1 引言
网络游记是旅游者在互联网上发布的自述性旅游过程记录,描述了旅游的前后过程和感受体验。目前,网络游记文本已成为旅游地理分析中的一种重要数据源,基于此开展了目的地形象、旅游体验、旅游行为、旅游流网络结构等方面的研究,给区域旅游规划设计、服务质量提升提供了重要的支撑。
网络游记文本中蕴含了丰富的行程信息,提取游客的行程链,分析节点特征、行程结构、活动偏好,可为游客的目的地推荐、行程制定、线路设计提供决策参考。然而,传统的游记数据处理大多是通过人工识别游记文本中的信息,一旦游记数量多时,其处理工作量非常大。部分研究采用基于本体库信息抽取、关键词提取或Rost CM6软件进行分词处理,存在着数据误差大的问题,影响分析结论的适用性。
旅游行程链是按照时间顺序线性排列的旅游者停留节点有序集合,而网络游记文本正是旅游行程链的自然语言描述和表达。网络游记文本描述较为随意,一方面,游记文本中包含了很多旅游点名称,但只有一部分是旅游者真正去的旅游点,可称之为行程节点;另一方面,部分游记文本中,同一个旅游点在多个段落中描述,作者没有严格按照游览次序去描述旅游点,导致按照次序识别的行程节点,其顺序并非真正的行程顺序。
2 研究方法
2.1 总体思路
从网络游记这样复杂的长文本中提取出旅游行程链,就是从众多的旅游点名称中,准确的识别出行程节点,再按照游览次序将行程节点串联起来。尽管不同网络游记作者的写作方式和风格不同,但是游记文本中行程节点及其次序关系的表达,有着较为明显的句法结构特征。
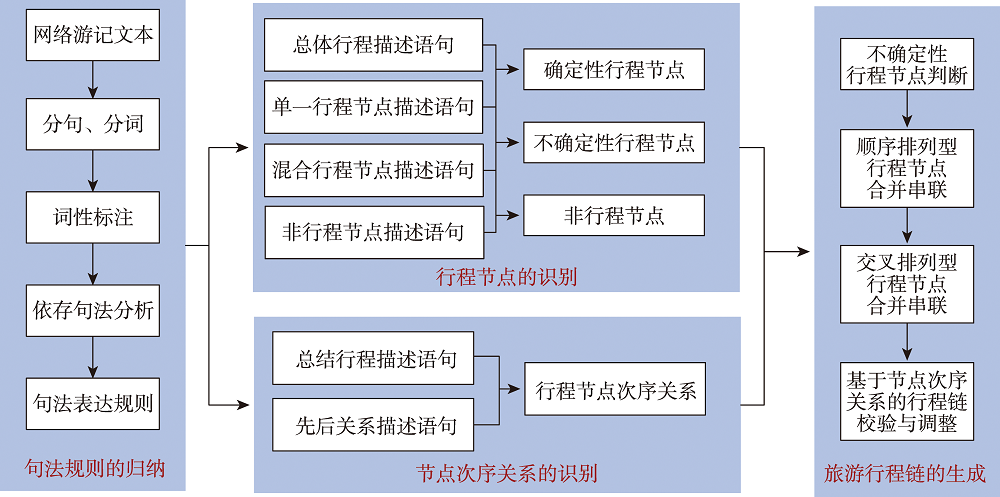
图1 旅游行程链提取的总体技术框架
2.2 行程节点的识别
网络游记文本会提及较多地理实体,这些实体不仅仅是旅游点,还包括住宿点、餐饮点、交通枢纽等地,而本文识别的行程节点对象仅限于旅游点。但是,在网络游记文本中,只有一部分旅游点是旅游者真正到达的,可称之为行程节点。
旅游点在网络游记文本中的表达形式可分为4大类,包含总体行程描述、单一行程节点描述、非行程节点描述和混合行程节点描述:
| 序号 | 类型 | 示例语句 | 句法结构特征 |
|---|---|---|---|
| 1 | 总体行程 | (1)第一天,中山陵,明孝陵,美龄馆,音乐台 (2)中山陵-明孝陵-灵谷寺-美龄宫 |
多个旅游点在一句话中连续排列 |
| 2 | 单一行程节点 | (1)办理完取车后续后,直接去了夫子庙景区。 (2)吃完早餐,出发去了总统府 |
"去、前往、逛"等助动词和旅游点构成动宾关系 |
| 3 | 非行程节点 | (1)我是下午2点左右到明孝陵,后边没有时间去音乐台和中山陵了 (2)今天计划是去南京博物院,却发现门票已经预约完了 |
"没有、计划、本来、打算"等排除词衔接旅游点 |
| 4 | 混合行程节点 | (1)玄武湖公园西靠明城墙,是中国最大的皇家园林湖泊 (2)音乐台在中山陵的东南角,非常近,从中山陵出来往前走一会便是 |
旅游点作为空间参照,方位词的定语 |
通过对上述4类表达形式的词性标注和依存句法分析,本文归纳的旅游行程节点句法规则如下:
| 编号 | 规则名称 | 句法化 | 句法规则 |
|---|---|---|---|
| 1 | 总体行程描述 | <旅游点>+<连接字符>+<旅游点> | tp/cs/tp/cs |
| 2 | 行程触发词加旅游点 | <行程触发词>+<助动词>+<旅游点> | iw/u/tp |
| 3 | 旅游点单独成句 | <旅游点> | tp |
| 4 | 旅游点是句子的主语 | <旅游点>+<动词>+<名词> | tp/v/n |
| 5 | 旅游点是主语的定语 | <旅游点>+<助动词>+<名词> | tp/u/n |
| 6 | 行程否定词加旅游点 | <排除词>+<动词>+<旅游点> | nw/v/tp |
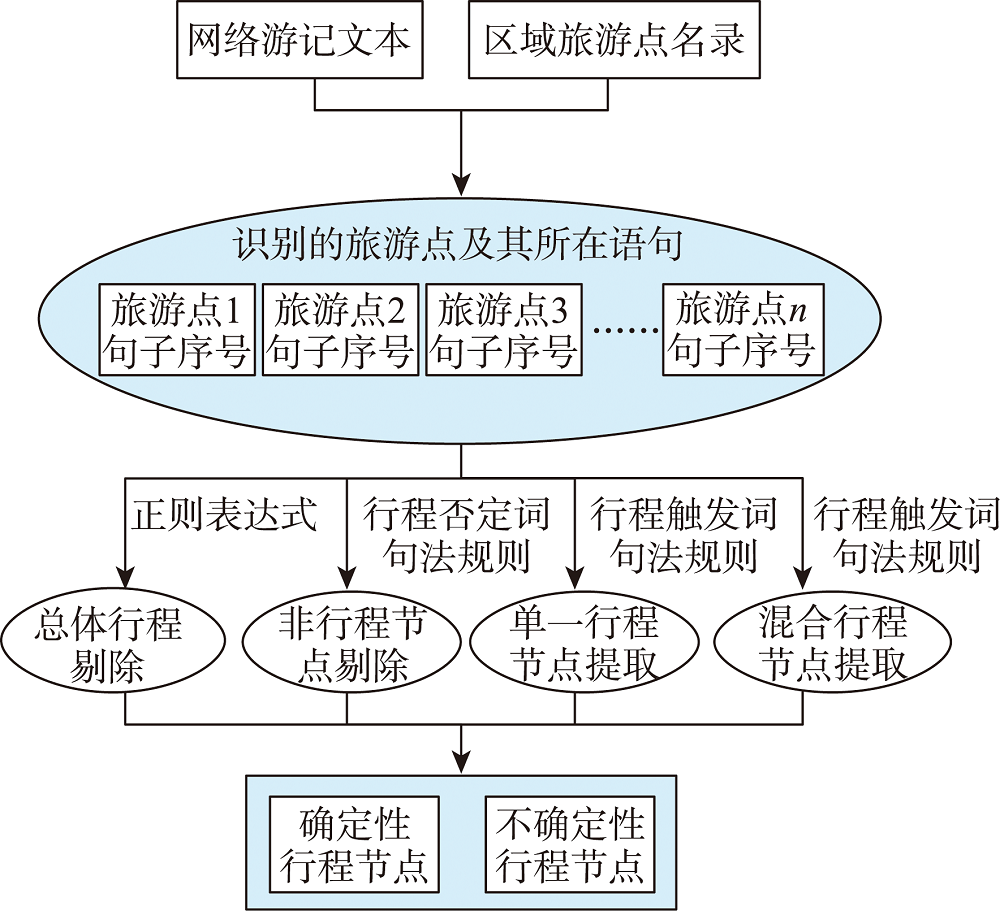
图2 旅游行程节点的识别流程
2.3 节点次序关系的识别
旅游行程链是旅游点按照时间顺序线性排列的有序集合。通常来说,游记作者在文本撰写过程中,会按照游览次序依次介绍景点,但是,不同作者的文本描述风格不同,部分游记文本在前言部分介绍了前往的旅游点,在中间段落描述了该旅游点的详细内容,在结尾部分还提及了该旅游点,没有严格按照时间顺序描述旅游行程,导致按照次序识别的行程节点,其顺序并非真正的行程顺序。
2.4 旅游行程链的生成
按照正确的游览次序将提取的旅游行程节点进行合并、串联,就构成了旅游行程链。但是,在识别旅游行程节点、节点次序关系之后,行程列表中还有一部分节点名称被标识为不确定性行程节点,同时,顺序识别游记文本中的行程节点,普遍存在重复、交叉的现象。
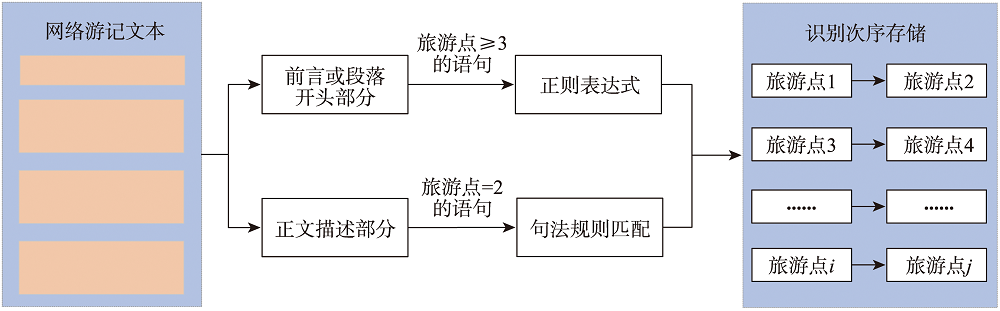
图3 行程节点次序关系的识别
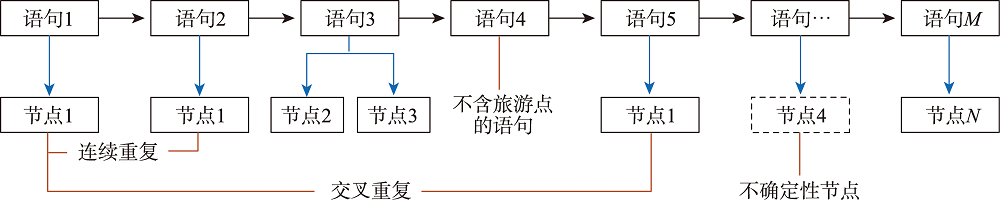
图4 行程节点的重复和交叉现象
针对不确定性行程节点的处理,需要从游记全文叙事视角来衡量这些节点的取舍情况:
- 判断不确定性行程节点是否在已识别的节点次序关系表中
- 如果该节点不在节点次序关系表中,再判断游记文本中该节点出现的次数是否大于一次
针对旅游行程节点的串联,主要是根据提取到的节点上下文特征,结合识别的节点次序关系,连接行程节点。识别到的行程节点排列模式可归纳为2类:
- 顺序排列型:高质量的网络游记文本一般是按照游览次序来顺序描述旅游点
- 交叉排列型:由于互联网平台游记文本写作较为随意,导致识别的行程节点列表中,节点交叉重复现象较多
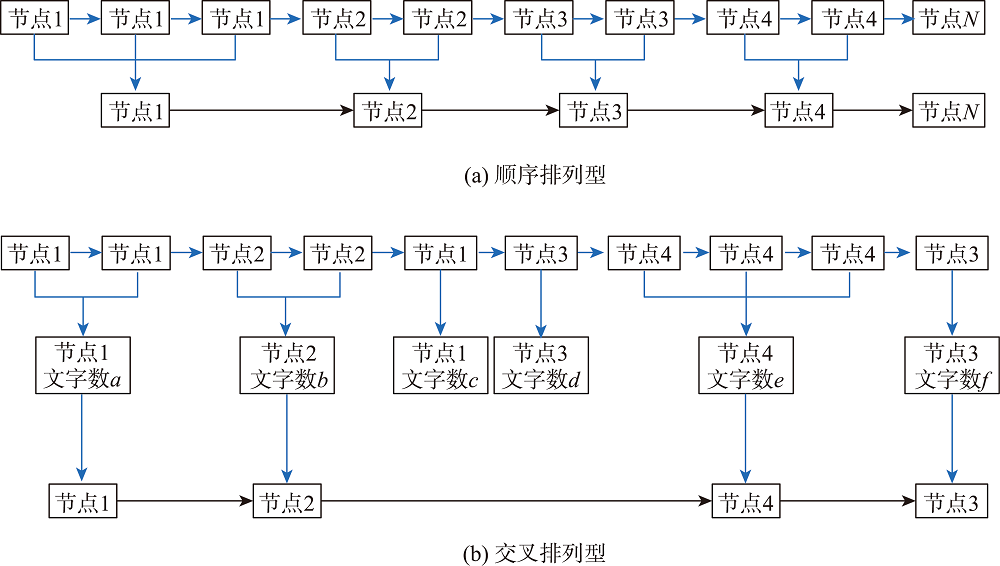
图5 行程节点的串联处理过程
3 实验及结果分析
3.1 实验结果
本研究采集了蚂蜂窝平台17226篇南京市网络游记文本数据和566个旅游点名录数据,剔除了文本字数小于500的低质量游记,最终得到13608篇有效网络游记文本。通过本文方法,依次提取了每篇网络游记文本的旅游行程链。
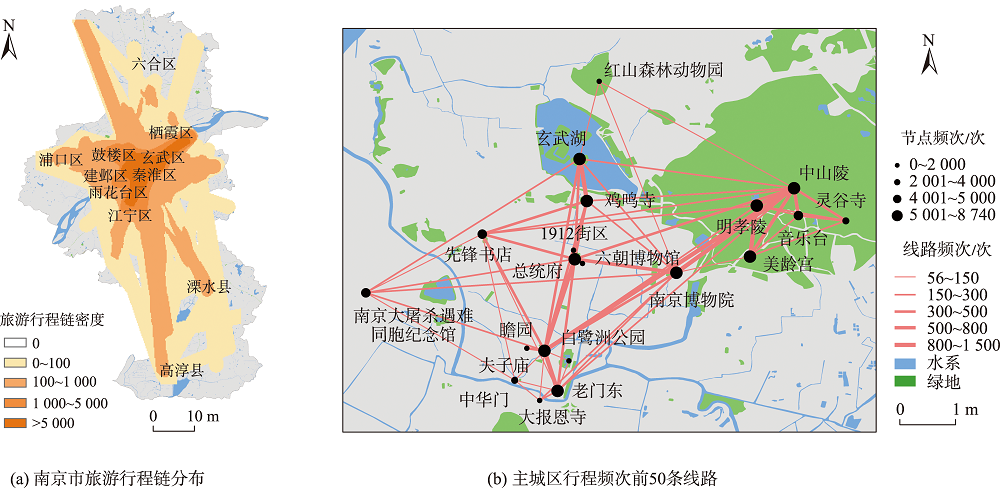
图6 案例区域提取的旅游行程链分布
整体来看,网络游记文本提取的行程线路主要聚集在主城区的核心景区,其与栖霞山片区、牛首山片区构成了"一主两副"的分布格局。行程频次前50条的线路如图6(b)所示,玄武湖、明孝陵、中山陵、夫子庙等地成为了南京旅游行程链网络中的核心节点。
为验证本文方法的有效性,本研究随机选择了300篇网络游记,人工提取的这些文本中的旅游行程链,采用最长公共子序列算法,计算了本文方法提取和人工识别旅游行程链的相似度,最终的相似度为86.14%。
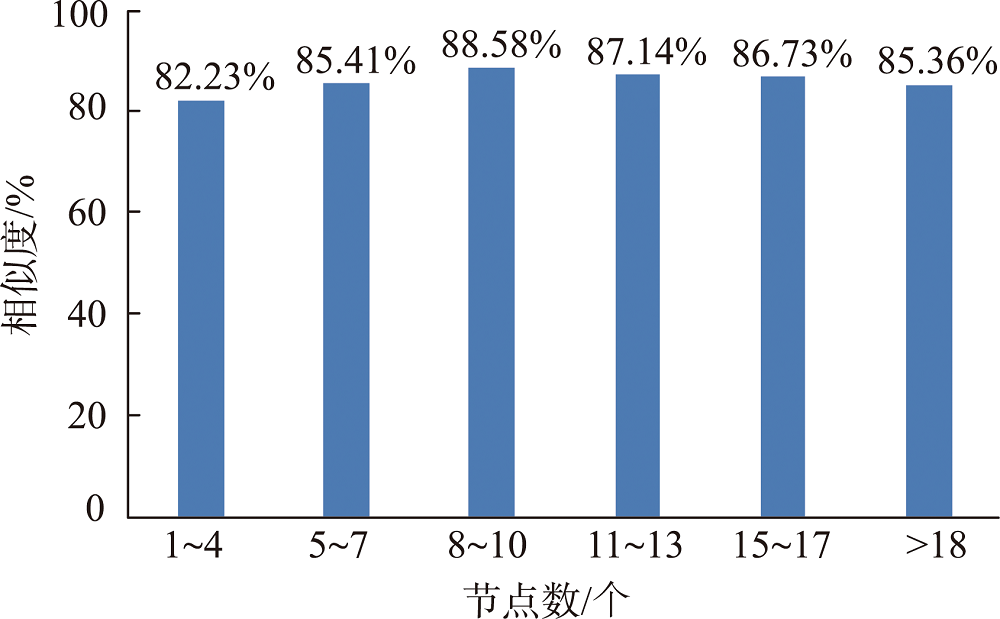
图7 不同节点数量游记文本中行程链提取的相似度分布
3.2 结果讨论
整体来看,本文方法中影响行程链提取准确率的主要因素包含以下:
- 网络游记文本的描述方式
- 一些行程节点所在语句的句法结构复杂
- 旅游点名录数据不够完整
为了进一步验证本文方法的适用性,本研究开展了对比实验。在标注18129个行程节点与16104个节点关系的基础上,本文采用了实体关系抽取领域的BERT-BiLSTM-CasRel深度学习模型,与人工提取结果的相似度为83.1%,略低于本文方法的86.14%。
4 结论
针对以往依赖于人工提取网络游记文本行程信息工作量较大的问题,本文在深入分析网络游记文本段落结构和表达特点的基础上,归纳行程节点和节点次序关系的句法表达规则,提出了基于句法规则的旅游行程链提取方法,主要包含行程节点的识别、节点次序关系的识别和旅游行程链的生成。
本文采集了蚂蜂窝平台17226篇南京市网络游记文本数据,采用最长公共子序列算法,开展了本文方法的试验验证。通过对比分析,本文方法提取的旅游行程链和人工识别的真实行程链相似度达到86.14%,高于实体关系抽取领域的BERT-BiLSTM-CasRel深度学习模型的83.1%。
相比实体关系抽取深度学习模型依赖于大量的信息标注,本文方法具有较强的适用性,仅需要构建区域旅游点名录,就能完成游记文本的行程重构。但是,本文方法基于句法规则,有一定的局限性,灵活度较差,需要构建较为完整的旅游点名录数据集,准确率提升有一定的上限。下一步,将充分利用大语言模型良好语义理解能力的特点,基于大语言模型开展行程提取研究,进一步提高准确率和数据处理效率。