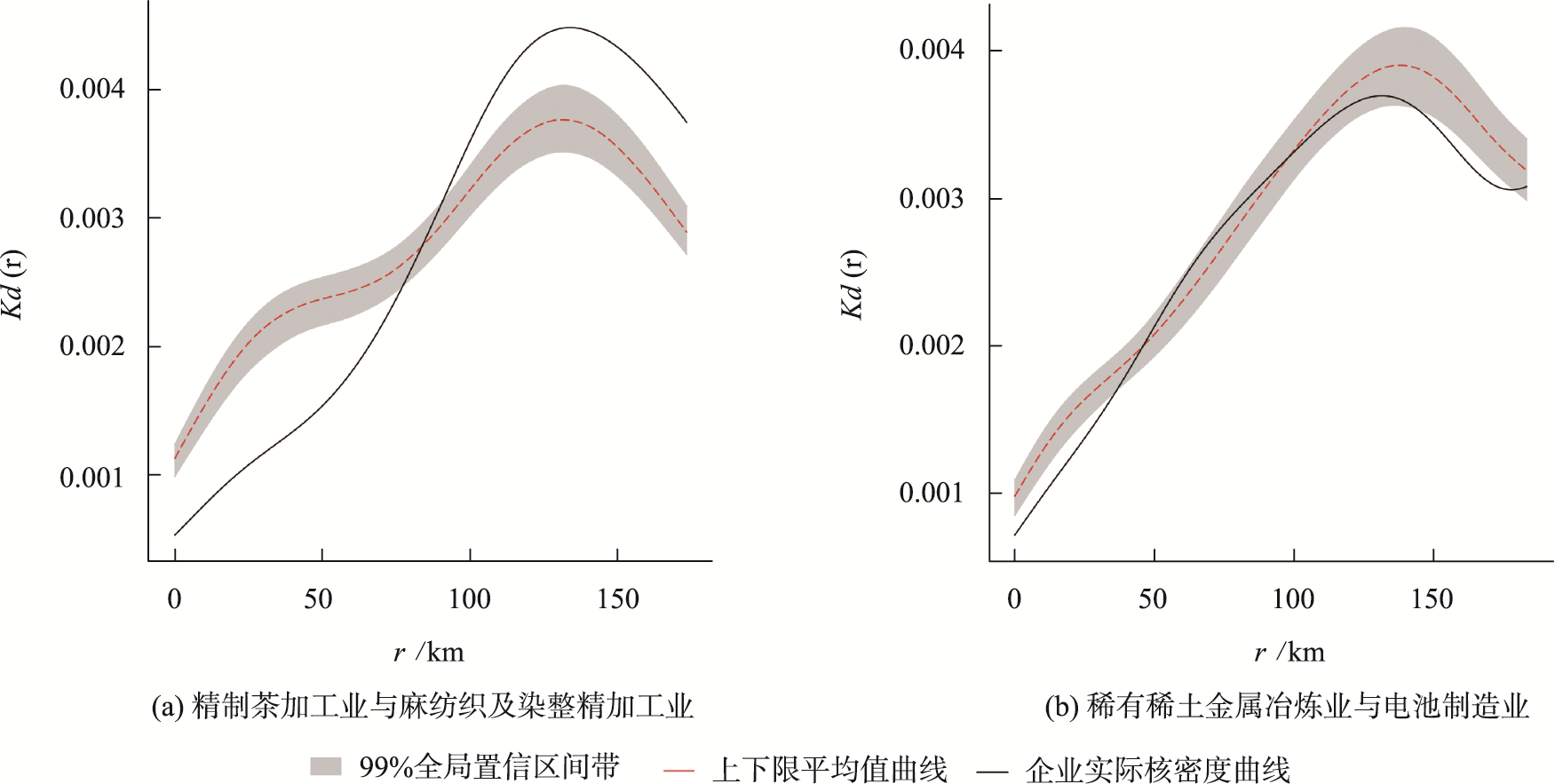
图2 行业对全局协同集聚与全局协同分散示意图
2.2 数据来源与处理
DO指数计算需要企业微观数据,已获取的京津冀地区企业微观数据的属性包括统一社会信用代码、企业名称、行业分类、主营业务、地址信息、经纬度坐标、成立时间、注册资本等。本文研究京津冀地区2008年和2018年的制造业,参考《中国经济普查年鉴》进行数据清洗。
2.3 计算流程
使用R语言,根据式(1)—式(5),依托高性能CPU服务器计算DO指数;使用Python,根据式(6)—式(9),计算跨距离和跨行业指数。
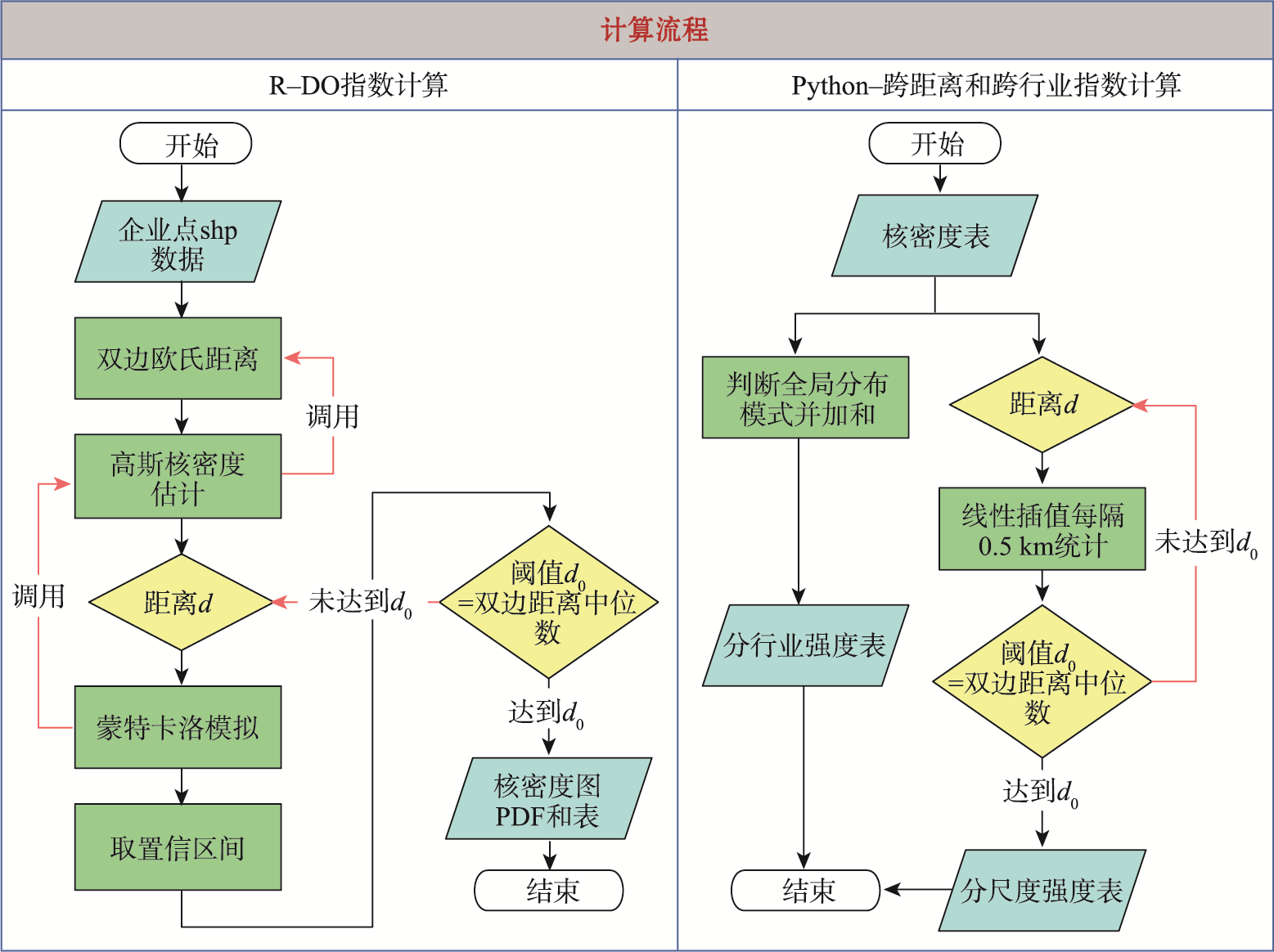
图3 计算流程
3 制造业协同集聚的动态演化特征
DO指数计算结果可根据跨距离和跨行业指数从强度和尺度2个方面进行分析,刻画产业协同集聚特征。本文研究2014年京津冀协同发展战略提出前后产业协同集聚特征的变化,为促进京津冀协同发展的政策调整提供支持,因此基于2008年和2018年2个时间节点研究动态演化过程。
对协同集聚强度进行降序排列得到2008年和2018年协同集聚强度最大的TOP 20行业对(表5)。其中,2008年前3个协同集聚强度最大的行业对分别是文教、工美、体育和娱乐用品制造业与计算机、通信和其他电子设备制造业/仪器仪表制造业/通用设备制造业,与韩清的研究结果一致,尽管后者的研究是基于全国的数据。
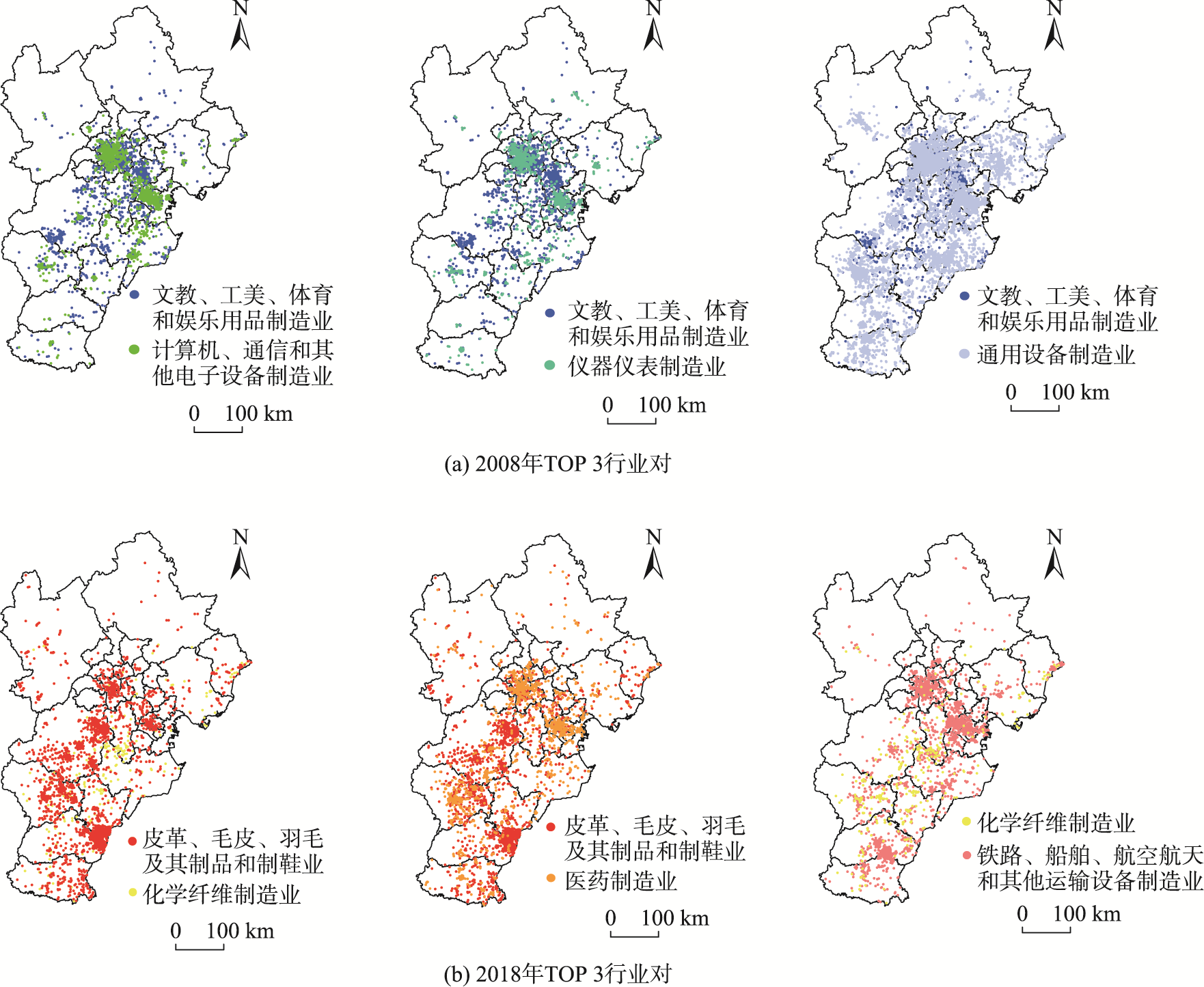
图4 2008年和2018年协同集聚强度值TOP 3行业对企业地理分布
3.2 协同集聚尺度
为了比较不同空间尺度的制造业协同集聚强度差异,每一观测距离d分别累加所有行业对的协同集聚/分散强度,用于表征各空间尺度下制造业的协同集聚/分散强度。根据式(8)和式(9)计算跨行业指数,并基于全部行业对和强度TOP 20行业对,从整体和局部2个方面进行分析。
3.2.1 全部行业对
2008年京津冀制造业协同集聚强度在0~25 km附近,属于协同集聚强度较低,协同分散强度较高;25~68 km属于协同集聚强度攀升而协同分散强度急剧下降阶段;68~110 km附近,协同集聚强度继续提高,同时协同分散强度也在提高;110 km之后协同集聚和协同分散强度都在逐步下降(图9)。这表明25~68 km是2008年京津冀制造业协同集聚的显著尺度范围。
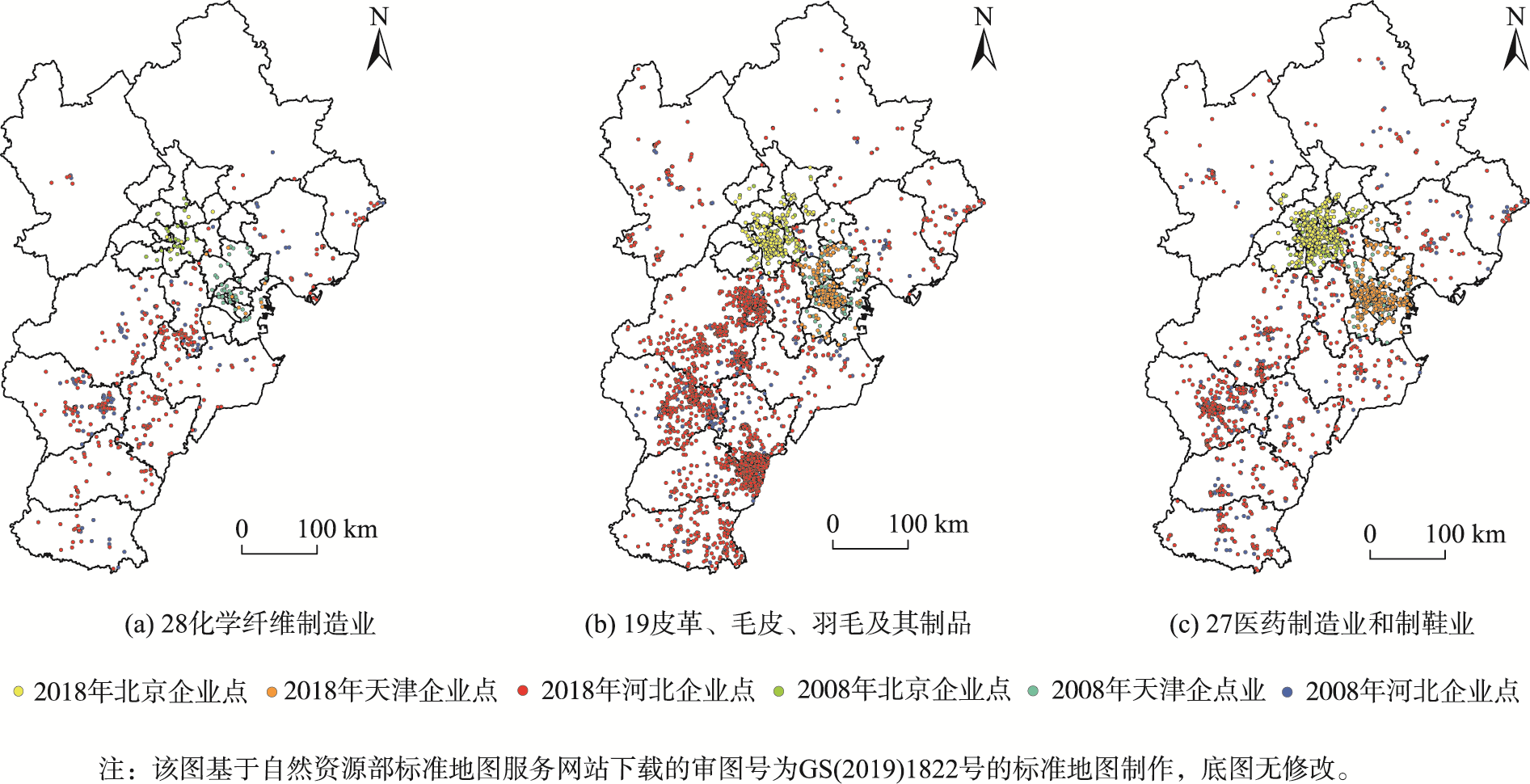
图5 不同空间尺度上的协同集聚/分散强度折线图
3.2.2 TOP 20行业对
对2008年和2018年协同集聚强度最大的TOP 20行业对分析协同集聚显著发生的尺度范围和最显著的尺度,对于有多个协同集聚尺度的,取最大值所在的尺度(图10)。
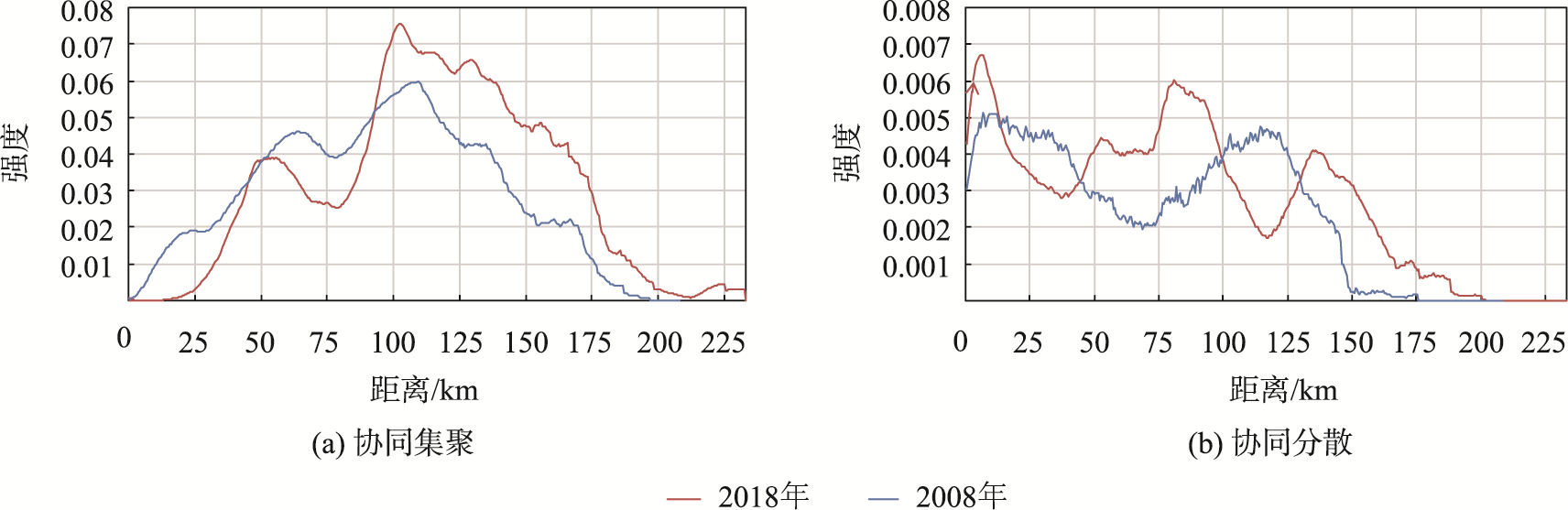
图6 TOP 20行业对协同集聚发生的尺度范围对比
4 结论与讨论
4.1 结论
本文分析了京津冀协同发展战略提出前后制造业协同集聚格局的演化趋势,验证了京津冀协同发展战略的实施效果。研究结果表明:
- 在强度分析方面,2008年协同集聚的行业对占比为85.47%,2018年为82.53%,平均协同集聚强度由0.030变为0.029,基本格局保持相对稳定;在协同集聚强度最高的20个行业对中,2018年每个行业对的协同集聚强度均高于2008年,强度值高的更高,但中等左右的行业对强度变低;2008年与2018年有48.28%的行业发生了空间协同集聚强度变化,强度提升最大的行业分别是化学纤维制造业、皮革、毛皮、羽毛及其制品、制鞋业、医药制造业,这些行业具有向河北扩散的趋势。
- 在尺度分析方面,2008年25~68 km是京津冀制造业企业协同集聚的显著尺度范围,2018年则是55 km以内和75~103 km,协同集聚显著发生的尺度范围变大。75 km左右正是省市内部与省市之间的划分临界值,说明京津冀协同发展战略提出后制造业之间跨省级行政边界的合作更多,而"头部"行业对的此特征更为明显,其最显著发生协同集聚尺度的平均值由80.91 km提高到125.15 km。
4.2 建议
基于以上结论,本文对京津冀地区产业协同发展提出如下建议。
一方面,积极推动产业集聚和协同集聚。产业集聚和协同集聚是当前京津冀地区重要的产业分布形态,要因势利导,将非首都功能疏解与周边地区产业承接与集聚相结合,优化产业布局,促进制造业重心向河北转移,提高区域整体竞争力;根据更容易与其他产业形成协同集聚的产业类型,鼓励医药制造业、化学纤维制造业、通用设备制造业等率先疏解、承接和集聚,加强优质医疗资源与医药健康产业协同发展,引导带动一批高附加值零部件和新能源智能汽车供应链在京津冀布局;结合产业协同集聚的显著尺度,合理布局各类承接地和产业园区,着力优化现代化首都都市圈150 km产业圈。
另一方面,妥善处理好政府干预与市场调节的关系。当前京津冀产业协同发展和空间集聚更多依赖行政力量和政府干预,如规划建设雄安新区集中承载地、各类产业园区等,未来要逐步发挥市场调节作用,鼓励京津冀地区率先开展区域市场一体化建设,推动资本、劳动、技术、信息等生产要素在三省市自由流动,充分发挥市场在资源配置中的决定性作用;着力破除阻碍要素流动的体制机制障碍,落实国家先进制造业集群发展专项行动,共同打造现代化产业体系,形成北京作为科创中心、天津作为先进制造研发基地、河北作为高端产业转化地的产业格局。
4.3 讨论
为与传统经济学方法做比,本文还以地级市为单元计算了协同EG指数,它是产业协同集聚研究中最常使用的方法之一。结果显示,2008年和2018年京津冀地区制造业协同集聚的行业对占比分别为99%和73%。这一计算结果与本文DO指数结果有所不同。本文认同Duranton和Overman认为两类方法的结果差异主要是由于可塑性面积单元问题,在行政边界附近的行业,即使地理和经济距离较近,在协同EG指数计算中也会被认为完全不相干的实体进行处理。2008年企业在省市内部分布紧凑,缺乏显著性检验的情况下,结果被高估;而2018年企业跨行政边界分布的特征更加明显,导致相当部分行业间协同EG指数计算结果为负,结果又被低估,最终体现为协同集聚行业对占比锐减。
相比传统经济学方法,DO指数避免了可塑性面积单元问题,考虑了协同集聚发生的偶然性并给出置信水平,满足一个好的集聚测度指标应具备的全部条件:① 行业间可比;② 能够控制经济活动的总体集聚程度;③ 能够控制行业集中程度;④ 空间尺度的改变不会影响指数估计值的无偏性;⑤ 能够对估计结果进行显著性检验。因此,使用DO指数在测度产业协同集聚的精准性和可靠性上具有优势。
* 以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。