引言
建筑物作为基础地理要素的重要组成部分和空间研究的主要对象,其形状相似性度量为地理空间认知和地图制图综合提供了理论依据。形状相似性作为空间相似关系研究的一部分,用以描述地理要素和地图目标之间的关系,同时表达了现实与地图之间的联系。
由于建筑物形状的多样化及复杂性使得地图综合困难,获取建筑物形状信息是必不可少的一环。并且,形状相似性度量为地理空间提供基础信息,为建筑物空间模式识别、查询、匹配、检索和制图综合提供技术支撑。
地理空间要素的相似性研究涵盖了多种分析方法:点要素主要集中于建筑物点群模式分析和矢量建筑物群聚类;线要素包括河网模式识别、基于几何特征的等高线匹配和轨迹线相似性分析;面状要素涉及建筑物同名实体匹配、建筑物形状化简、形状分类和空间检索等。
传统的矩变换或傅里叶变换方法通常会捕获建筑物几何轮廓的全局特征,但可能忽略局部特征,转角函数专注于局部特征而忽略形状的整体信息;监督学习需要大量的标注数据,成本较高;栅格数据通常会占用大量的存储空间,并且也需要大量的计算资源去进行计算和处理数据;图对比方法可以更好地捕捉到轮廓的局部特征和全局特征,提供了更全面的相似性度量方法。
基于图对比学习的建筑物形状相似性度量
2.1 图对比学习模型
对比学习作为一种自监督学习范式,在计算机视觉、自然语言处理等领域取得了广泛的应用。将对比学习模型引入图域,典型的图对比学习范式包括监督表示学习、无监督预训练、辅助学习3种方式。此类方法强调对图结构的编码,将相似的图或节点映射到相似的表征空间中,同时将不相似的图或节点区分开来。
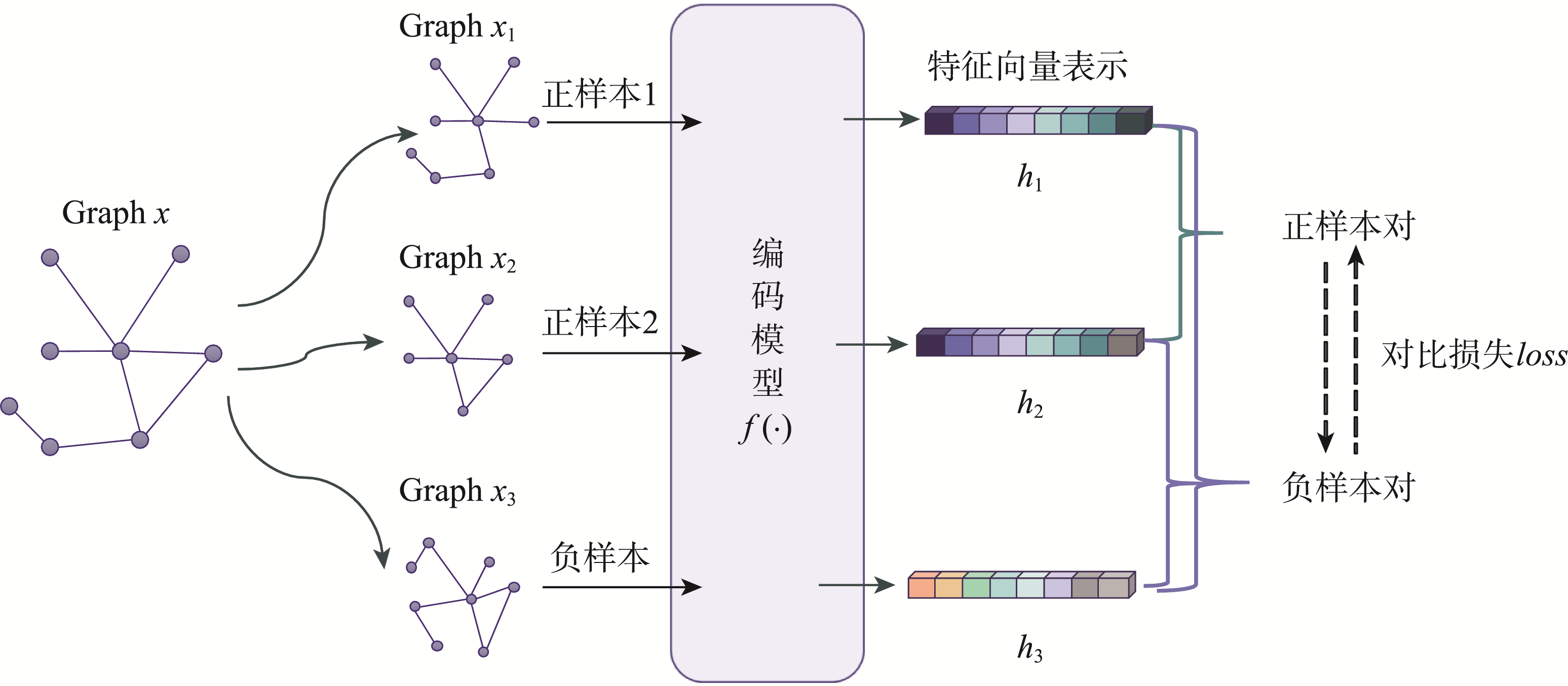
图1 图对比学习模型
2.2 对比损失函数
损失函数是用于度量模型预测结果与真实标签之间差异的函数。在深度学习中,损失函数是优化算法的核心组成部分,通过最小化损失函数来调整模型参数,使得模型能够更好地逼近或拟合训练数据。
对比损失用于学习嵌入表示,通过最大化正样本对的相似度和最小化负样本对的相似度,来提高嵌入表示的区分度,多图分类中使用InfoNCE loss。与其他对比损失函数不同,InfoNCE损失函数引入了归一化的因子,以解决样本数量不平衡的问题,从而提高模型的稳定性。InfoNCE loss公式如下:
loss = -log(exp(q∙k+/τ) / ∑i=0k exp(q∙ki/τ))
式中:q表示某个样本编码;k为一系列样本编码,其中一个样本编码k+与q互为正样本对,其余ki为q的负样本;q·k表示相似度得分;τ表示温度超参数,其作用是控制模型对负样本的区分度。
2.3 基于图对比学习的建筑物形状相似性度量方法
基于图对比学习理念,本文通过图编码器获取对建筑物形状的有效表达,以实现形状的相似性度量。在视觉认知中,可以从相似性高的形状中来类比同一类形状,并识别不同类别之间的差异,引申到图对比学习中,积极地利用相似性作为正样本的学习信号,并从负样本中学习如何区分不同类别,从而使模型更好地理解正负样本之间的差异。
本文采用图对比学习的通用框架(GCL范式),具体包括以下步骤:首先,构建特征图以描述建筑物形状的结构特征;其次,利用编码器将建筑物形状转换为高维特征向量表示;最后,通过余弦值度量建筑物形状之间的相似性。
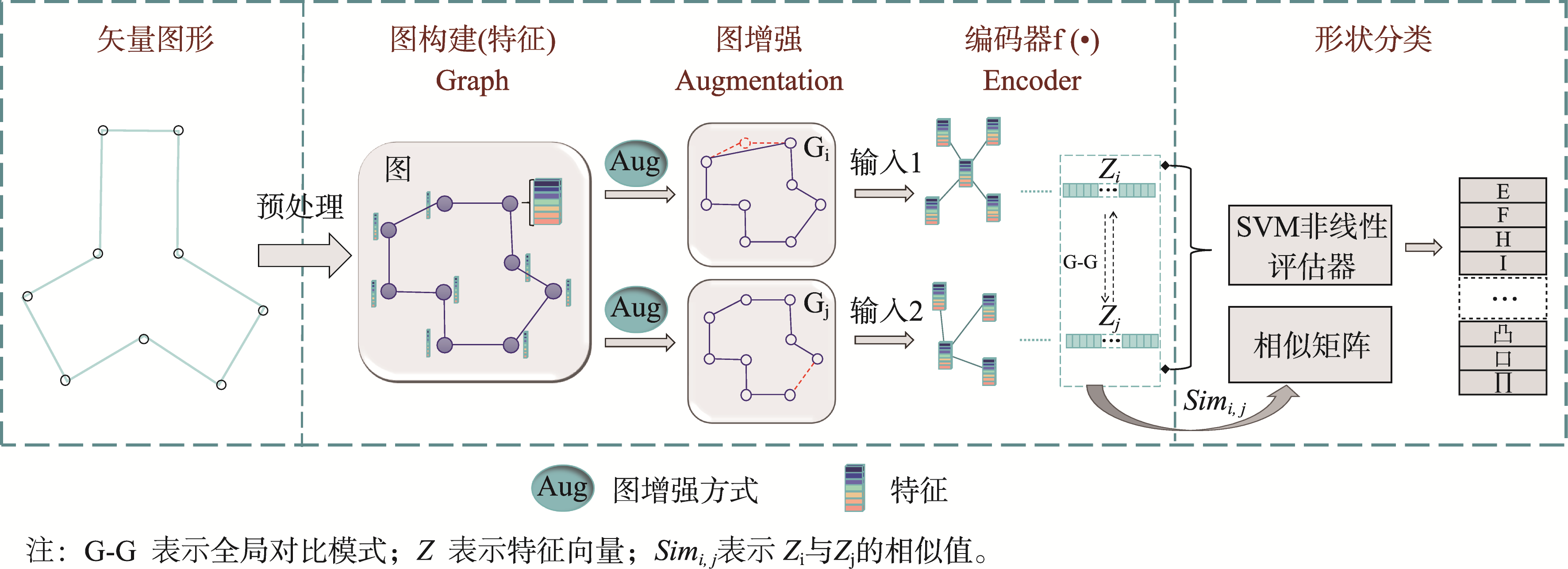
图2 建筑物相似性度量框架
2.4 特征提取
在构图前,利用设置较小阈值的Douglas-Peucker算法对矢量图形进行处理,以消除轻微抖动和移除冗余节点,并减少异常点的干扰。矢量图形与图结构存在结构上的相似,因此在构图时,将图形顶点作为图节点,边作为图节点连线。
由于形状的不确定性和差异性,几何特征的提取不仅要考虑局部的差异,还要顾及全局上的关联性。本文提取建筑物形状的局部特征和全局特征作为图特征,包括图节点特征和边特征,此表达不仅涵盖图的节点特征对,还顾及边特征对图的表达影响。
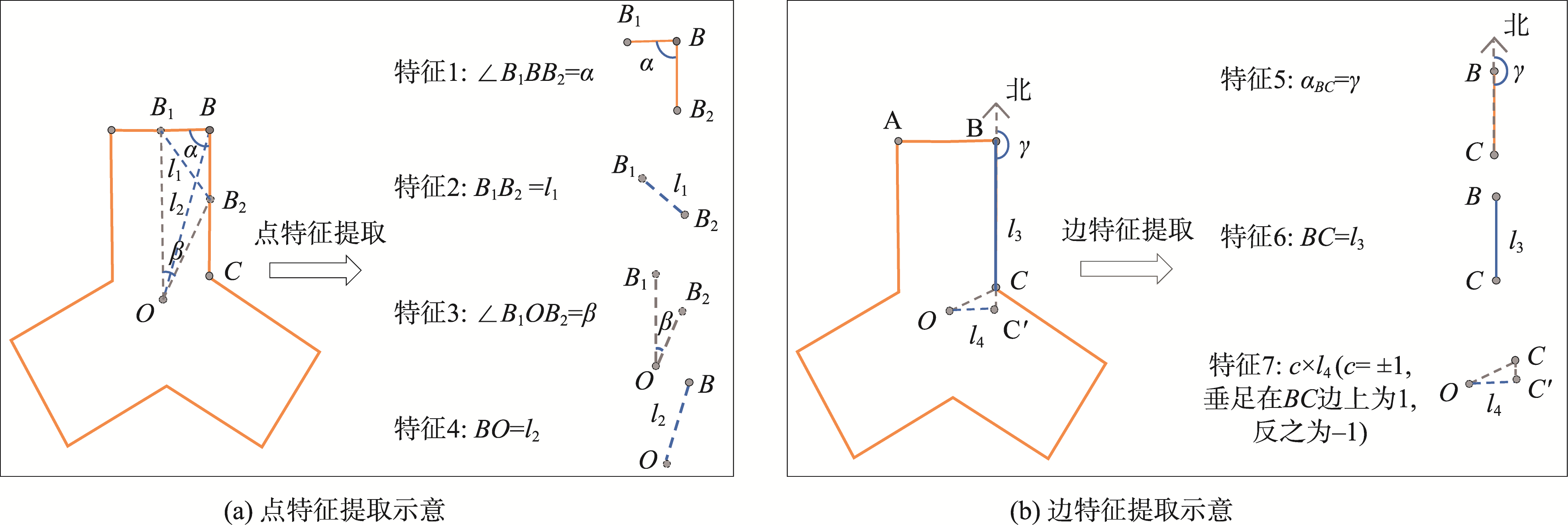
图3 特征提取示意图
2.4.1 点特征和边特征
点特征:由点B和邻边的2个中点B1、B2构成的三角形来描述点B的局部属性,点B和中心点O之间的位置关系来描述点B的全局属性。以B点的转折角α及角对应的边l1作为B点的局部特征,以中心点O到B点的距离l2和B点所对应的夹角β作为B点对应整个图形的全局特征。其局部特征反映某点相对于相邻边的关系,全局特征体现B点相对于多边形中心的位置。
边特征:使用方位角和长度描述边的相对位置和尺寸。以BC的方位角γ和距离l3描述边的局部属性,同时作中心点O到BC边垂线,判断垂足是否在BC边,以确定BC边相对于中心点的位置。若垂足在边上令c=1,反之令c=-1,最后得到特征值为c×l4,此特征为BC边相对于整个图形的整体特征。
2.4.2 特征归一化
由于建筑物形状的大小、方向和面积等不确定性,描述要满足平移、缩放、旋转、镜像等操作的不变性,而三角形的面积、周长、边长在进行缩放时会随之变化,因此需要对形状特征进行归一化处理。
长度特征与所在局部或整体图形的周长进行比值化,角度特征提取其与最大角度值π或2π作比。通过归一化,将形状多边形的节点特征固定在[0, 1]范围内,从而减少数据处理的复杂性和内存占用,提高模型训练的速度和精度。
ᾱ = α/π
l̄1 = l1/CB1BB2O
β̄ = β/π
l̄2 = l2/CB1BB2O
γ̄ = γ/2π
l̄3 = l3/C建筑物
l̄4 = c×l4/CΔBOC
建筑物形状分类及分析
3.1 数据准备和模型设置
3.1.1 数据准备
建筑物形状数据来源为OSM开源数据,采集不同大小和不同方向的建筑物形状,以形成多样化的样本数据,丰富形状训练样本。通过引入多样化的样本,可以提供更全面的训练数据和适应不同的特征和变异,增强模型对噪声和异常值的抵抗能力。
根据生活中的建筑物形状认知,将其分为15类,每类400个形状样本,共计6,000个样本,训练集和测试集以8∶2进行划分。基于英文字母形状的认知,包括E、F、I(长方形)、H、L、Y(三叉形),Z、O(圆形)、C(弧形);基于汉字形状的认知,包括凸字形(T)、凹字形(U)、十字形、艹字形、口(正方形);基于数学形状认知,包括长方形和正方形;其他特殊字符形状认知有Π字形。
3.1.2 模型设置
本文模型通过多层GIN(Graph Isomorphism Network)卷积层、标准化层、激活函数、全局池化层和投影层来增强形状的表达能力。
GIN层是一种图卷积层,专门用于处理图结构数据,其核心在于其聚合函数,通过对邻居节点特征进行求和聚合,并结合节点自身特征进行非线性变换,从而精确捕捉图的结构信息。在本文中由一个包含2个线性变换和ReLU激活函数的多层感知机(MLP)构成。
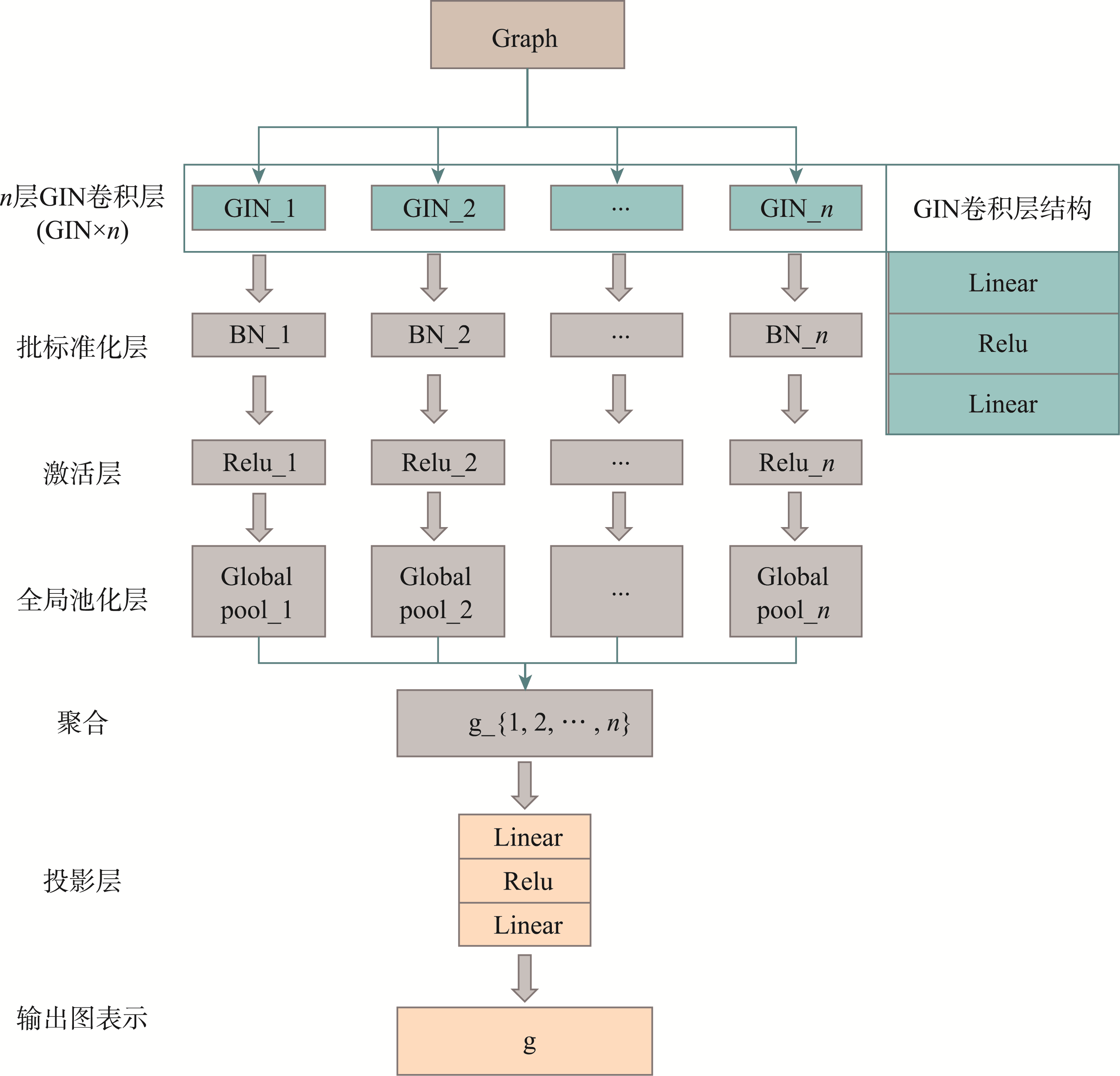
图4 图对比学习编码器架构
3.2 参数敏感性分析
参数是模型在训练过程中学习到的数值,对模型的表现和功能有着重要的影响,此部分将分析模型参数(批次大小、学习率、隐藏层维度和模型深度层数)对测试准确率的影响。
在本部分试验中,通过设置2组参数关系,即学习率与批次大小,以及隐藏层维度与模型深度进行了分析。具体设置为:学习率分别为0.01、0.001、0.0001和0.00001;批次大小为128、64、32和16;隐藏层维度为32、64、128、256;模型深度为2、3、4和5。
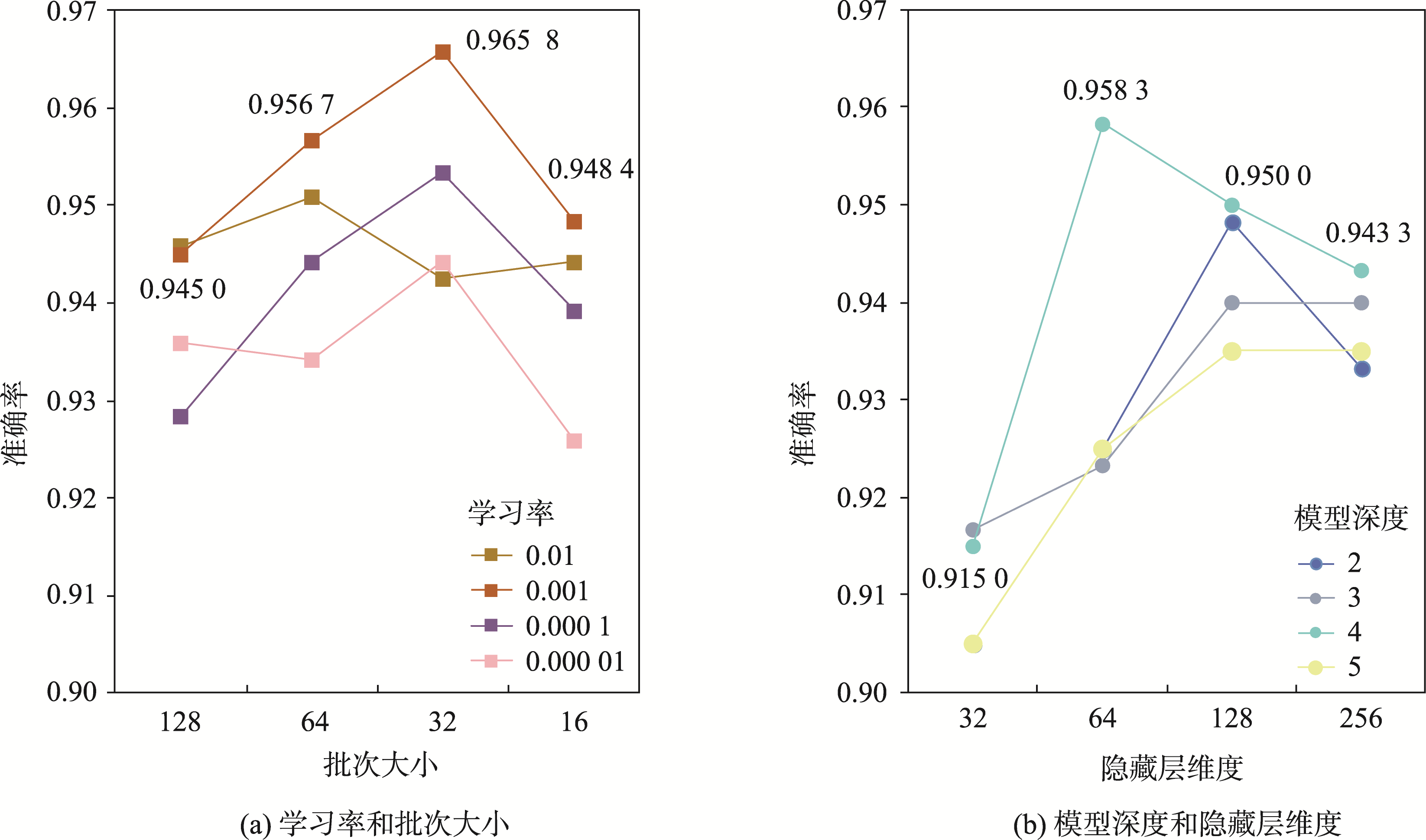
图5 参数组合的结果
3.3 图增强方式分析
图增强是图对比学习框架中非常重要的组成部分,可以为图提供更加丰富的上下文信息,有助于学习高质量的表征。其增强方式主要有节点丢弃(Node Dropping,ND),节点重排 (Node Shuffling,NS),特征丢弃(Feature Dropout,FD),特征掩码(Feature Masking,FM),边移除(Edge Removing,ER),边增加(Edge Adding,EA),随机采样(Subgraphs induced by Random Walks,RWS)等。
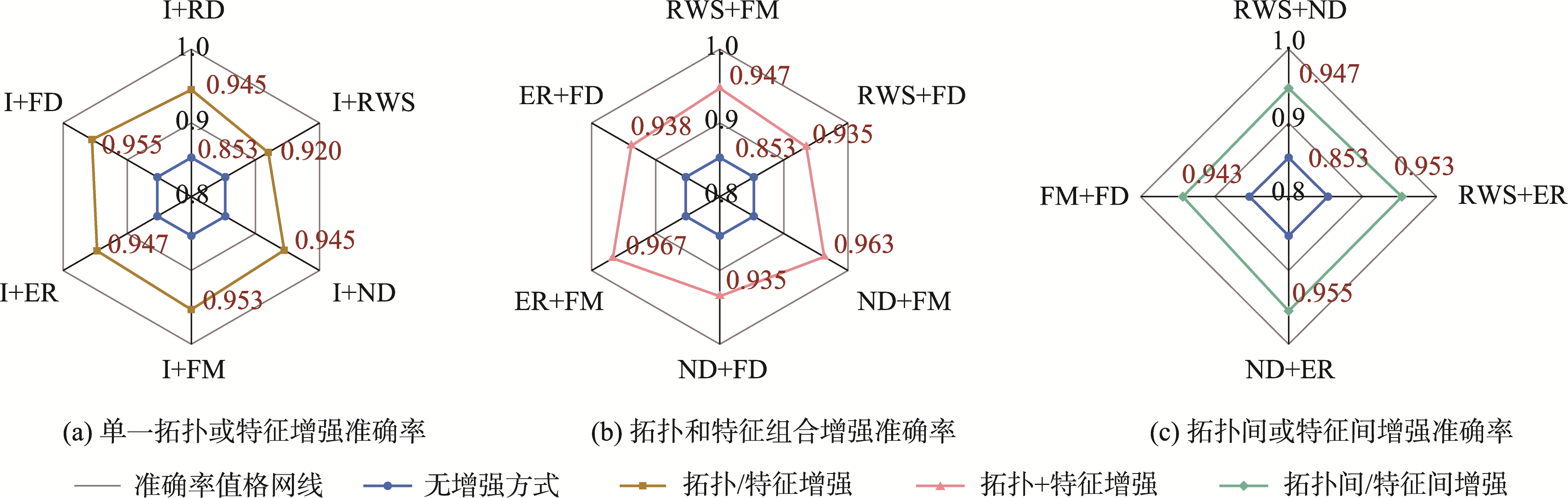
图6 图增强方式组合的结果
3.4 特征和节点方向分析
在此部分中,将对特征贡献度和节点方向对试验结果的影响进行了对比分析。试验设置包括单个特征、全特征以及形状节点方向顺时针(Clockwise,CW)和逆时针(CounterClockwise,CCW))的影响。
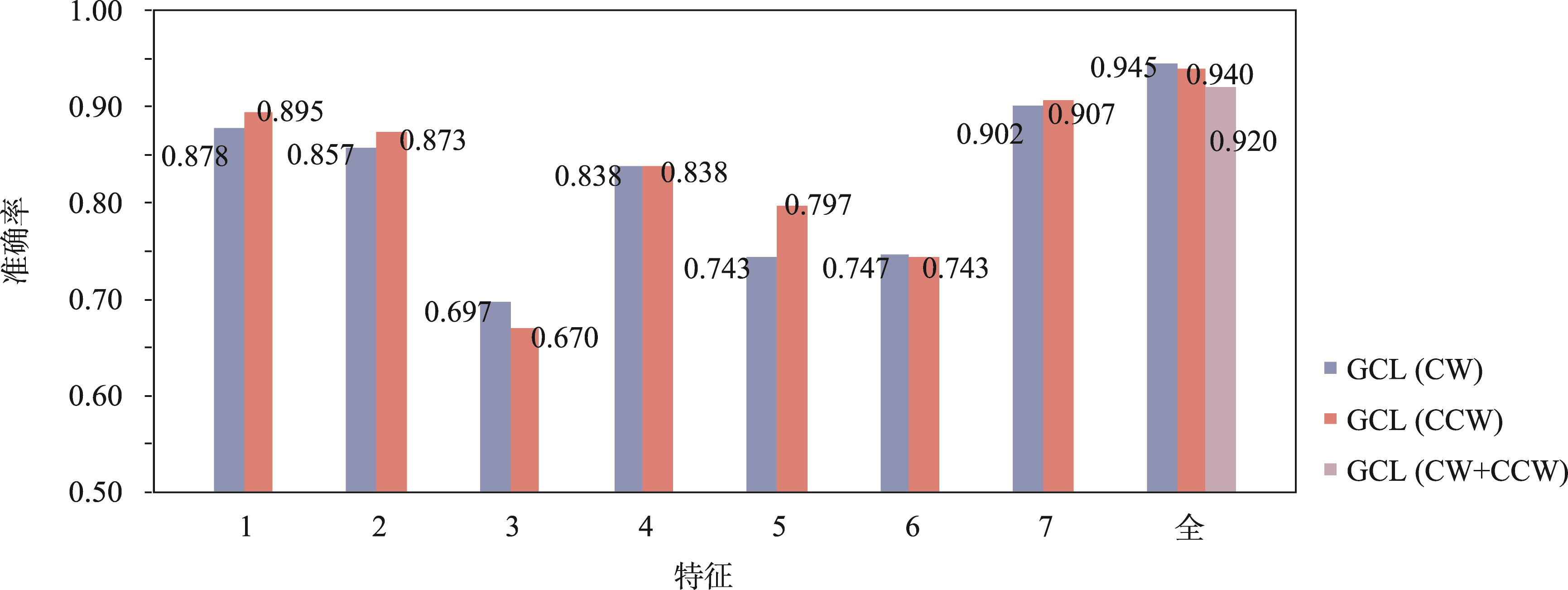
图7 特征和节点方向分析
3.5 方法比较
本部分进行对比试验,主要分为2个方面:① 传统方法实现,即傅里叶变换和矩变换方法;② 深度学习方法实现,即本文方法(GCL)与图自编码(GCAE)模型进行效果对比。
| 方法 | 分类准确率/% |
|---|---|
| 本文模型(GCL) | 96.7 |
| 图自编码(GCAE) | 92.5 |
| 傅里叶变换(K=20) | 44.4 |
| 矩变换(Hu矩) | 22.9 |
应用案例
本文基于图对比学习模型,依赖于图增强方式下的形状特征编码表示,以形状编码间的余弦值来度量建筑物形状之间的相似性。为了进一步验证本文方法在建筑物形状分类和相似性度量的可行性,在OSM选取香港3个地区的部分建筑物作为试验区域,共计574个形状测试样本,包括形状匹配样本33个。
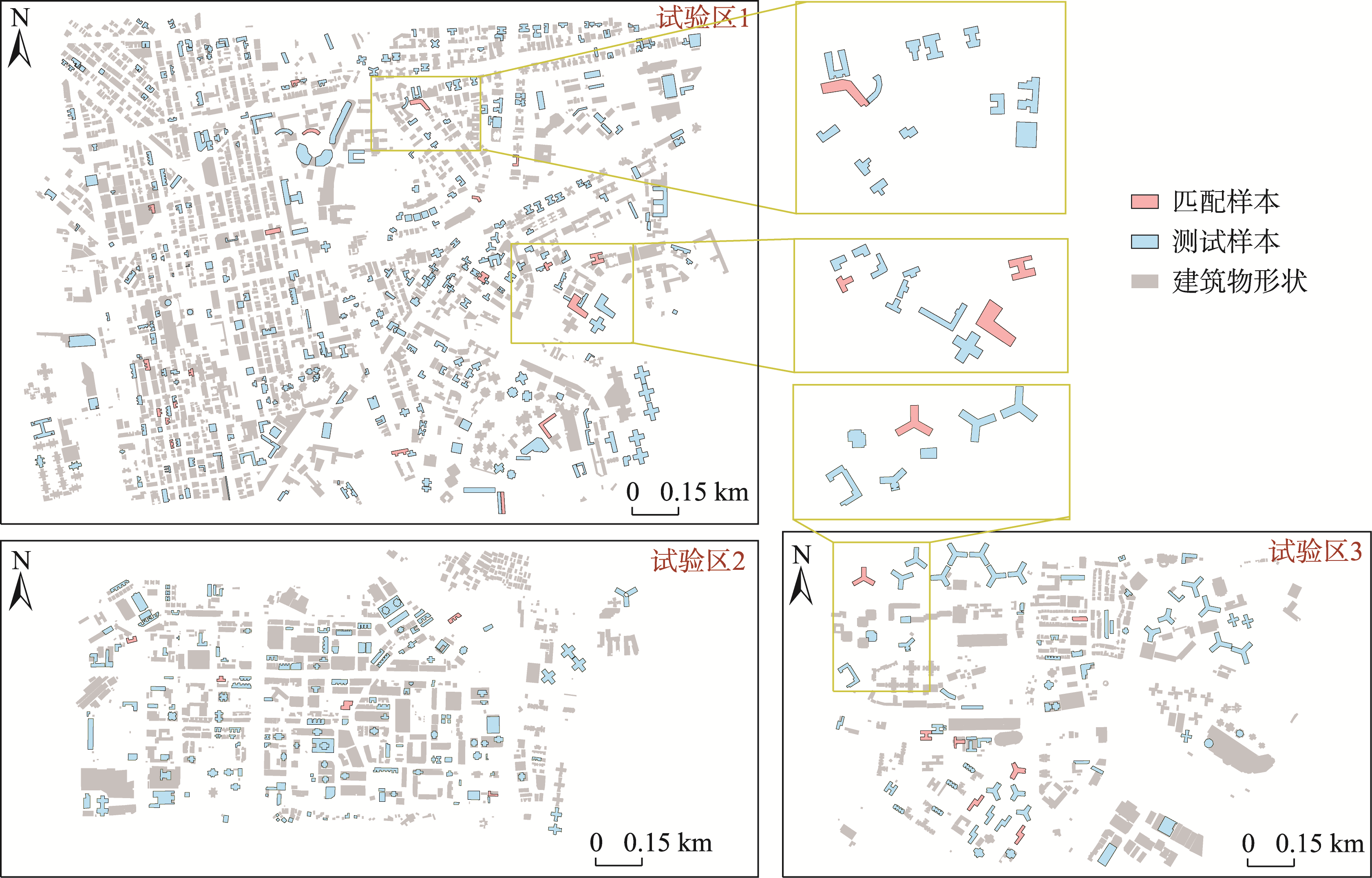
图8 建筑物试验区
4.1 形状分类
在试验区域运用本文模型进行分类后,分类矩阵显示本文模型的分类效果较好,多数建筑物形状可以被正确归类,整体分类准确率达到了95.7%,最高准确率为100%,最低准确率为86%。
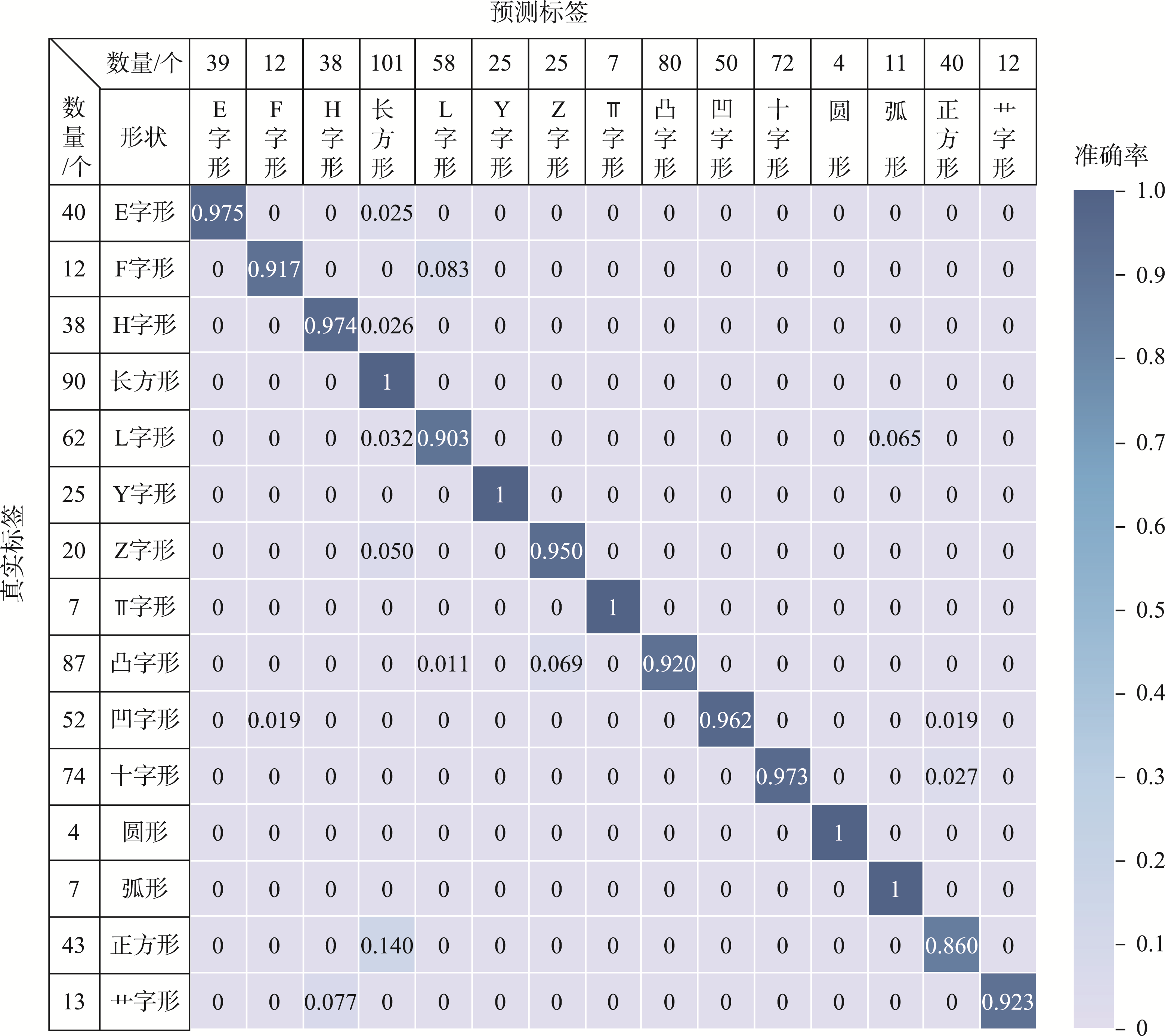
图9 形状分类结果统计
4.2 形状匹配
在此部分,通过编码器获取建筑物的形状编码,并计算这些形状之间的余弦相似度,以确定前5个最相似的形状。余弦值越高,表示形状越相似,反之越不相似。
结论
实现对建筑物形状进行分类和相似性计算,可以更好地理解和认知地理空间实体,并构建空间相似框架。本文提出了一种基于图对比学习模型的建筑物形状相似性度量方法,利用图结构和特征使用图增强策略实现建筑物形状的深层次信息获取,从而为建筑物形状相似性度量带来更好的认知支撑。研究结果表明:
- 通过参数调整,本文方法的试验准确率达到96.7%,高于传统的HU矩方法(22.9%)和傅里叶方法(44.4%),并与同类深度学习GCAE方法(92.5%)相比,也提高4.2%左右。
- 图增强方式使得图对比学习模型可以学习到形状的上下文信息,有助于学习高质量的表征。无增强方式的准确率为85.3%,使用增强策略的准确率都在92.0%以上,说明图增强方案带来了效果的显著改进。
- 选取了香港3个典型建筑物形状试验区进行形状分类和形状匹配试验,整体的形状分类准确率为95.7%,并对9个典型形状进行相似性匹配,结果显示同类形状的相似值远大于非同类形状。
尽管本文模型在建筑物形状识别方面表现较好,但是在处理复杂和相近形状时仍面临数据量大和特征多样化的问题。后续研究可以考虑去除数据增强策略和负样本对比方式,以降低训练成本,或者优化增强方式,保留主要贡献的增强方式,剔除贡献小或者无贡献的部分,从而精简模型。
结论
本文提出的基于图对比学习的建筑物形状相似性度量方法,通过创新的特征提取和模型架构,在地理信息科学领域取得了显著成果。主要贡献和创新点可总结如下:
方法创新
- 首次将图对比学习框架应用于建筑物形状相似性度量
- 设计了结合局部和全局特征的多层次特征提取方法
- 开发了高效的图增强策略组合
性能突破
- 分类准确率96.7%,远超传统方法
- 形状匹配结果与人类视觉感知高度一致
- 有效处理了复杂形状的识别问题
应用价值
地图制图综合
空间查询检索
形状匹配分析
未来展望
尽管取得了显著成果,本研究仍存在一些可以改进的方向:
- 优化图增强策略,减少不必要的计算开销
- 探索更高效的特征提取方法,降低模型复杂度
- 扩展应用到更大规模的地理数据集
- 研究跨领域迁移学习的可能性
* 以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。