1 引言
微地图是面向大众的"草根"地图,在传播上具有及时、方便、快捷的特性,其投入使用后势必产生海量数据,可能产生因信息量过载,用户无法准确挑选与运用有效信息的问题。为解决此问题且充分挖掘微地图数据中潜藏的社会经济价值,在微地图传播过程中个性化推荐就很有必要。
已有的微地图推荐算法通过基于矩阵分解的协同过滤进行推荐,在推荐过程中仅利用了用户的身份标识号和对地图的评分,未充分利用其他特征。因此,推荐结果的准确率有待提高。如何利用用户和地图的其他特征提升准确率是当前微地图推荐中一个亟待解决的问题。
近年来基于深度学习的推荐方法已成为主流。目前应用较多的深度学习算法主要包括基于特征交叉的推荐方法和基于用户历史行为序列的推荐方法。基于特征交叉的推荐方法虽然能实现更高阶的显性和隐性特征组合,但往往无法自动习得各特征组合的权重,模型泛化能力增强的同时记忆能力变差。此外,基于特征交叉的推荐算法挖掘出的用户兴趣往往是静态的,忽略了用户动态兴趣对推荐结果的影响。
本文针对现有微地图推荐算法未充分挖掘用户与微地图特征,推荐结果准确率较低的问题,提出融合特征交叉与用户历史行为序列的微地图推荐算法。该算法融合了特征交叉和用户历史行为序列两种方法的优点,通过引入跳跃连接和多头自注意力机制增强特征交叉能力,通过引入交叉注意力机制捕捉用户动态兴趣,从而提高推荐准确率和可解释性。
2 相关工作
2.1 基于特征交叉的推荐方法
基于特征交叉的推荐方法主要通过挖掘用户特征与物品特征之间的交互关系来进行推荐。目前应用较多的基于特征交叉的推荐方法主要有:
Wide&Deep模型
包含Wide和Deep两部分,Wide是广义上的线性模型,能增强记忆能力但依赖于特征工程;Deep聚焦挖掘特征间深层次关系,具有强泛化能力。
DeepCrossing模型
引入"嵌入(Embedding)+多层神经网络"实现特征间深度交叉,避免了人工参与特征工程。
AFM模型
将注意力机制和因子分解机的思想进行了结合,通过将特征进行交叉组合,有效地处理了稀疏特征,提升了模型的泛化能力。
NFM模型
基于神经网络的因子分解机模型,通过引入神经网络结构来改进传统的因子分解机,能够捕捉到更复杂的特征交互,提升了模型的表达能力。
以上方法虽然能实现更高阶的显性和隐性特征组合,但往往无法自动习得各特征组合的权重,模型泛化能力增强的同时记忆能力变差。此外,基于特征交叉的推荐算法挖掘出的用户兴趣往往是静态的,忽略了用户动态兴趣对推荐结果的影响。
2.2 基于用户历史行为序列的推荐方法
基于用户历史行为序列的推荐方法主要通过分析用户的历史行为序列来捕捉用户的兴趣变化,从而进行个性化推荐。这类方法能够更好地捕捉用户的动态兴趣,提高推荐的准确性。
目前,基于用户历史行为序列的推荐方法主要有DIN(Deep Interest Network)、DIEN(Deep Interest Evolution Network)、SIM(Search-based Interest Model)等。这些方法通过不同的机制来建模用户的兴趣演化过程,从而提高推荐的准确性。
然而,这些方法在建模用户兴趣时往往只考虑了用户的历史行为序列,而忽略了用户与物品之间的特征交互关系,导致推荐结果的准确性和可解释性有限。
3 融合特征交叉与用户历史行为序列的微地图推荐模型
3.1 模型总体架构
本文提出的融合特征交叉与用户历史行为序列的微地图推荐模型主要包括三个模块:特征交叉模块、用户历史行为序列模块和融合模块。模型的总体架构如图1所示。
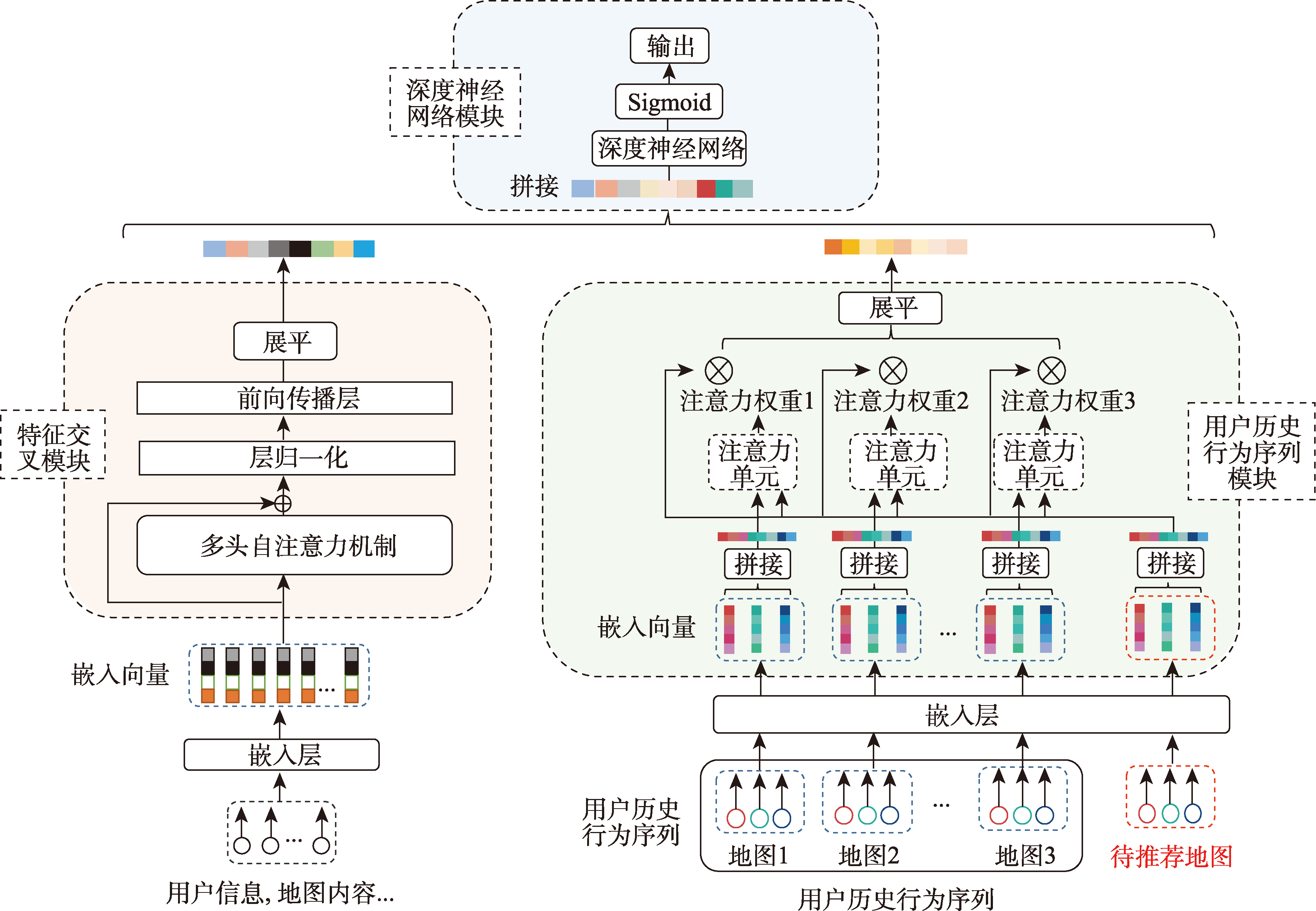
图1 融合特征交叉与用户历史行为序列的微地图推荐模型架构
模型的输入包括用户特征、地图特征和用户历史行为序列。特征交叉模块负责挖掘用户特征与地图特征之间的交互关系;用户历史行为序列模块负责捕捉用户的动态兴趣;融合模块则将两个模块的输出进行融合,得到最终的推荐结果。
3.2 特征交叉模块
特征交叉模块主要负责挖掘用户特征与地图特征之间的交互关系。为了增强特征交叉能力,本文在特征交叉过程中引入了跳跃连接和多头自注意力机制。
特征嵌入
首先,将用户特征和地图特征通过嵌入层转换为低维稠密向量,得到用户嵌入向量和地图嵌入向量。
多头自注意力机制
将用户嵌入向量和地图嵌入向量拼接后,通过多头自注意力机制进行特征交叉。多头自注意力机制可以让不同特征组合在多个子空间下进行交互,获得更丰富的特征组合信息。
其中,Q、K、V分别表示查询矩阵、键矩阵和值矩阵,dk表示键的维度。
跳跃连接
为了避免模型退化问题,本文在特征交叉过程中引入了跳跃连接。跳跃连接可以将低阶特征交叉和高阶特征交叉结合起来,保证模型的有效性。
其中,Hl表示第l层的输出,F(Hl, Wl)表示第l层的残差映射,Wl表示第l层的权重参数。
3.3 用户历史行为序列模块
用户历史行为序列模块主要负责捕捉用户的动态兴趣。为了更好地捕捉与候选地图相关的兴趣点,本文在用户历史行为序列中引入了交叉注意力机制。
序列嵌入
首先,将用户的历史行为序列通过嵌入层转换为低维稠密向量序列,得到用户历史行为序列嵌入。
交叉注意力机制
通过交叉注意力机制,将候选地图作为查询,用户历史行为序列作为键和值,计算注意力权重,从而捕捉与候选地图相关的兴趣点。
其中,Q表示候选地图的嵌入向量,K和V表示用户历史行为序列的嵌入向量。
3.4 融合模块
融合模块负责将特征交叉模块和用户历史行为序列模块的输出进行融合,得到最终的推荐结果。
特征融合
将特征交叉模块的输出和用户历史行为序列模块的输出拼接起来,通过深度神经网络进行融合。
预测输出
最后,通过多层感知机(MLP)将融合后的特征映射到最终的预测概率。
其中,σ表示sigmoid激活函数,ŷ表示预测的点击概率。
3.5 模型训练
模型采用二元交叉熵损失函数进行训练,损失函数定义如下:
其中,N表示样本数量,yi表示第i个样本的真实标签,ŷi表示第i个样本的预测概率。
为了防止过拟合,模型还采用了L2正则化和Dropout技术。L2正则化通过在损失函数中添加权重的L2范数来惩罚大的权重值,Dropout则通过在训练过程中随机丢弃一部分神经元来防止过拟合。
4 实验与结果分析
4.1 实验设置
本文在公开数据集Criteo和自制微地图(WeMaps)数据集上进行了实验,验证了所提出模型的有效性。
Criteo数据集
Criteo数据集是一个广告点击预测数据集,包含了大量的广告展示和点击记录。该数据集包含13个数值特征和26个类别特征,共4500万条记录。
WeMaps数据集
WeMaps数据集是本文自制的微地图推荐数据集,包含了用户对微地图的浏览、收藏、分享等行为记录。该数据集包含用户特征、地图特征和用户历史行为序列,共10万条记录。
实验中,将数据集按照8:1:1的比例划分为训练集、验证集和测试集。模型的超参数通过在验证集上的性能来确定。实验采用Adam优化器进行模型训练,学习率设置为0.001,批量大小设置为256,训练轮数设置为10轮。
为了评估模型的性能,本文采用了以下两个评价指标:
对数损失(Log Loss)
对数损失是一种常用的分类问题评价指标,用于衡量模型预测概率与真实标签之间的差距。对数损失值越小,表示模型的预测越准确。
AUC
AUC(Area Under the ROC Curve)是受试者操作特征曲线下的面积,用于衡量模型的分类能力。AUC值越大,表示模型的分类能力越强。
4.2 对比方法
为了验证本文提出的模型的有效性,我们将其与以下几种经典的推荐算法进行了对比:
二阶特征交叉模型
- FM(Factorization Machine)
- FFM(Field-aware Factorization Machine)
高阶特征交叉模型
- DeepFM
- xDeepFM
- DCN(Deep & Cross Network)
基于用户历史行为序列的模型
- DIN(Deep Interest Network)
- DIEN(Deep Interest Evolution Network)
本文提出的模型
- FICUS(Feature Interaction and Cross-attention for User Sequence)
4.3 实验结果与分析
表1 不同模型在Criteo和WeMaps数据集上的性能对比
| 模型 | Criteo | WeMaps | ||
|---|---|---|---|---|
| Log Loss | AUC | Log Loss | AUC | |
| FM | 0.454 2 | 0.798 7 | 0.442 5 | 0.785 1 |
| FFM | 0.453 8 | 0.799 2 | 0.441 9 | 0.785 6 |
| DeepFM | 0.452 3 | 0.800 5 | 0.389 7 | 0.786 8 |
| xDeepFM | 0.451 7 | 0.801 2 | 0.388 9 | 0.787 2 |
| DCN | 0.451 5 | 0.801 4 | 0.389 2 | 0.787 0 |
| DIN | 0.450 8 | 0.802 1 | 0.385 3 | 0.787 5 |
| DIEN | 0.449 6 | 0.803 4 | 0.383 1 | 0.787 9 |
| FICUS(本文) | 0.446 1 | 0.805 2 | 0.379 7 | 0.788 3 |
从表1可以看出,本文提出的FICUS模型在Criteo和WeMaps数据集上都取得了最佳的性能。具体来说:
与二阶特征交叉模型相比
在Criteo数据集上:
- Log Loss降低了1.7%
- AUC提高了0.8%
在WeMaps数据集上:
- Log Loss降低了14.2%
- AUC提高了0.4%
与高阶特征交叉模型相比
在Criteo数据集上:
- Log Loss平均降低了1.3%
- AUC平均提高了0.6%
在WeMaps数据集上:
- Log Loss平均降低了2.6%
- AUC平均提高了0.2%
这些结果表明,本文提出的FICUS模型通过融合特征交叉和用户历史行为序列,有效地提高了推荐的准确性。模型的低损失值和高AUC值说明模型进行预测时具有较高的准确性和较好的分类能力。
4.4 消融实验
为了验证本文提出的各个模块的有效性,我们进行了消融实验。具体来说,我们分别移除了多头自注意力机制、跳跃连接和交叉注意力机制,观察模型性能的变化。
表2 消融实验结果
| 模型变体 | Criteo | WeMaps | ||
|---|---|---|---|---|
| Log Loss | AUC | Log Loss | AUC | |
| FICUS(完整模型) | 0.446 1 | 0.805 2 | 0.379 7 | 0.788 3 |
| FICUS w/o 多头自注意力 | 0.448 3 | 0.803 8 | 0.382 5 | 0.787 6 |
| FICUS w/o 跳跃连接 | 0.447 9 | 0.804 1 | 0.381 8 | 0.787 9 |
| FICUS w/o 交叉注意力 | 0.449 2 | 0.803 5 | 0.383 1 | 0.787 4 |
从表2可以看出,移除任何一个模块都会导致模型性能的下降,这证明了本文提出的各个模块的有效性。具体来说:
- 移除多头自注意力机制后,模型无法在多个子空间下进行特征交叉,导致特征组合信息不够丰富,性能下降。
- 移除跳跃连接后,模型无法有效结合低阶特征交叉和高阶特征交叉,导致模型退化,性能下降。
- 移除交叉注意力机制后,模型无法有效捕捉与候选地图相关的兴趣点,导致用户动态兴趣的建模不够准确,性能下降。
4.5 可解释性分析
本文提出的FICUS模型不仅能提供准确的推荐结果,还具有良好的可解释性。通过分析多头自注意力机制和交叉注意力机制的注意力权重,我们可以解释模型为什么会给用户推荐某个地图。
不同的用户-地图特征组合具有不同的注意力权重,这些权重反映了各个特征组合对推荐结果的重要性。例如,用户的年龄和地图的类型组合可能具有较高的权重,表示这个组合对推荐结果有较大的影响。
用户历史行为序列中与候选地图相关的兴趣点具有较高的注意力权重,这些权重反映了用户对不同类型地图的兴趣程度。例如,如果用户最近浏览了多个旅游类地图,那么在推荐旅游类地图时,这些历史行为会获得较高的注意力权重。
5 结论
本文针对现有微地图推荐算法未充分挖掘用户与微地图特征,推荐结果准确率较低的问题,提出了融合特征交叉与用户历史行为序列的微地图推荐算法。该算法在用户与地图特征交叉过程中引入了跳跃连接和多头自注意力机制,在用户历史行为序列中引入了交叉注意力机制,通过融合特征交叉和用户行为序列模块的输出,获得了综合多个维度的推荐结果。
实验结果表明,本文提出的算法在公开数据集Criteo和自制微地图数据集上都取得了最佳的性能。相较于二阶特征交叉模型,损失值分别降低了1.7%、14.2%,AUC值提高了0.8%、0.4%。相较于高阶特征交叉模型,损失值平均降低了1.3%、2.6%,AUC值平均提高了0.6%,0.2%。这些结果证明了本文算法的有效性。
此外,通过分析多头自注意力机制和交叉注意力机制的注意力权重,本文算法还具有良好的可解释性,可以向用户解释为什么会给他们推荐某个地图,提高推荐系统的透明度和用户信任度。
未来的工作将集中在以下几个方面:① 探索更复杂的特征交叉方式,进一步提高推荐准确率;② 引入更多的上下文信息,如时间、位置等,使推荐结果更加个性化;③ 研究如何在保证推荐准确率的同时,提高模型的计算效率,使其能够应用于大规模的微地图推荐系统中。
引用格式
杨军,王琛锡,闫浩文.融合特征交叉与用户历史行为序列的微地图推荐[J].地球信息科学学报,2024,26(1):158-169. [ Yang J, Wang C X, Yan H W. Integration of feature interaction and user historical behavior sequence for WeMaps recommendation[J]. Journal of Geo-information Science, 2024,26(1):158-169. ] DOI:10.12082/dqxxkx.2024.20230119
* 以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。