研究背景
城市暴雨级联事件特点
城市暴雨级联事件(Urban Rainstorm Cascading Events, URCE)侧重于描述暴雨及其次生致灾事件造成的后果,如基础设施破坏、居民被困、交通拥堵和建筑损毁等。
- 大范围(影响覆盖城市各类区域)
- 小粒度(不同点位的URCE发生可能性差异)
- 多类型、涌现性(城市环境日益复杂带来新的URCE)
现有方法局限性
灾损曲线方法
要求承灾体具有同质性,小粒度多点位的URCE风险评估所需数据通常十分庞大,难以获得。
综合评价方法
在指标体系设置和专家打分方面具有一定主观性,尤其是面临多样化异类型URCE风险,难以确保评估的客观有效。
研究方法
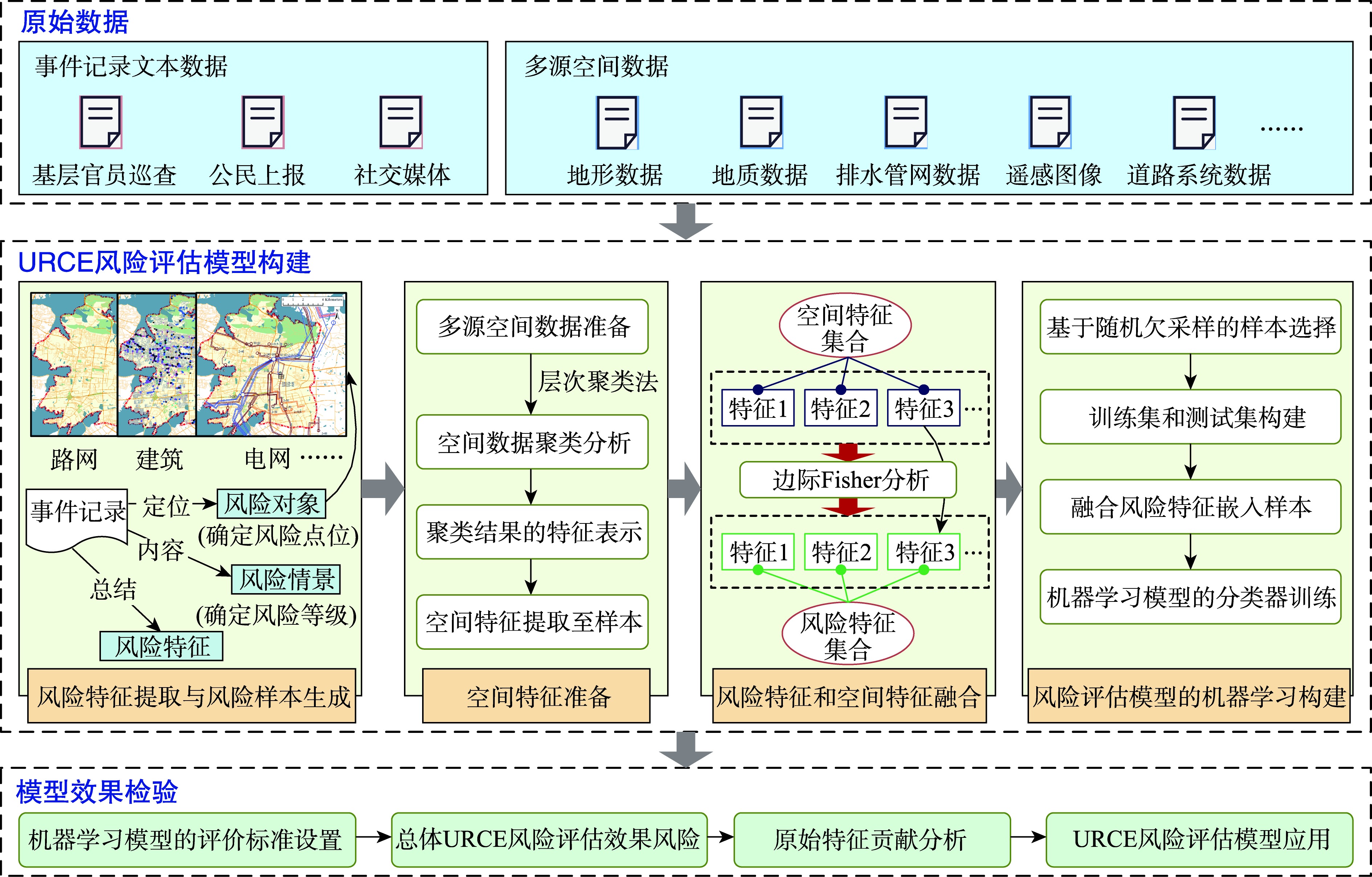
图1 基于空间特征挖掘和机器学习的URCE风险评估模型构建方法流程
风险特征提取与风险样本生成
根据基层官员巡查、公民上报和社交媒体所得现实事件记录,完成风险样本数据准备及相关风险特征的提取。
- 根据事件定位,明确对应的风险对象,建立风险样本
- 根据事件内容,明确情景要素状态,帮助界定风险等级
- 从事件应对总结中提炼风险特征
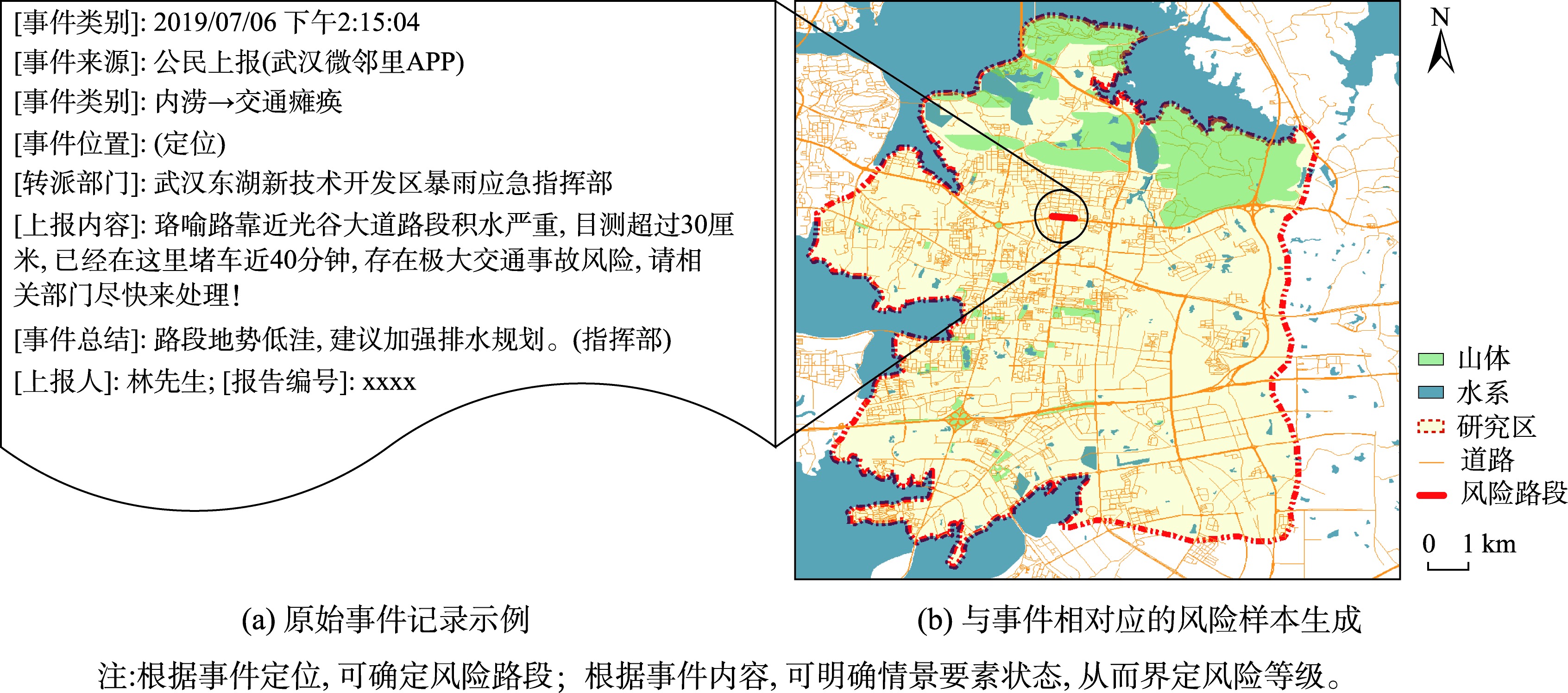
图2 基于URCE事件记录的风险样本生成示例
空间特征准备
结合可获取的多源空间数据,共提炼了八类空间特征,并通过聚类转化为文本特征:
表1 空间特征示例
| 空间特征类别 | 空间特征 |
|---|---|
| 地形特征 | 地面高程/m |
| 地质特征 | 是否存在临近山体 |
| 排水能力特征 | 排水管排水能力/(mm/s) |
| 水系特征 | 是否存在临近水库 |
| 道路特征 | 车流量/(辆/h) |
| 电网特征 | 电力设施类型 |
| 建筑特征 | 建筑年龄/年 |
| 人口热力特征 | 区域人口热力/(人/km²) |
风险特征和空间特征融合
采用改进的边际Fisher方法从前述空间特征中自适应地选择高价值风险特征,以提高风险特征完备性。
M = argminM Sc/Sp
式中:
- Sc为类内差异性
- Sp为类间分离性
该目标函数在本文特征融合中的含义是:为多个空间特征赋权重,通过自适应调整空间特征权重,使得不同种类样本的区分性最优,从而帮助提高URCE风险评估的分类器效果。
风险评估模型的机器学习构建
机器学习样本选择
采取随机欠采样(Random under Sampling, RUS)方法,从低风险样本中选择与风险样本量相平衡的样本,用于风险评估模型构建。为提高风险样本与低风险样本的对比性,优先选择与风险样本空间距离较近的低风险样本。
机器学习模型训练
采用支持向量机(Support Vector Machine, SVM)这一基准机器学习算法进行分类训练。SVM具有高准确率、泛化能力强、能够处理高维特征数据等优点,相比于深度学习算法具有更快的处理速度和更低的运行成本。
实验设计与结果分析
实验区概况
武汉东湖新技术开发区(又名:中国光谷)位于武汉市东南,占地518 km²,是我国国家级高新区和国家光电子产业基地。
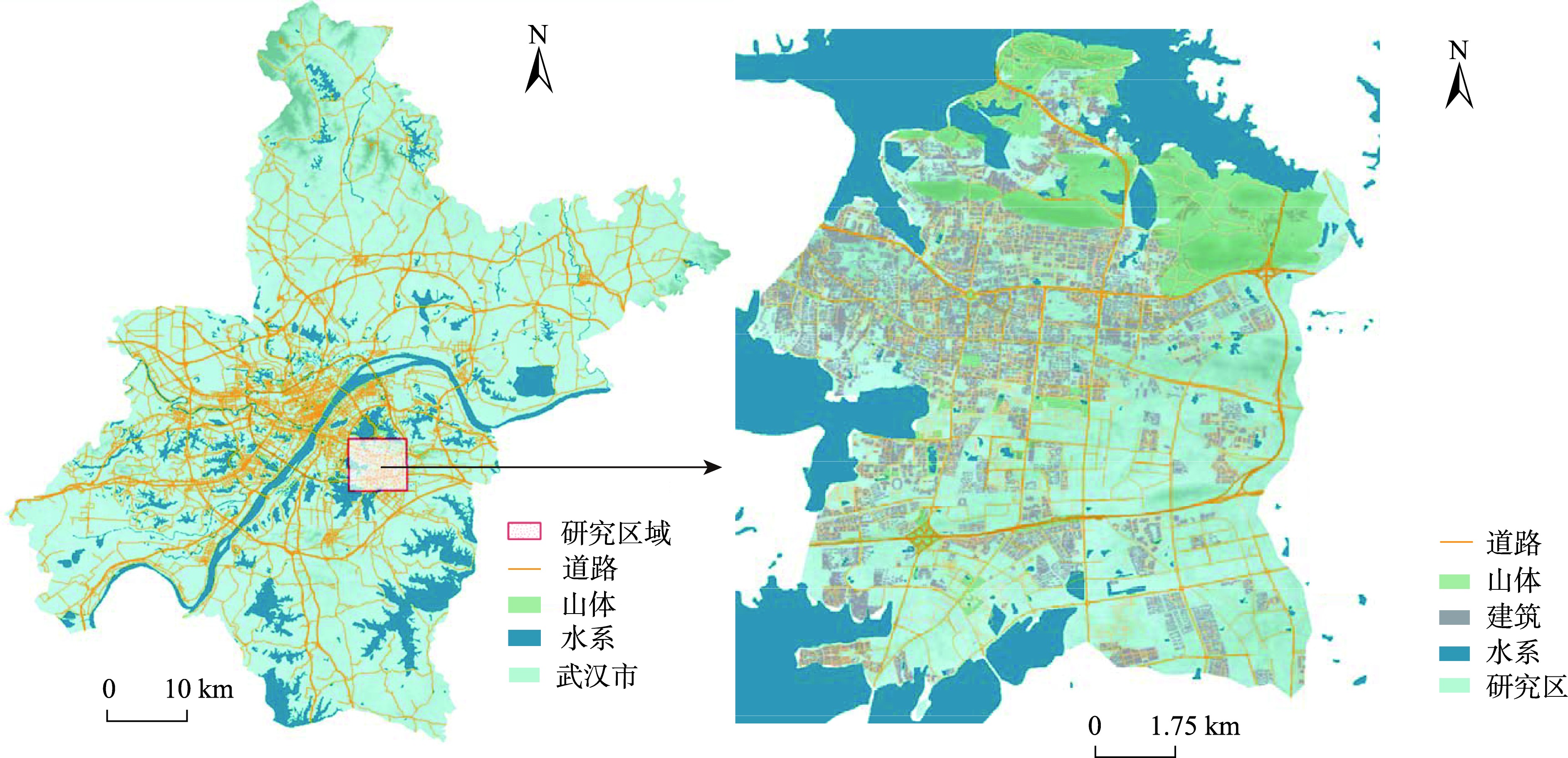
图3 研究区域位置
数据来源
事件文本数据
- 基层官员巡检数据:4,370条
- 公民上报数据:3,877条
- 社交媒体数据:5,101条
空间数据
- 地形数据、地质数据
- 排水管网数据、遥感数据
- 道路数据、电力数据
- 建筑数据、电信数据
风险样本分布
表2 风险样本分布
| URCE风险 | 符号 | 高风险样本数 | 中风险样本数 | 低风险样本数 |
|---|---|---|---|---|
| 内涝→交通瘫痪 | #a | 965 | 1,953 | 999 |
| 内涝→电网损毁 | #b | 614 | 1,627 | 1,049 |
| 内涝→居民受困 | #c | 556 | 1,304 | 746 |
| 泥石流→建筑损毁 | #d | 162 | 350 | 161 |
| 泥石流→交通拥堵 | #e | 177 | 465 | 204 |
| 洪水→建筑损毁 | #f | 438 | 1,006 | 572 |
总体URCE风险评估模型效果
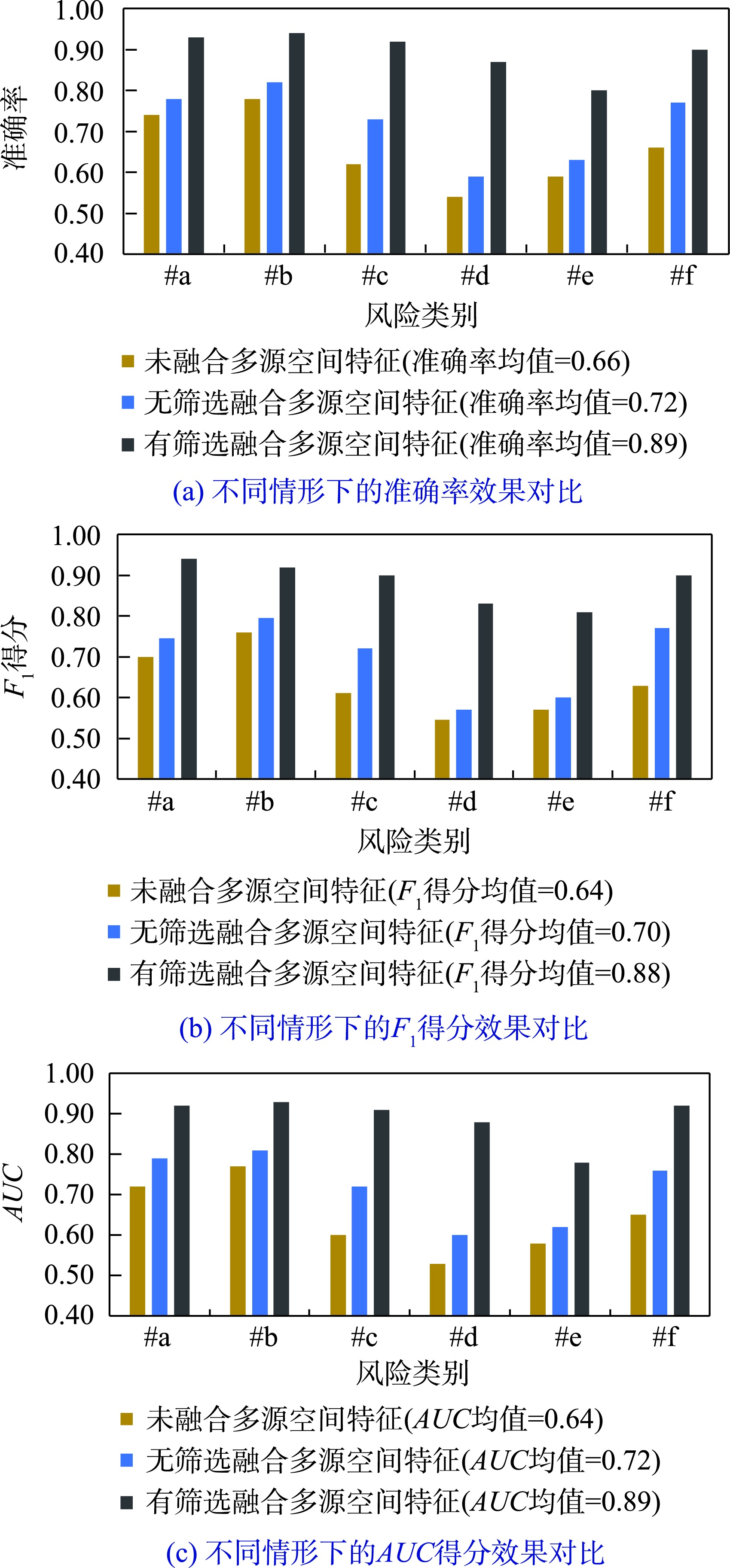
图4 总体URCE风险评估效果及其与未融合多源空间特征时的效果对比
可以发现,在融合多源空间特征后,各类URCE风险评估的模型效果得到大幅度提升,总体准确率、F1得分以及AUC分别提升了23%、24%以及25%,部分类别(如#c和#d)的准确率提升了30%以上。
不同方法对比
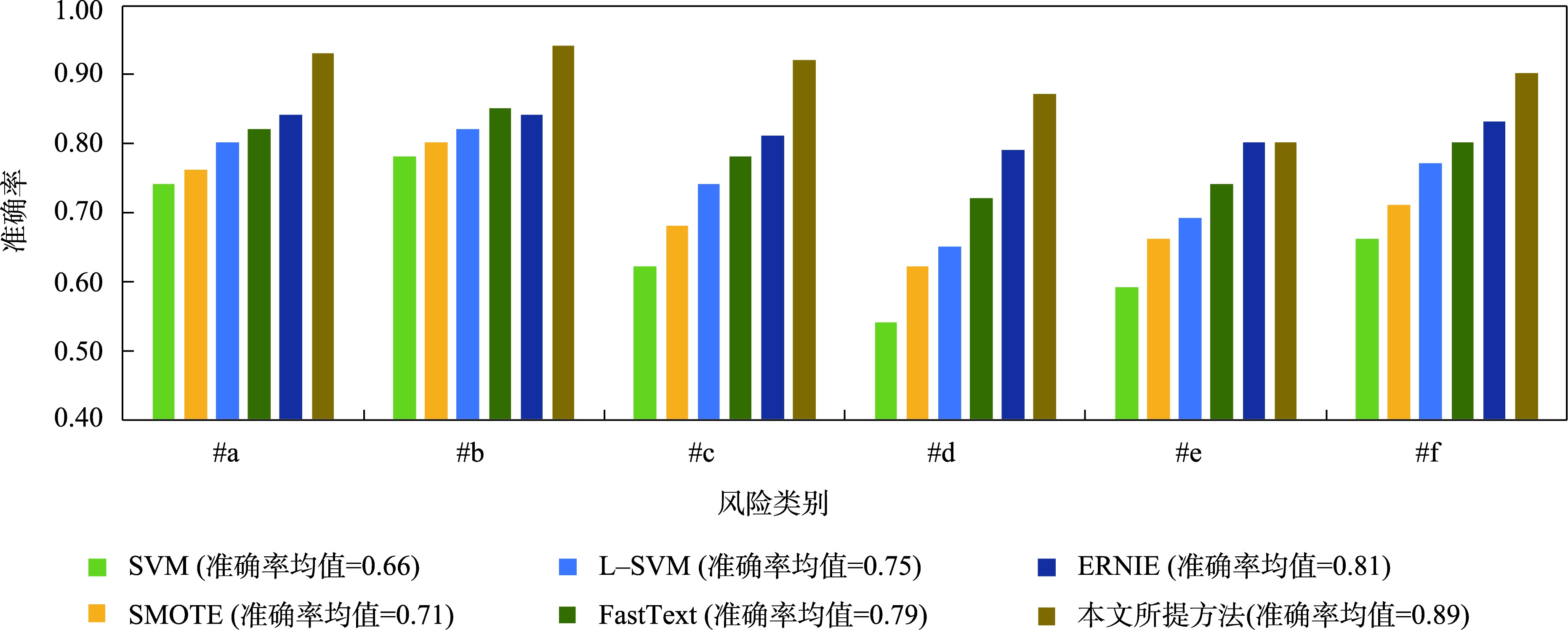
图5 不同方法应用下的URCE风险评估效果
本文所提方法在模型效果上优于其他方法;在未融合风险特征和空间特征时,深度学习方法(FastText和ERNIE)的效果优于SMOTE和L-SVM等机器学习方法;在利用本文方法融合空间特征后,风险评估效果显著增加。
原始特征贡献分析
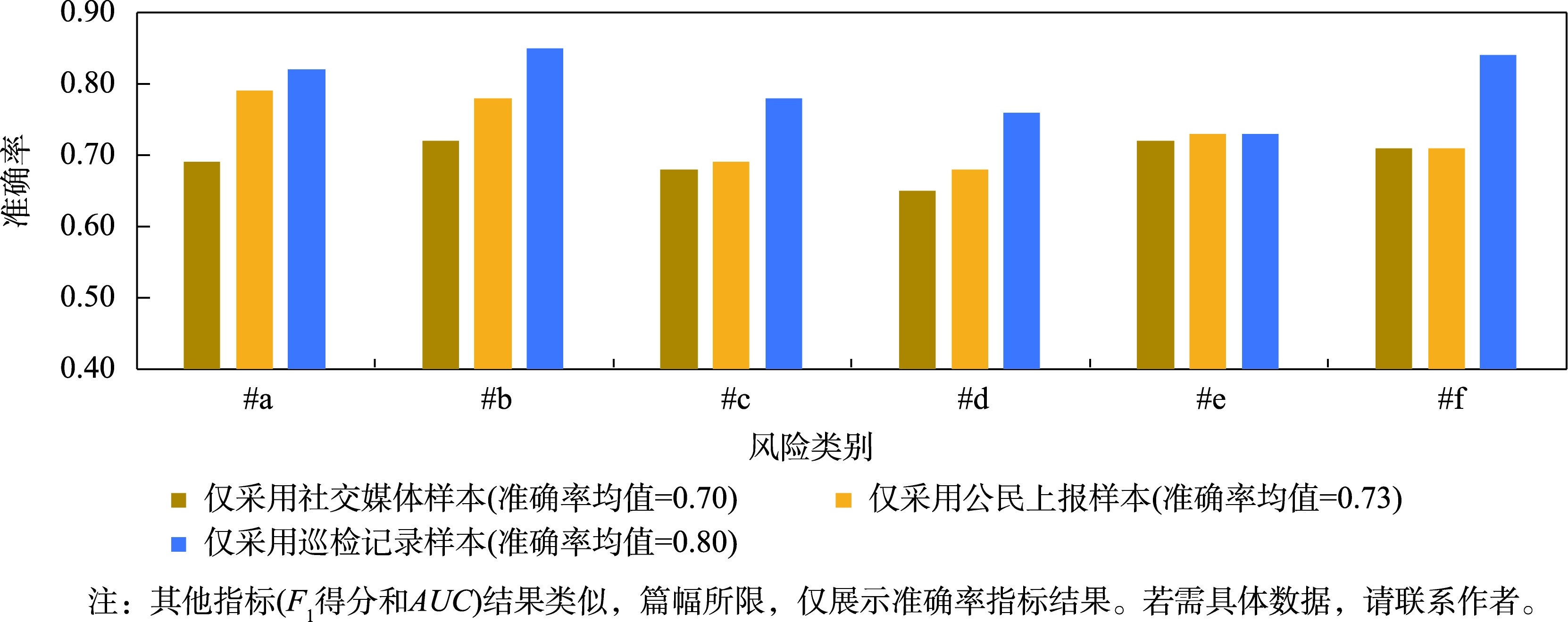
图6 不同种类原始特征下的URCE风险评估效果
巡检记录对风险评估模型构建的特征贡献最大,其次是公民上报文本,最后是社交媒体,追根溯源,是基层官员相对公民而言具有更多的工作经验和风险知识,提供的风险特征更为可靠。
管理启示:
管理部门应强化对事件内容的规范化管理,同时加强对公民和社交媒体信息贡献的激励,提高多主体信息在暴雨灾害管理中的有效性。
模型应用
URCE风险评估模型应用
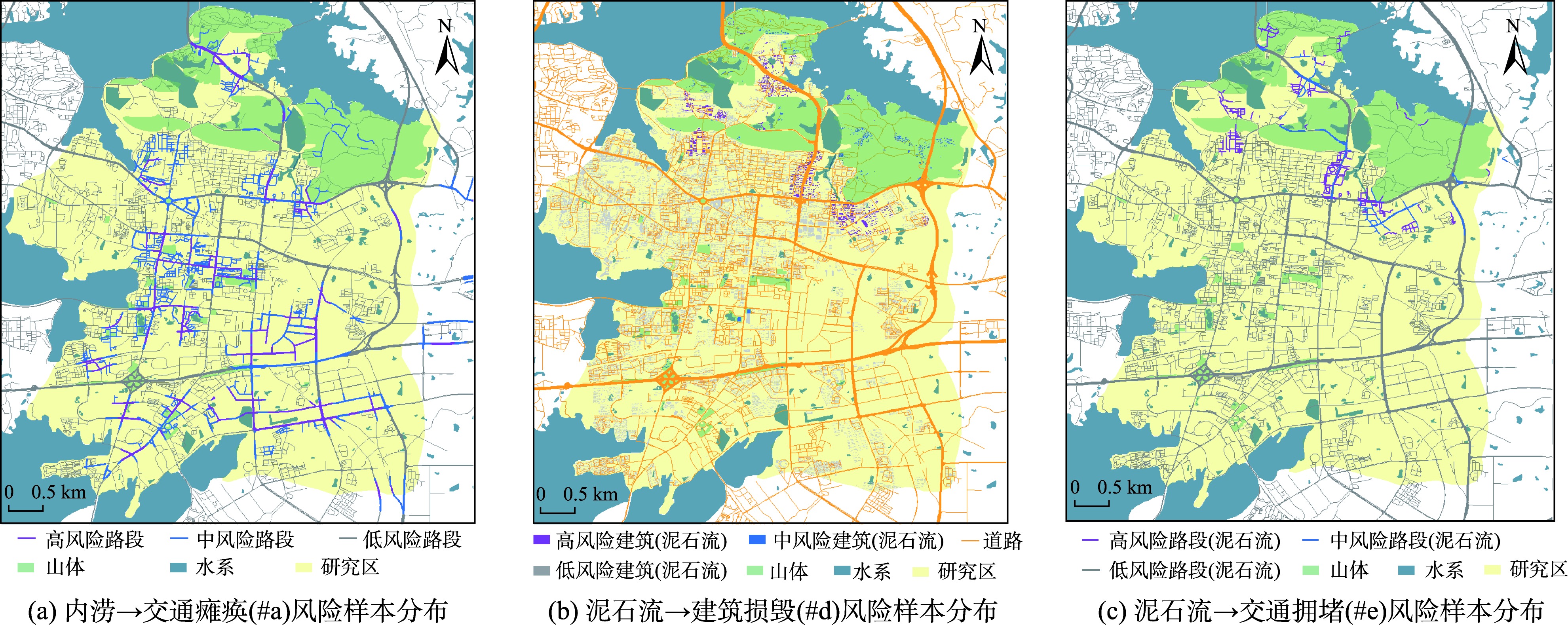
图8 部分URCE类型的风险评估结果
利用构建的URCE风险评估模型,可以生成各类URCE的风险评估结果,藉此服务于URCE的事前预防与管理,实现风险管控。不同类型风险的空间分布具有显著差异,体现出URCE风险的复杂性。
模型耗时:
本文所提模型构建方法利用SVM做分类器,具有计算效率高、计算成本低的优势;就本文实验中的6类事件的风险评估而言,模型的总运行时间(包括模型训练和风险评估结果生成)平均仅需7.2秒。
研究结论
本研究提出一种融合风险特征和空间特征的URCE风险评估模型构建方法,尝试通过融合多源空间特征,突破因原始风险样本特征不完备带来的URCE风险评估模型效果约束。
主要贡献
- 提出了一套集成文本分析、改进边际Fisher分析以及机器学习的方法框架
- 总体准确率、F1得分以及AUC分别提升了23%、24%以及25%
- 厘清了基层官员巡检、公民上报、社交媒体数据发布等不同形式的样本在风险评估模型构建中的特征贡献
未来研究方向
- 拓展所提方法在其他自然灾害、事故灾难、公共卫生等多灾种场景和城市、乡村、海域等多区域场景中的应用
- 探索除多源空间大数据外的其他类型大数据,如网络知识图谱、大模型问答数据等在灾害风险预测及评估中的作用
- 研究灾害风险评估背后的数据治理问题,为更多大数据方案的产生提供机会