引言
公共服务设施作为城市社会性服务的基础设施,涵盖了教育、医疗、文体等多个领域,其分布与服务大众的性质使其在城市社会结构和可持续发展中发挥着至关重要的作用。它们的分布不仅影响着居民的日常生活,更关系到整个城市社会结构的合理性和可持续发展的方向。
选址问题的复杂性在于其涉及多个空间维度和复杂的相互关系,解决这类问题需要建立高效的选址模型,其中经典的选址模型包括P中值(P-median)模型、P中心(P-center)模型、集合覆盖模型等,这些选址模型通常属于NP-hard问题。
随着人工智能领域的兴起,深度强化学习(Deep Reinforcement Learning, DRL)作为其中一个重要的分支,主要用来做序列决策。事实上,选址问题具有明显的时序性和决策过程,需要一个能够在不同时间步骤中作出决策并从中学习的模型。
为了更有效地解决公共服务设施选址问题并充分探索DRL在这一领域的应用潜力,本研究基于改进的GAT提出了一种创新的端到端DRL选址模型——图强化选址模型(Graph-Deep-Reinforcement-Learning Facility Location Allocation Model, GDRL-FLAM)。该模型综合运用了GAT的全局建模和Transformer的序列决策能力。
研究方法
2.1 技术路线
本研究提出了一种耦合设施选址图注意力网络(Facility Location Allocation Graph Attention Network, FLA-GAT)与DRL算法的图强化选址模型(GDRL-FLAM),旨在更有效地解决公共服务设施的选址问题,框架见图1,主要包括FLA-GAT模型以及使用DRL算法进行训练和测试的2个部分。
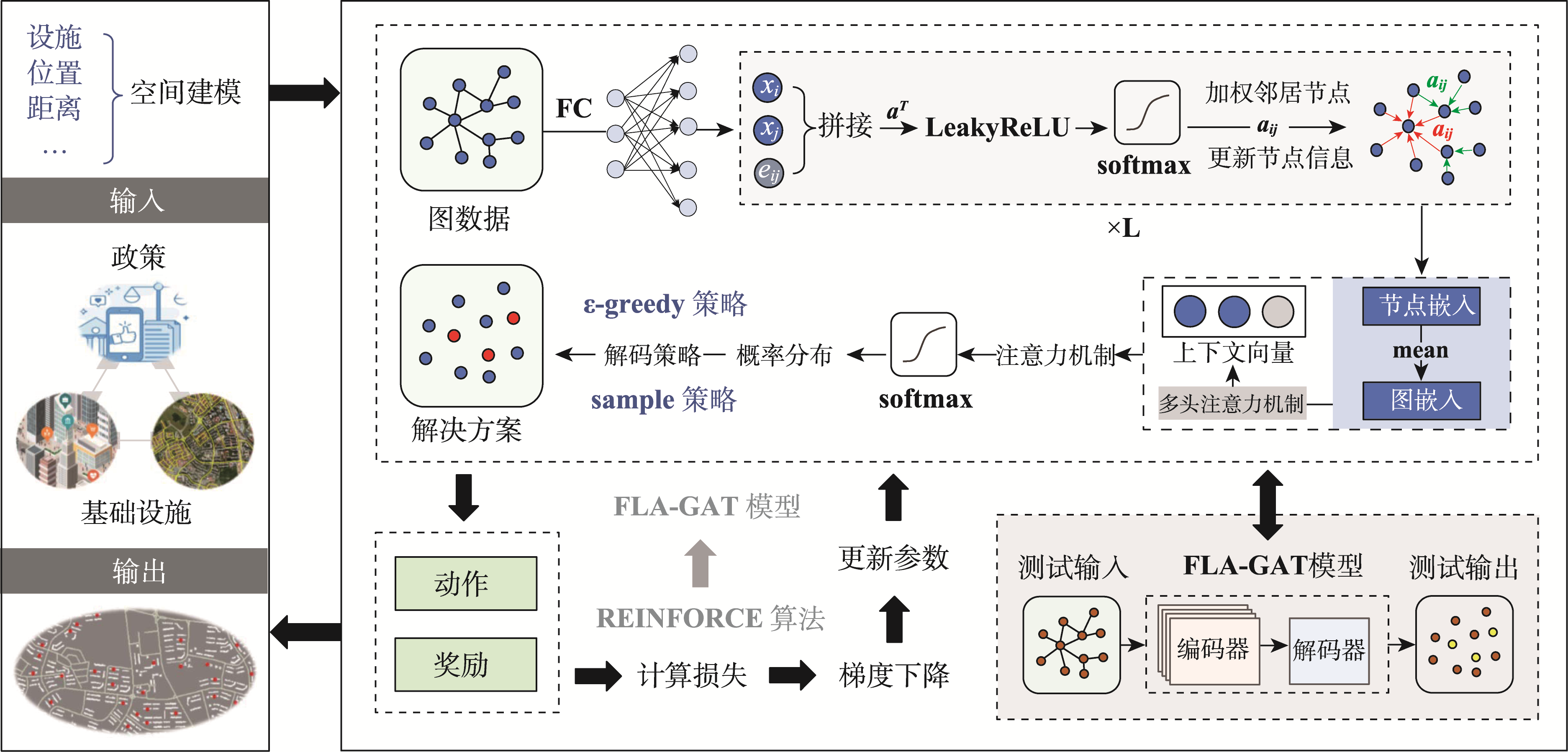
2.2 FLA-GAT模型
对于设施选址问题,在一个无向图G=(V, E, W)上定义问题实例,其中每个节点i属于V={1,..., n},表示一个潜在的设施位置,其特征由坐标ni表示。边aij∈E表示设施位置之间的连接,其中i, j∈W,而eij∈E表示与aij相关的距离信息。

FLA-GAT包括编码器和解码器两部分,编码器通过嵌入生成对所有输入节点的表示,任务是将问题信息转化为解码器理解的嵌入表示。解码器按照不同的解码策略逐个节点生成被选择的点。通过设计掩码防止重复选择已选取的点,可以有效地搜索潜在解空间并缩小动作空间。
2.3 DRL算法
本研究采用REINFORCE算法来进行选址优化。在这个算法框架下,该模型致力于解决公共服务设施选址问题,该问题的优化目标是最小化其他点到最近选择点的距离之和。使用GDRL-FLAM模型将选址问题建模为图输入,并通过策略优化来获得最优解。
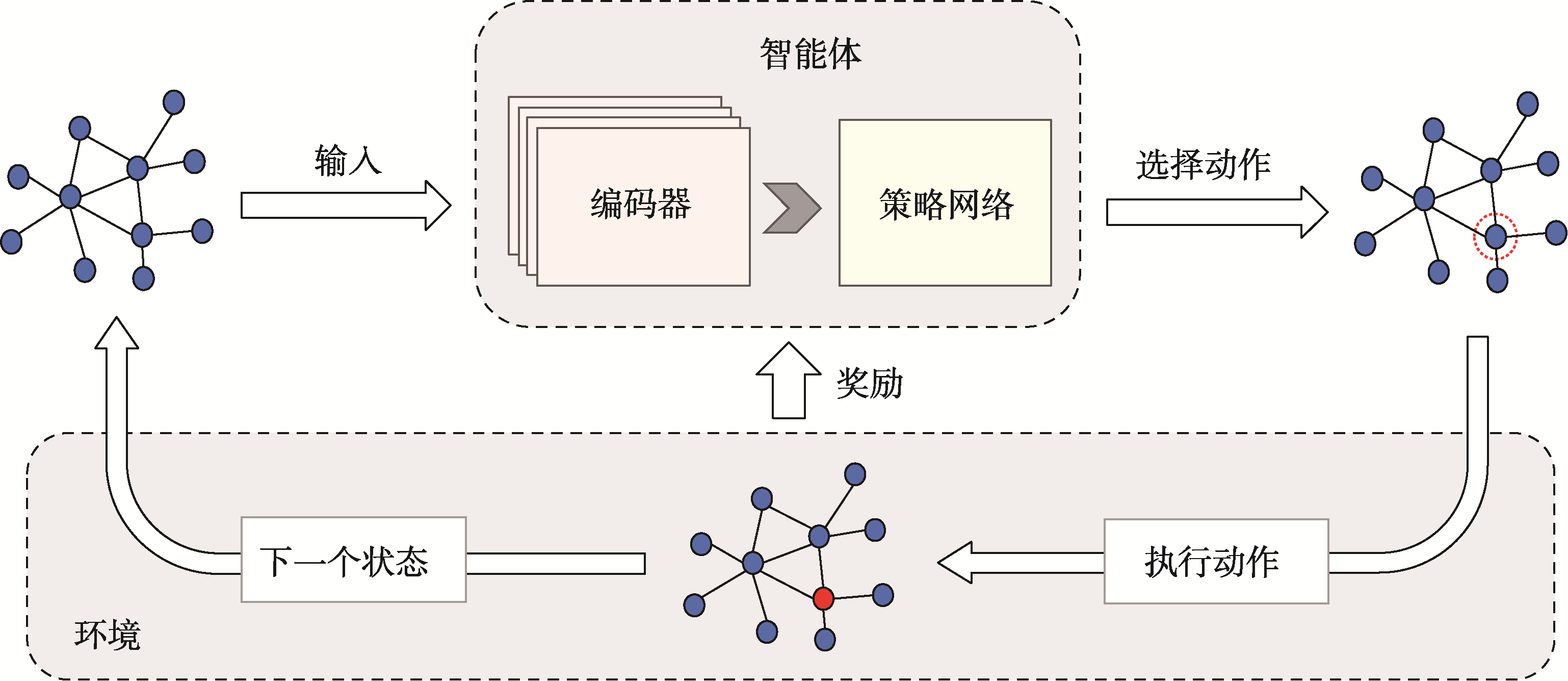
将公共服务设施的选址问题建模为马尔可夫决策过程,决策过程主要包括状态(state)、动作(action)和奖励(reward) 3部分。状态代表当前已选设施位置和需求点的位置,状态空间s(t)描述了到目前为止已选设施的空间布局。动作对应于在何处放置下一个设施的决策,每个动作涉及选择新设施的具体位置。在选址问题中,奖励R(t)反映了优化的目标。具体而言,目标是最小化需求点到最近设施点的距离之和。
模型验证
为了展现GDRL-FLAM模型在公共服务设施选址问题上的优越性,以及DRL在该领域的潜在价值,本研究开展了一系列实验。这些实验旨在为未来公共服务设施规划提供更为智能、灵活的选址决策支持。
3.1 同规模下的泛化测试实验
采用相同的数据分布模式分别生成5 000个0到1之间包含20、50和100个节点的实例来进行测试,分别从中选择3、5和8个设施点,称为FLP20、FLP50、FLP100,通过计算这5 000个实例的平均距离来评估模型性能。
| 方法 | FLP20 | FLP50 | FLP100 |
|---|---|---|---|
| GA | 目标值: 4.411 DI/%: 0.00 时间: 3h |
目标值: 8.700 DI/%: 0.00 时间: 5h |
目标值: 14.081 DI/%: 0.00 时间: 12h |
| GDRL-FLAM (ε-greedy) | 目标值: 3.773 DI/%: 14.33 时间: 11min |
目标值: 7.593 DI/%: 12.56 时间: 27min |
目标值: 12.400 DI/%: 11.79 时间: 58min |
| GDRL-FLAM (Sample) | 目标值: 3.766 DI/%: 14.49 时间: 24min |
目标值: 7.566 DI/%: 12.87 时间: 53min |
目标值: 12.373 DI/%: 11.99 时间: 2h |
3.2 大规模下的泛化测试实验
为了进一步测试模型的泛化性能,本研究进行了更大规模的随机点的测试实验。通过生成3 000个包含150个节点的实例与2 000个包含200个节点的实例来测试模型在大规模数据集上的泛化效果。
| 方法 | 目标值 | DI/% | 时间/h |
|---|---|---|---|
| GA | 17.787 | 0.00 | 11 |
| GDRL-FLAM50 (ε-greedy) | 17.406 | 1.97 | 2 |
| GDRL-FLAM100 (ε-greedy) | 16.273 | 8.34 | 2 |
| 方法 | 目标值 | DI/% | 时间/h |
|---|---|---|---|
| GA | 15.282 | 0.00 | 10 |
| GDRL-FLAM50 (Sample) | 14.792 | 3.06 | 4 |
| GDRL-FLAM100 (Sample) | 13.835 | 9.33 | 1 |
3.3 迁移学习能力实验
本文研究了不同规模数据集之间的可迁移性,在20个点的数据集上获得一个预训练模型,并在50个点的数据集上对其进行微调,本研究将预训练的模型与从头开始训练的模型进行比较。
| 方法 | 目标值 | DI/% | 时间 |
|---|---|---|---|
| GA | 8.700 | 0.00 | 5h |
| 预训练 | 7.588 | 12.63 | 26min |
| 从头开始 | 7.593 | 12.56 | 27min |
案例研究
4.1 背景介绍
为了更好地验证GDRL-FLAM模型的优越性以及为未来提供精准的医疗服务选址决策支持,本研究选择在实际案例中测试该模型。新加坡的医疗保健系统以其高效和优质的服务而著称。
宏茂桥(Ang Mo Kio)位于新加坡中心区域,不仅有多样化的住宅网络,还包括众多社区设施。因此,本研究选择新加坡宏茂桥区域作为研究区,房屋发展局(Housing and Development Board,HDB)为案例研究对象。宏茂桥区域共有380个HDB点,研究从中选择50个CHAS诊所,使得HDB到最近的CHAS诊所的距离之和最小,以确保医疗服务设施在整个区域的普及和均衡分布。
4.2 实验结果与分析
案例研究中所使用的经纬度数据、边界数据和道路数据均来源于新加坡市建局(Urban Redevelopment Authority, URA)。在考虑到新加坡点的经纬度特性时,本研究在模型训练中选择了使用0到1的随机点数据进行训练。
| 方法 | GDRL-FLAM50 | GDRL-FLAM100 |
|---|---|---|
| GA | 目标值: 16.715 DI/%: 0.00 |
目标值: 16.715 DI/%: 0.00 |
| GDRL-FLAM (ε-greedy) | 目标值: 16.546 DI/%: 1.01 |
目标值: 15.590 DI/%: 6.73 |
| GDRL-FLAM (Sample) | 目标值: 15.900 DI/%: 4.88 |
目标值: 15.031 DI/%: 10.75 |
从空间分布上来看(以GDRL-FLAM100并采用ε-greedy策略为例),可以观察到在宏茂桥的西部地区,由于小区分布相对较为稀疏,GA的结果在这一区域呈现出过多的诊所分布,导致医疗资源的浪费现象凸显。相比之下,GDRL-FLAM模型表现出更为均衡的结果,能够有效避免在稀疏小区过度分配医疗资源的问题。
结论与讨论
在当今城市社会性服务业的发展中,公共服务设施作为支持教育、医疗、文体等社会性基础设施的重要组成部分,对于居民的日常生活和城市社会结构的合理性起着关键作用。然而,现有常用的公共服务设施选址方法往往未能满足复杂及大规模的现实场景中对于其性能及效率上需求。
本研究创新地提出了GDRL-FLAM模型,旨在通过耦合改进设施选址图注意力网络FLA-GAT与DRL的方式,更有效地解决公共服务设施选址问题。这一创新性的模型结合了GAT和DRL的优势,以适应不同规模和地理条件的城市环境,并且同时具备GAT的全局建模和Transformer的序列决策能力,提供更为智能、灵活的选址决策支持。
为了验证该框架的有效性,本研究进行了在不同规模(20、50、100)的随机点上的训练。首先,在规模为20、50和100个点的测试实例中,相较于GA,GDRL-FLAM模型在距离优化方面实现了显著改善,距离改善幅度分别达到了11.79%到14.49%。在更大规模的150和200个点的测试实例上,模型仍然呈现1.52%到9.35%的距离改善,突显了GDRL-FLAM在不同规模数据集上的鲁棒性和出色表现。
本研究观察到GDRL-FLAM模型不仅能够在简单场景中准确掌握选址策略,而且成功将这些策略迁移到更为复杂的场景中。这证实了模型在不同场景和复杂度下的灵活性和适应性,为其在实际应用中提供了更广泛的适用性。最后,在实际案例研究中,GDRL-FLAM模型在距离改善方面相对于GA实现了1.01%到10.75%的显著提升。
尽管本研究在公共服务设施选址问题上取得了显著的成果,但同时也存在一些局限性。首先,该模型仅考虑了单一目标,并且目标函数相对简单,未能涵盖多目标和多约束情境。未来的研究将致力于拓展模型复杂性,引入更多真实场景中常见的多目标和多约束条件,以更贴近实际的选址决策需求。其次,本研究中使用的训练数据仅基于随机生成的位置点集,尚未考虑其他类型的地理空间要素。下一步的研究将致力于基于真实的、多源的地理空间数据进行训练,以提高模型在实际场景中的泛化能力和适应性。