研究方法
1 技术路线
本文技术路线由3个部分组成:首先,对Landsat图像进行处理,通过时序数据获得各指数的分位数等数据;其次,对云量小于50%的图像进行目视解译,获得样本点;最后,采用随机森林算法分类,进行后处理与精度评价。
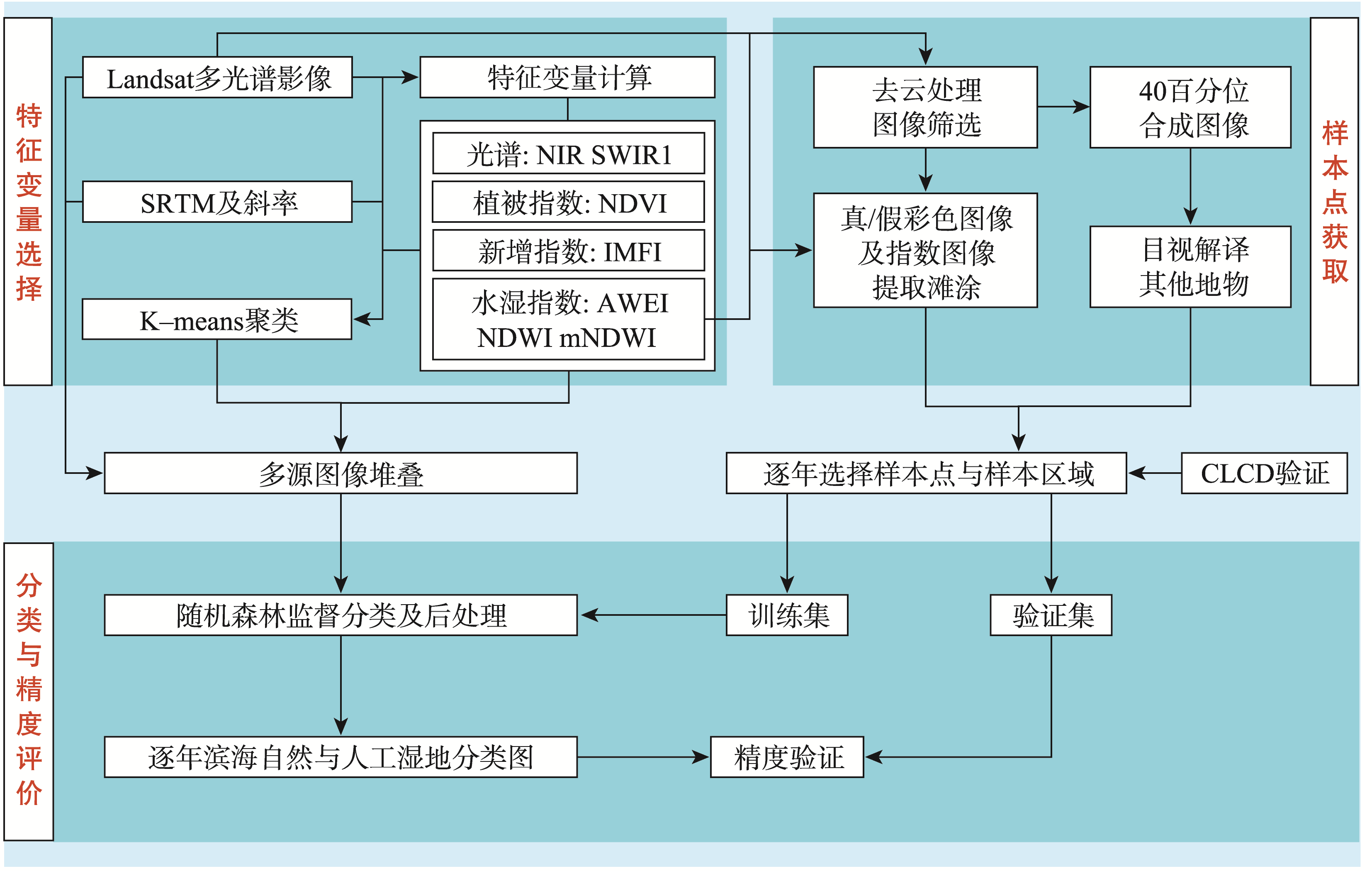
图1 滨海湿地监测分类流程
2 算法特征变量选择
本文在Murray等(2019)方法的基础上,添加IMFI并结合K-means算法的聚类结果,利用其中的蓝波段增强对水下信息和浑浊水体的识别,提高湿地类间的区分度。
IMFI计算公式如下:
IMFI = (BLUE + GREEN - 2 × NIR) / (BLUE + GREEN + 2 × NIR)
式中:BLUE、GREEN、NIR分别表示Landsat卫星的蓝、绿、近红外波段。
| 特征指数 | 对应指标名称 |
|---|---|
| AWEI、NDWI、mNDWI | p10, p25, p50, p75, p90, stdDev, max, min, median, intMn1090, intMn0010, intMn1025, intMn1090, intMn2550, intMn2575, intMn5075, intMn90100 |
| NIR, SWIR1, NDVI | intMn1090 |
| 地形数据 | DEM, slope |
| IMFI | p10, p25, p50, p75, p90, stdDev |
| K-means | cluster |