研究背景
作为全球物质循环的重要组成部分,降水在大气圈、水圈和生物圈中扮演重要角色,对地表径流、植被分布和土壤水分影响显著,准确的降水资料对于区域甚至全球的水平衡计算和气候变化都至关重要。
青藏高原以其独特的高海拔地理环境和错综复杂的气候条件著称,青藏高原腹地作为两大环流系统交汇处,其降水时空分布尤为复杂多变。目前,地面站点观测数据被认为是最准确的降水资料,但受布设数量和范围限制,反映降水的空间代表性有限,利用稀疏站点插值得出的降水数据精度亦难以保证。
卫星降水产品挑战
卫星遥感技术受到算法、传感器性能以及云层等限制,在气候下垫面复杂区域精度表现仍不够理想。另外,与卫星像元尺度相比,区域内的降水可能发生在更精细的尺度上,因此获取更高时空分辨率的降水数据至关重要。
研究方法创新
本研究提出物理和统计模型相结合的降水订正方法,针对高原腹地海拔高、风速大特点,引入风效应指数量化模拟降水效应;为降低卫星像元与站点空间尺度相差较大而带来的订正误差,对0.1° IMERG日降水数据先降尺度至1 km再订正。
研究方法
本研究基于地形降水效应,考虑云与降水之间的紧密关系,提出由地形风效应和随机森林模型结合的降尺度订正方法。
基于地形风效应的IMERG降尺度
山脉迎风面湿润气流抬升引起的地形降水和背风面的雨影效应是影响小尺度降水最常见的效应,基于风向及高程数据,利用风效应指数对其参数化。
风效应指数计算公式:
H = HW × HL
其中HW为迎风分量,HL为背风分量,通过边界层高度订正得到最终的风效应指数HB。
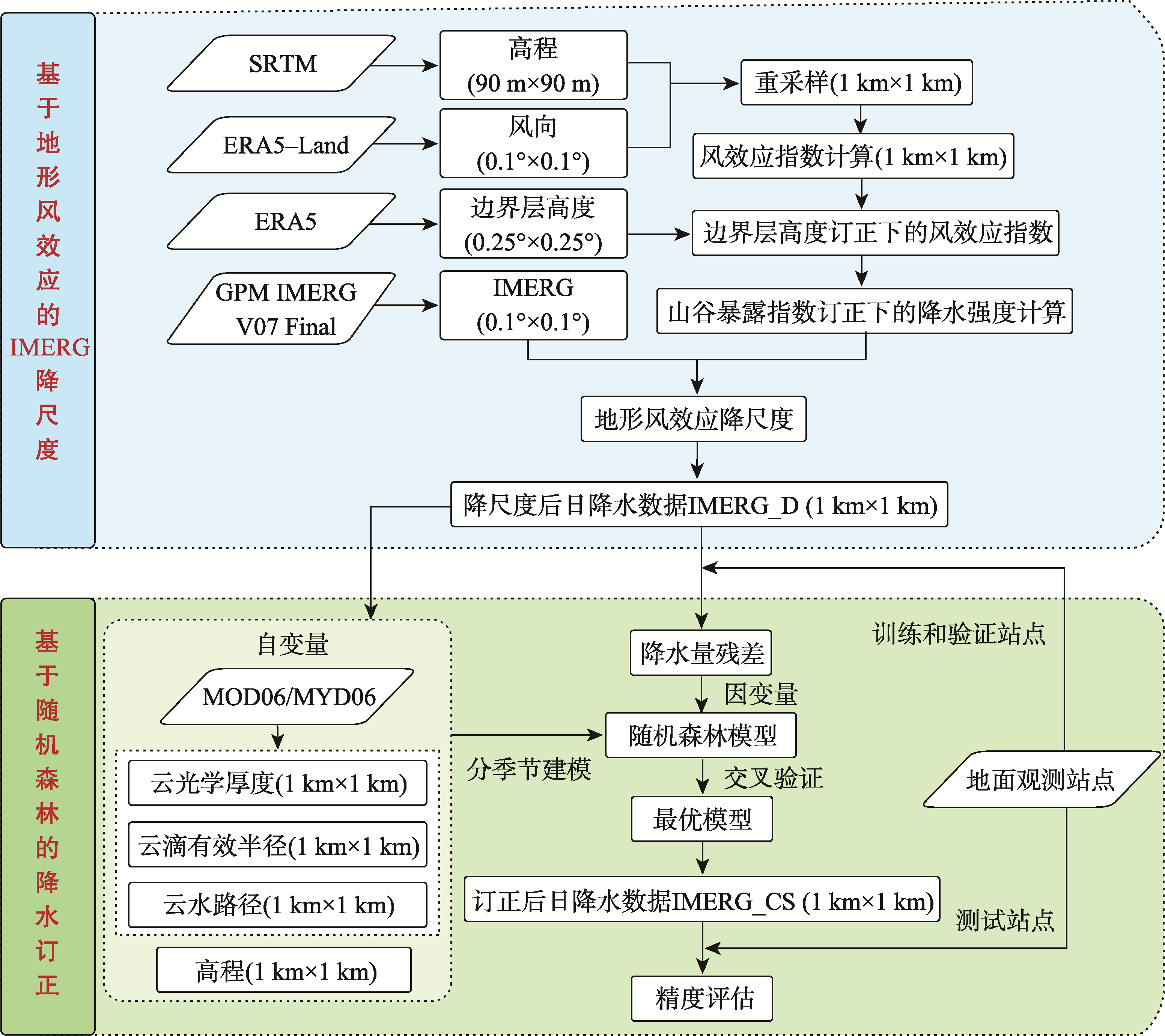
图1 IMERG降尺度订正流程
基于随机森林的降水订正
数据划分
将研究区内共20个站点数据分为17个训练/验证站点和3个测试站点。
模型建立
计算实测日降水与IMERG降尺度残差,以环境变量为自变量,通过随机网格搜索与五折交叉验证优化模型参数。
数据订正
将自变量数据输入最优模型中,预测面状降水量残差值,再与降尺度后日降水数据相加,得到订正后的日降水数据。
| 参数 | 含义 |
|---|---|
| max_depth | 单颗决策树的最大深度,控制树的生长 |
| max_features | 每次分裂时考虑的最大特征数 |
| min_samples_leaf | 叶子节点所需的最小样本数 |
| min_samples_split | 内部节点再划分所需的最小样本数 |
| n_estimators | 决策树的数量 |
| bootstrap | 是否在构建树时使用自助法有放回抽样 |
研究区概况与数据来源
研究区概况
本文选取青藏高原腹地(30 °N—38 °N,88 °E—96° E)为研究区,该区域平均海拔在4 000 m以上,属于典型的高原山地气候。
腹地内32 °N左右有一条东西向的南北风切变线,是青藏高原南北分界的重要标志。不同季节高原腹地盛行风不同,夏季30 °N—35 °N区域南风与西南```html
研究区地貌丰富多样,涵盖高原、山地、盆地、丘陵及河谷等多种类型,冰川、冰缘及湖泊等地貌形态交织共存。全年气温低、降水少。
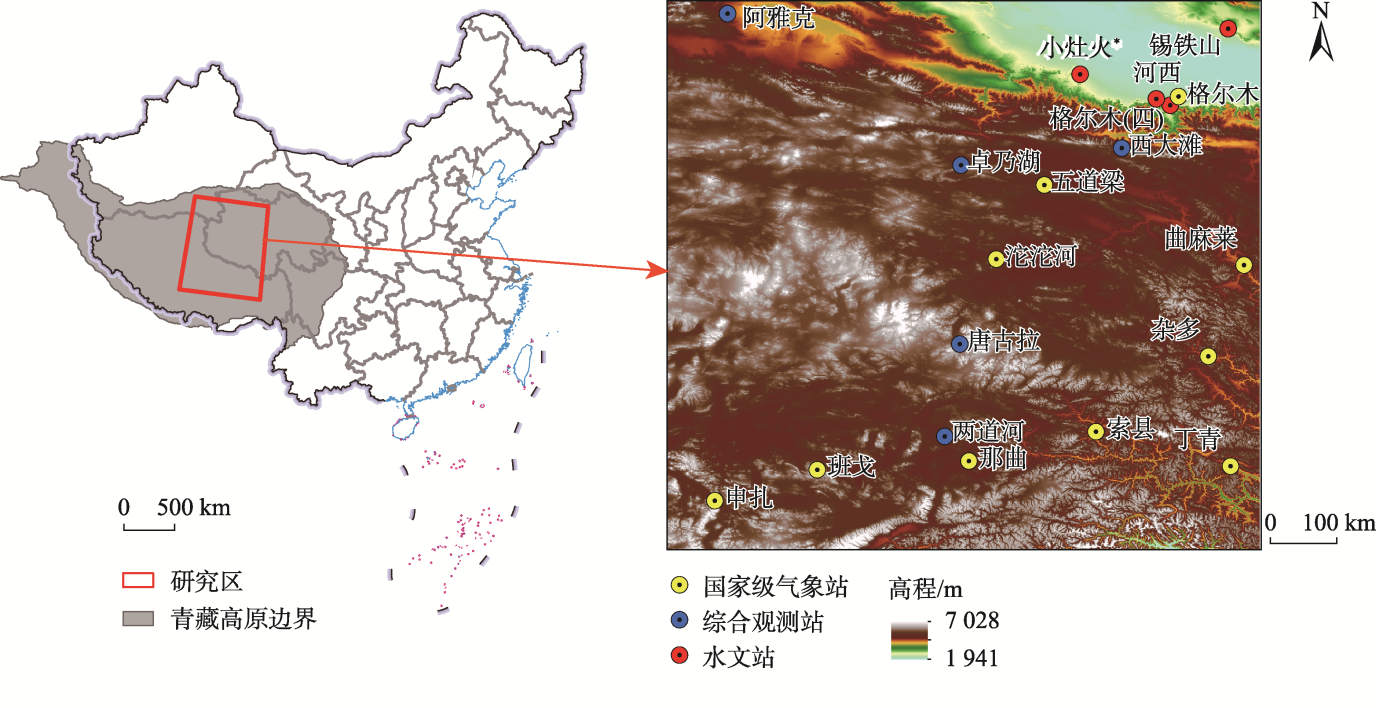
图2 青藏高原腹地站点分布
数据来源
| 站点类型 | 站名 | 经度/°E | 纬度/°N | 高程/m |
|---|---|---|---|---|
| 国家级气象站 | 大柴旦 | 95.37 | 37.85 | 3 174 |
| 格尔木 | 94.90 | 36.42 | 2 809 | |
| 五道梁 | 93.08 | 35.22 | 4 613 | |
| 班戈 | 90.02 | 31.37 | 4 701 | |
| 那曲 | 92.07 | 31.48 | 4 508 |
| 数据类型 | 数据名称 | 时空分辨率 | 数据来源 |
|---|---|---|---|
| 降水产品 | IMERG | 天/0.1° | GPM IMERG V07 Final |
| DEM | 90 m | SRTM | |
| 风向 | 小时/0.1° | ERA5-Land |
结果与分析
基于地形风效应的降尺度结果分析
与地面实测降水相比,降尺度后(IMERG_D)相较于原始IMERG(IMERG_O),总体上表现出更高的相关性(R提升0.02)和更低的误差(RMSE降低7.50%,MAE降低6.45%)。
原始IMERG存在"低值高估、高值低估"及较多离群点问题。与之相比,IMERG降尺度后对低值高估的现象有明显改善,这主要是由于通过引入风效应指数,在高精度DEM基础上,考虑了1 km尺度下背风坡和高山地区极端孤立的山谷降水。
主要发现:
- 除格尔木外,IMERG降尺度后R值均有所提升,为0.01~0.06
- 所有站点位置RMSE均降低,75%站点降幅超0.10 mm/d
- 中南部误差减幅显著,北部较小,这与中南部海拔高、地形变化大、风速大有关
基于随机森林模型的订正结果分析
考虑到降水主导因素及IMERG降尺度后结果在各季节均有所差异,实验按照春季(3—5月)、夏季(6—8月)、秋季(9—11月)、冬季(12—次年2月),分别建立随机森林模型。
| 时间 | max_depth | max_features | min_samples_leaf | min_samples_split | n_estimators |
|---|---|---|---|---|---|
| 春季 | 5 | 2 | 8 | 10 | 320 |
| 夏季 | 9 | 3 | 8 | 6 | 120 |
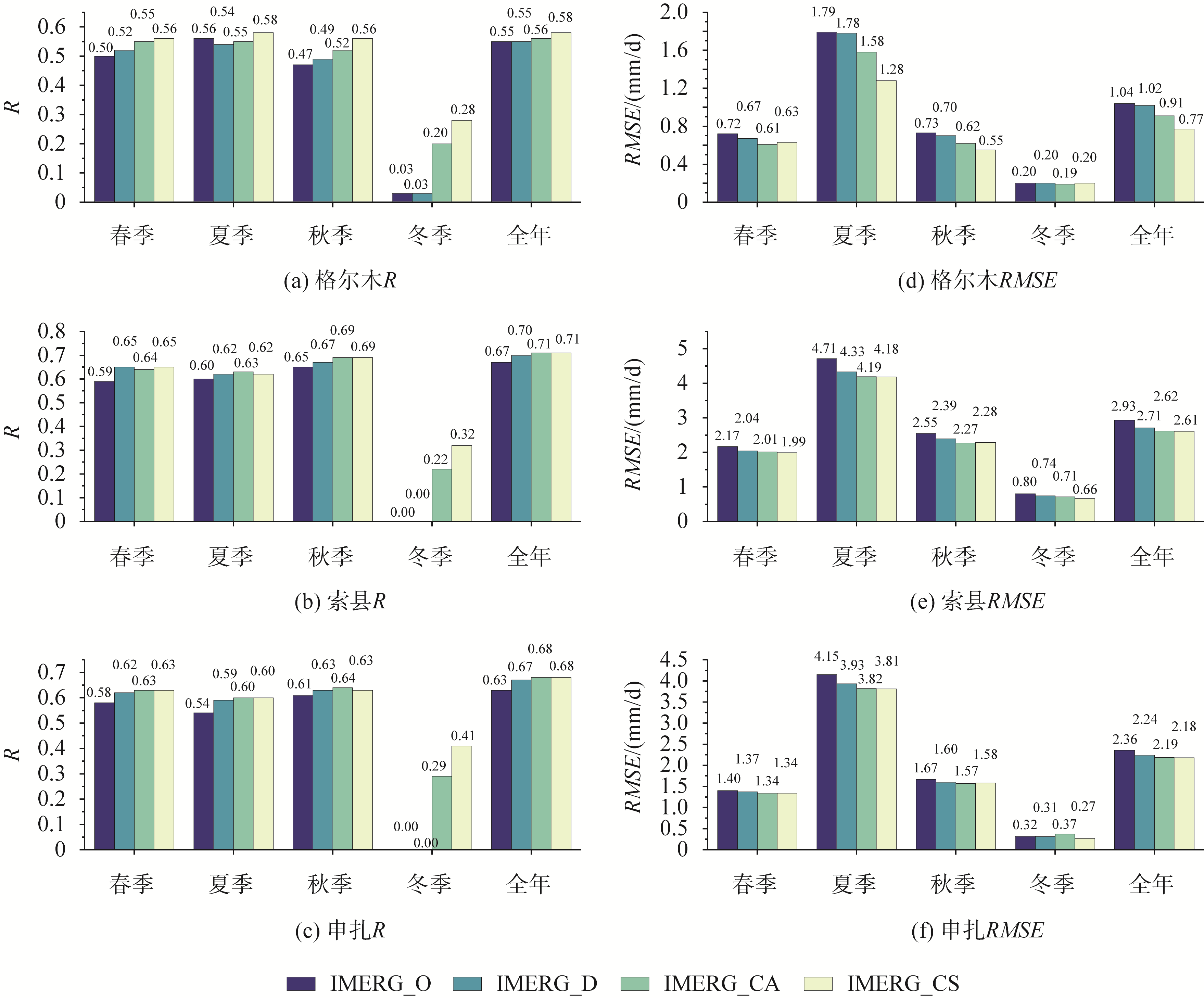
图3 分季节测试站点位置日降水数据精度评价
主要结论:
各协变量对降水重要性分析
利用随机森林算法评估各变量对降水订正的重要性。总体上CWP对降水影响最为显著,COT次之,高程作为恒定变量影响最低。各季节变量影响存在差异:
- 春季:CWP影响最大,COT次之,高程最小
- 夏季:高程影响显著上升,其次是COT,CWP因降水量大可能接近饱和而影响减弱
- 秋季:排序为COT > CWP > 高程 > CER
- 冬季:CWP最为重要,CER次之,高程影响最低
这些差异支持了分季节建模的优越性。

图4 季节尺度各协变量对降水订正的重要性
讨论
与既有IMERG订正研究对比分析
| 文章 | 参考数据 | 方法 | 建模数据 | 订正目标 |
|---|---|---|---|---|
| 本文 | 站点观测降水 | 物理机理与统计模型相结合 | 训练/验证站点位置数据、高程和云属性数据 | 对无站点位置IMERG订正 |
| 杜鹃等[15] | CMFD | 统计模型(Delta分位数映射法) | 历史时段IMERG降水数据 | 对其它时段进行订正 |
不确定性讨论
站点观测数据限制
青藏高原独特的地理环境导致对降水尤其是固态降水的捕捉能力受限,观测值普遍偏低,直接削弱了订正结果的精度。
模型样本均衡问题
青藏高原腹地降水量普遍偏低,极端降水事件尤为罕见,导致模型对强降水事件的模拟不足,影响强降水事件的订正精度。
云属性数据完整性
云属性数据的缺失与不完整性限制了模型性能的充分发挥,特别是在夏季强降水期间,云层的饱和状态减弱了对降水过程的直接影响。
方法普适性验证
当前研究成果主要聚焦于青藏高原腹地区域,其在复杂多变地形和气候条件下的普适性和稳定性尚待全面验证。
结论
本研究以青藏高原腹地资料稀缺区为研究区域,依托站点观测降水数据,构建了一种物理机理与统计模型相结合的IMERG降尺度订正方法:
以站点观测数据为基准,订正IMERG降水
物理机理与降尺度技术的融合。考虑迎风坡降雨背风坡雨影的地形降水效应,将风效应指数融入降尺度过程中
环境因子与降水数据的耦合订正。通过整合云属性及高程等多源环境因子,构建了多源信息融合的降水订正框架
分季节建立随机森林模型,生成了2003-2022年1 km日降水数据
主要结论:
- 经过地形风效应降尺度后的日降水数据,在提升降水细节信息的同时数值精度得到提高,R提升0.02,RMSE降低7.5%
- 分季节的随机森林订正算法在各时间尺度各站点均明显提升了高原腹地降水量精度
- 不同季节各协同因子对降水的影响程度不尽相同,总体上云水路径作为关键因素,对降水的影响最为突出
- 该模型可为其他地形复杂、降水资料稀缺区降水订正提供参考,对青藏高原腹地水资源研究提供科学依据