2 算法原理
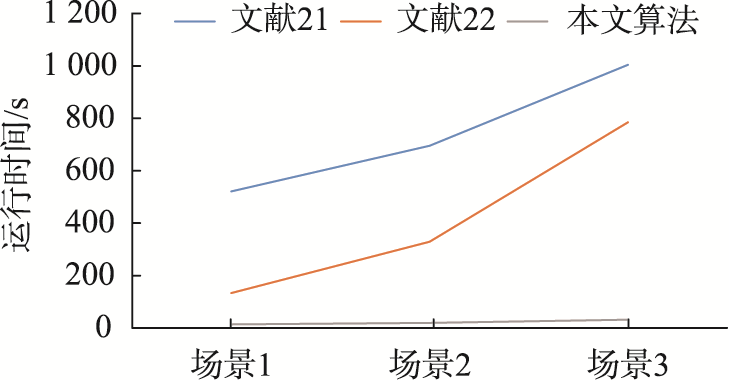
本文提出一种结合自适应Mean Shift聚类、Nyström方法和粒子群优化K-means算法的点云单木分割流程,显著提升林区单木分割的效率和准确性。
自适应Mean Shift聚类
采用基于局部近邻距离的自适应带宽设置策略,将带宽的选取和数据的局部密度特征相结合,以便更好地适应不同区域的密度变化。
Nyström方法
通过对整个数据集进行选择性采样,构建一个代表性的样本子集,并使用这些样本来近似整个数据集的谱属性,显著降低计算资源需求。
粒子群优化K-means
通过粒子间的信息共享和协作寻找全局最优解,每个粒子代表一组可能的聚类中心,旨在找到能够最小化聚类内距离的最优中心点集合。
算法流程图
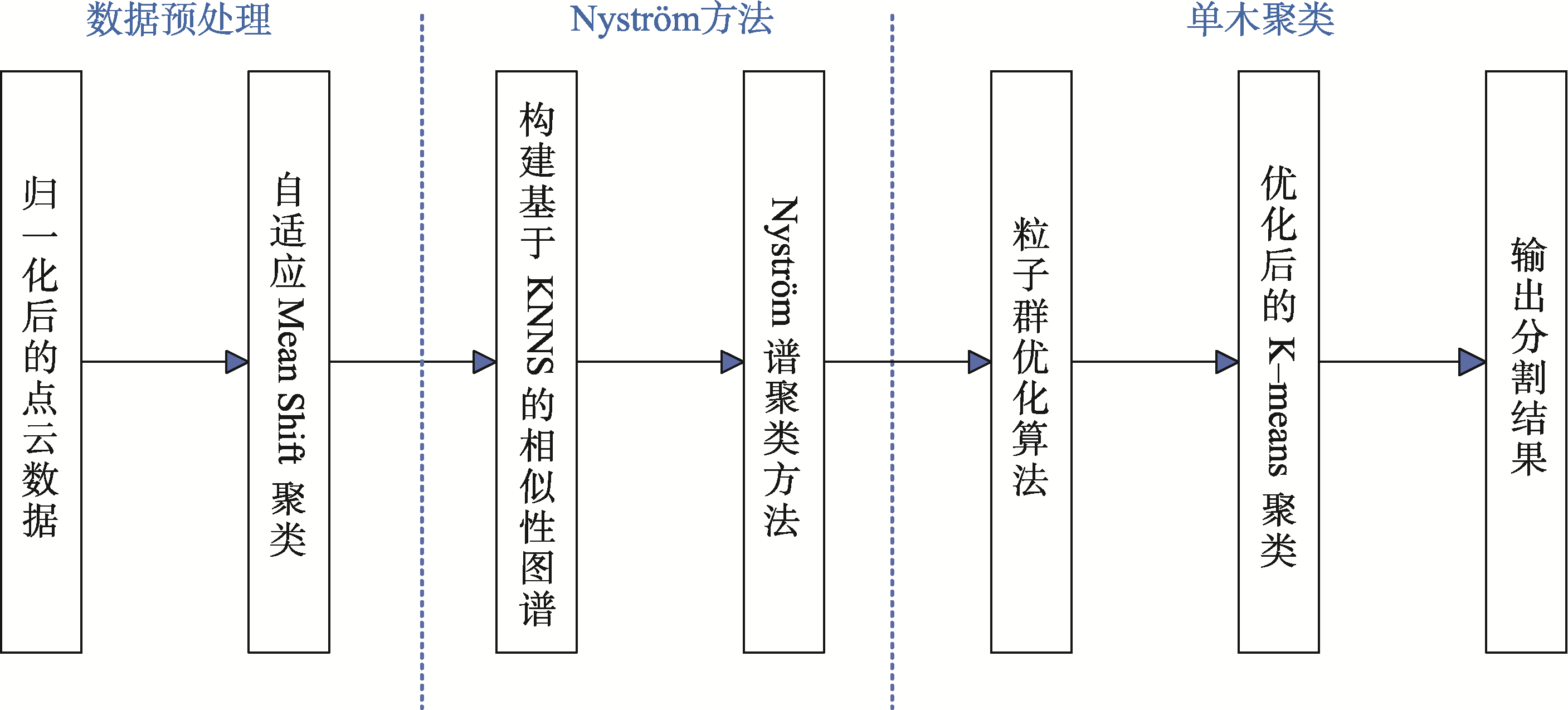
图1 结合谱聚类和粒子群改进K-means聚类的机载LiDAR点云单木分割方法流程
2.1 自适应Mean Shift聚类
本文采用的自适应Mean Shift算法通过局部密度量化动态调整带宽:
σ = ρ(1 + α(1 - density(xc)/densitybase)
其中σ表示自适应带宽大小,ρ代表初始搜索半径,α为调节系数。这种动态调整机制允许算法:
- 在高密度区域使用较小半径捕捉细致结构
- 在低密度区域使用较大半径增强搜索能力
- 适应从均匀分布到高度聚集的各种分布类型
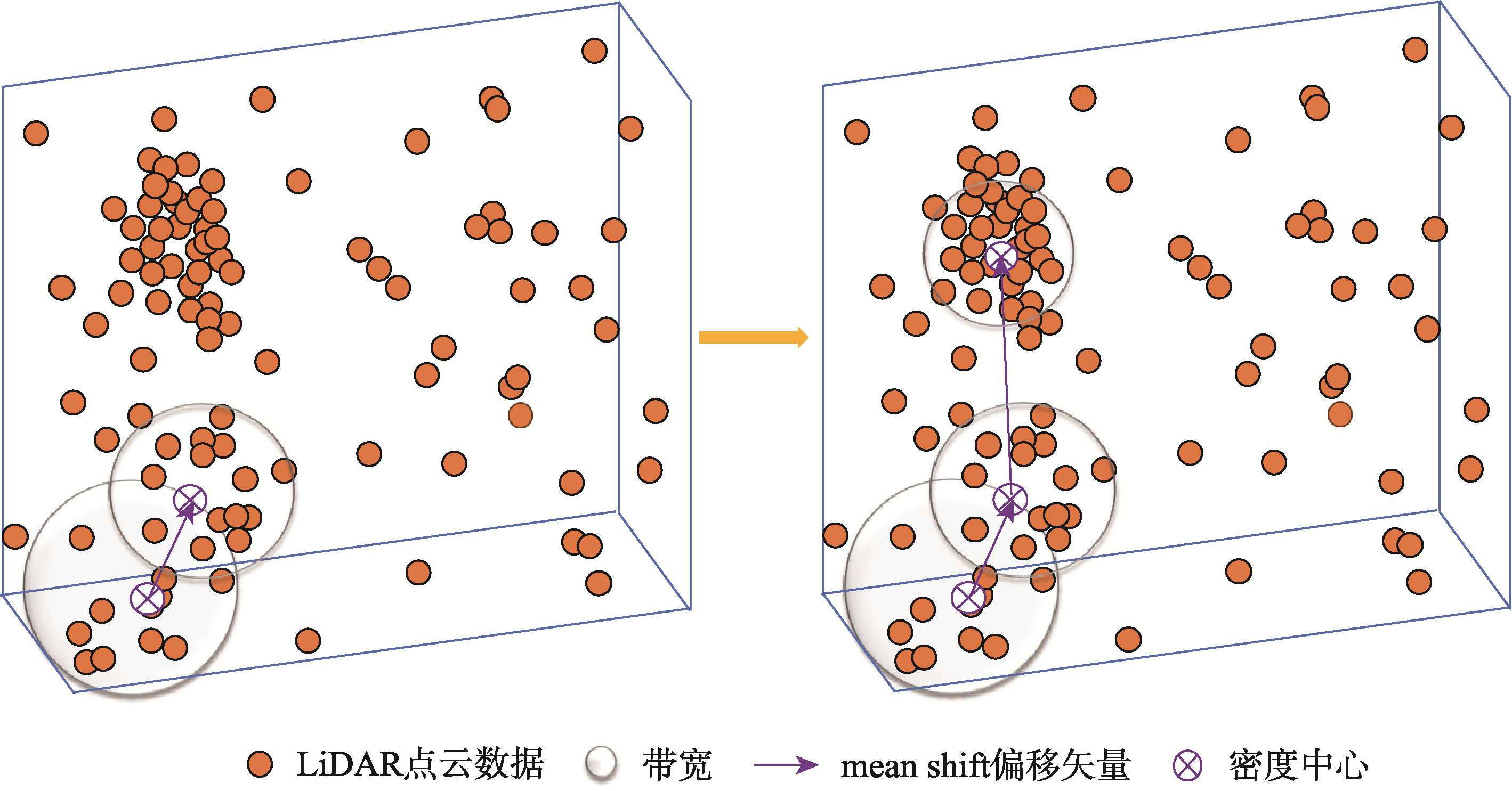
图2 Mean Shift聚类示意图
2.2 Nyström谱聚类方法
Nyström方法通过采样机制和低秩近似显著降低计算负担:
W = [A B; BT C]
其中A为采样样本间相似度矩阵,B为采样与剩余样本间相似度矩阵,C为剩余样本间相似度矩阵。通过KNN构建的高斯相似度函数:
S(i,j) = exp(-∥pi-pj∥2/2σ2)
2.3 粒子群优化K-means聚类
粒子位置和速度更新公式:
Vid(t+1) = Vid(t) + k1r1(Pid-xid(t)) + k2r2(Gid-xid(t))
Xid(t+1) = Xid(t) + Vid(t+1)
适应度函数综合考虑簇内紧密度和簇间分离度:
F(C) = ΣIi - λΣΣSij