1. 引言
互联网时代在线社交平台空前发展,并产生了大量社交网络数据。在社交平台上,用户可以随时随地分享自己的生活见闻、参与热点话题讨论、在兴趣点定位打卡,同时还能关注社交网络上的其他用户并与其互动交流。用户在社交平台上发布的内容包含显式或隐式的用户位置信息,而作为连接虚拟世界和现实世界的桥梁,社交网络中用户的位置可以支撑基于位置的应用、服务和分析,如自然灾害监测、流感趋势预测、定向广告推广等,同时还有助于更好地理解现实世界中发生的事件,如预测网络舆情并预防危险行为,具有极大的应用价值。
位置数据可以来源于用户发文的地理标签,或者用户个人配置文件中自行设置的住址,然而大多数用户不会透露他们的位置,导致社交网络中的位置数据十分稀疏。研究表明带有地理标签的网络发文仅占1%,同时由于隐私保护问题,用户一般不会在个人配置中给出自己的位置,即使声明了自身位置,也存在位置虚假、地理精确度低等问题。
用户地理位置推测是一个被动的人群感知问题,融合多源信息、挖掘用户行为特征以及分析用户社交属性,都将帮助提高推测结果的准确度、降低距离误差。
2. 研究方法
2.1 问题描述
本文主要推测用户的住所位置(Home Location),即用户长期所在的位置。本文将用户地理位置推测问题视为一个分类问题,利用从网络发文显式或隐式的信息中提取的社交关系以及网络发文本身来定位社交网络用户。具体来说,对有地理标签的用户进行聚类并得到位置标签,用位置标签表示每位用户的类别,位置标签代表的区域中心点即为用户的推测位置。
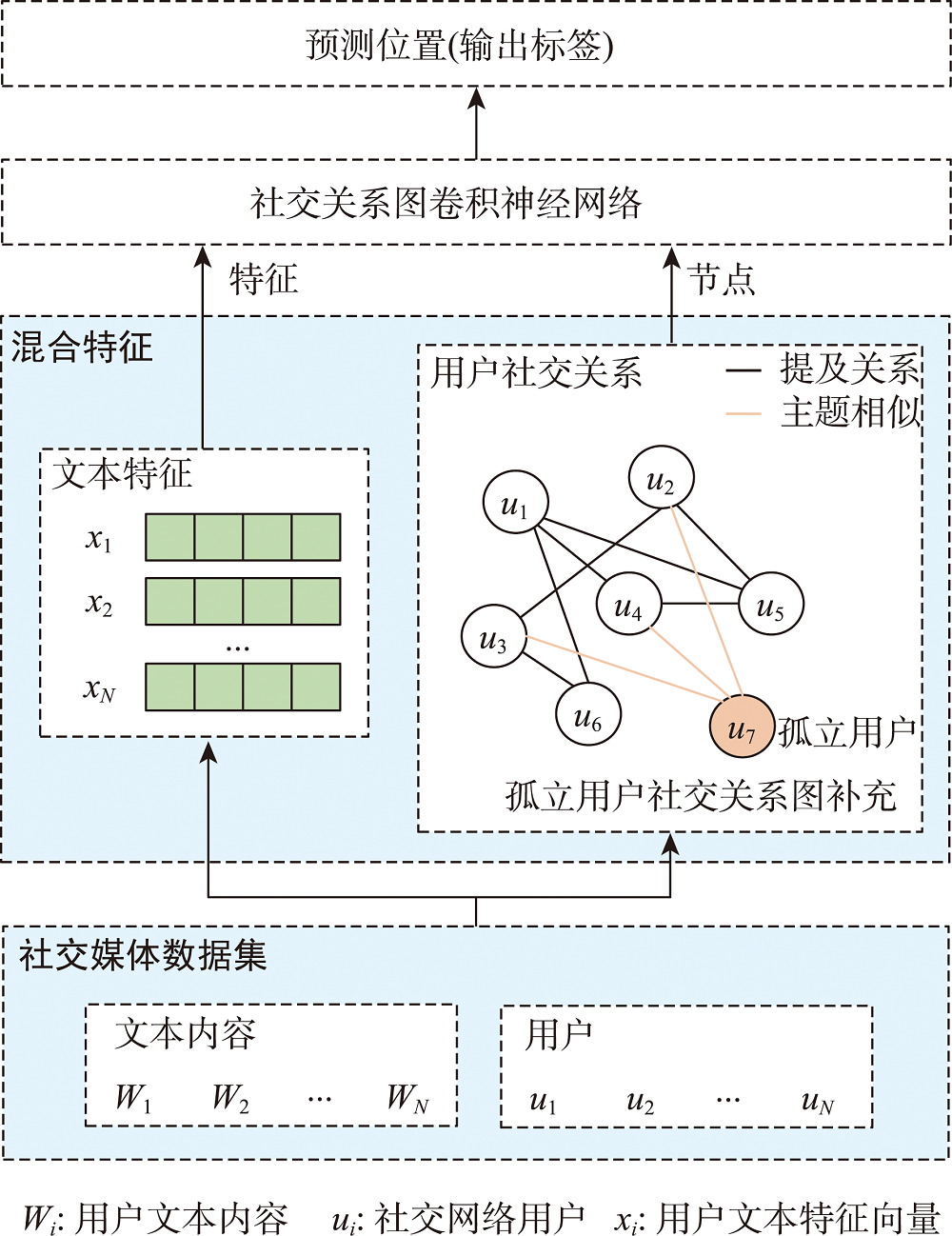
图1 基于文本主题和社交关系的用户位置推测结构
2.2 混合特征
混合特征包括网络发文的语义特征和用户社交关系特征。
TF-IDF特征:能代表一位用户所处地理区域的词必须是重要且独特的,可以将每位用户的所有网络发文看作一个文档,利用TF-IDF计算用户的文本特征向量,TF指词汇在该文档出现的频率,IDF则用于惩罚那些在很多文档中都出现的常见词。
用户社交关系特征:利用用户在社交网络上的互动(@-user)建立提及图(无向图),此时图中存在"名人节点",这些用户不仅会增大图的规模,还会干扰地理位置推测,根据研究经验,需要将其删除。
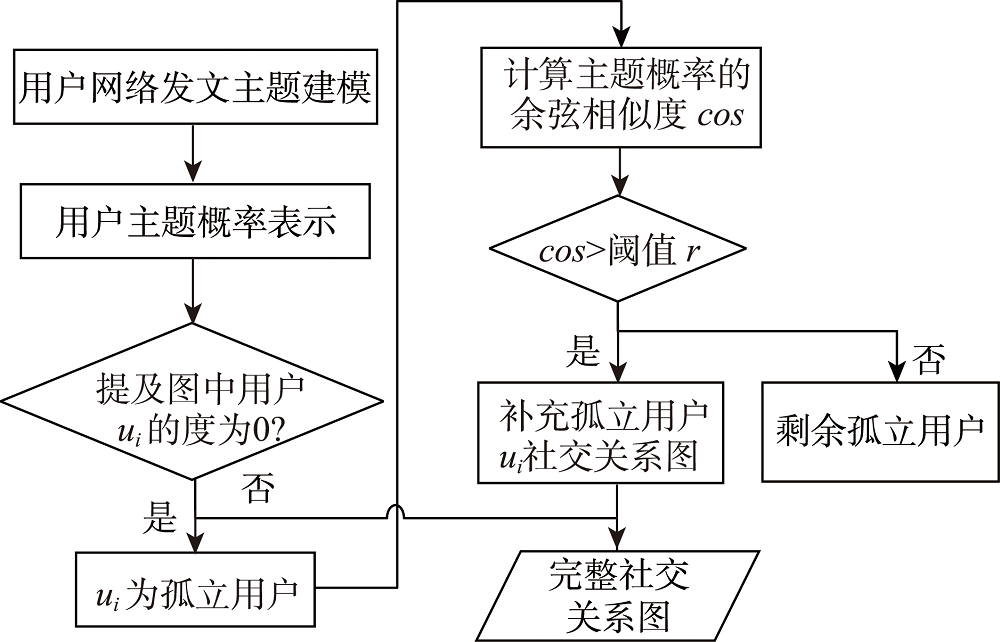
图2 基于文本主题相似度的社交关系图补充方法流程
2.3 孤立用户社交关系图补充
由上述提及信息建立的社交关系图有一个缺点,即该图无法覆盖所有用户,当用户在社交网络上未与其他用户互动时,被定义为孤立用户,这些用户不能融合来自邻居的信息(没有邻居),若其本身没有地理标签,则无法推测该用户的位置。
针对这个问题,提出一种基于文本主题相似度的孤立用户社交关系图补充方法,流程如图2所示。
2.4 SRGCN:社交关系图卷积神经网络
本文模型SRGCN采用三层GCN聚合用户节点的直接邻居、二阶邻居和三阶邻居信息,同时利用高速(Highway)网络结构过滤邻域中的噪声信息,从聚合信息中学习位置指示特征,使用模型最后一层的输出来推测社交网络用户的地理位置,模型结构如图3所示。
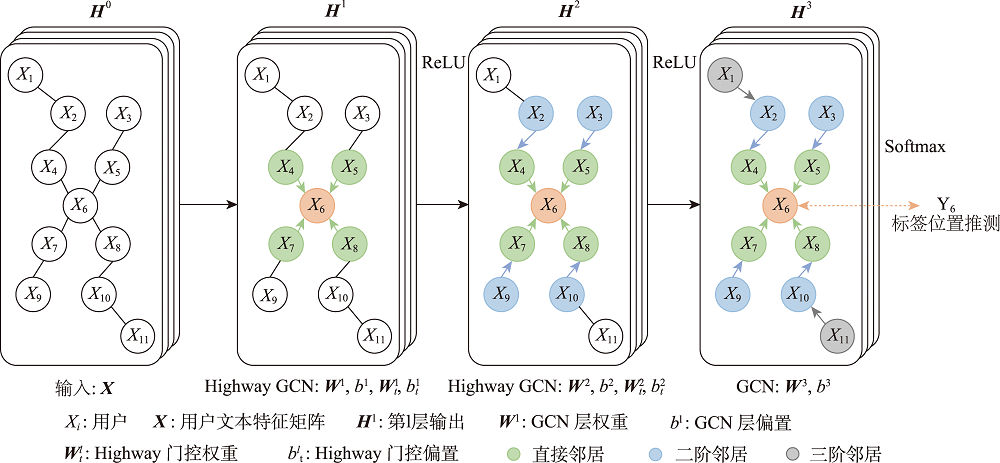
图3 具有高速网络的GCN模型结构
3. 实验及分析
3.1 实验设置
数据来源:实验选取了一个真实的Twitter数据集GeoText,该数据集由Eisenstein等采集,通过剔除发文不活跃用户和关注者较多的名人等过滤操作之后,最终数据集包括美国地区的9575位用户、38万条推文。
图4 GeoText数据集中用户的地理分布情况
表1 数据集介绍
| 数据集 | 推文数/条 | 训练集用户数/个 | 验证集用户数/个 | 测试集用户数/个 | 边数量/条 | 孤立用户数/个 |
|---|---|---|---|---|---|---|
| GeoText | 377504 | 5685 | 1895 | 1895 | 77155 | 424 |
图5 用户地理区域划分
3.2 结果与分析
3.2.1 孤立用户关系图补充
表2给出了在GeoText数据集上,孤立用户补充关系图对模型的贡献,具体来说,探究了主题相似度阈值对推测性能和图规模的影响。
表2 孤立用户补充关系图对推测性能和图规模的影响
| 主题相似度阈值 | 平均距离误差/km | 位置推测准确度/% | 边/条 |
|---|---|---|---|
| 0.60 | 533 | 60.11 | 94745 |
| 0.65 | 545 | 59.53 | 92157 |
| 0.70 | 540 | 60.21 | 90374 |
| 0.75 | 542 | 59.79 | 88522 |
| 0.80 | 545 | 59.79 | 85899 |
| 0.85 | 557 | 59.89 | 84782 |
| 0.90 | 530 | 60.58 | 81256 |
| 0.95 | 525 | 60.05 | 79084 |
3.2.2 性能比较
表3给出了SRGCN模型与6个基线模型在地理位置推测问题上的性能表现,可以看出相比于现有模型,SRGCN模型在性能上有一定提升。
表3 地理位置推测算法的性能比较
| 模型 | 平均距离误差/km | 距离误差中位数/km | 位置推测准确度/% |
|---|---|---|---|
| MLP + k-d tree | 844 | 389 | 38.00 |
| UNIFCENTROID | 897 | 432 | 35.90 |
| MADCEL-W-LR | 581 | 57 | 59.00 |
| MADCEL-W-MLP | 578 | 61 | 59.00 |
| MENET | 570 | 58 | 59.10 |
| GCN | 546 | 45 | 60.00 |
| SRGCN | 530 | 46 | 60.58 |
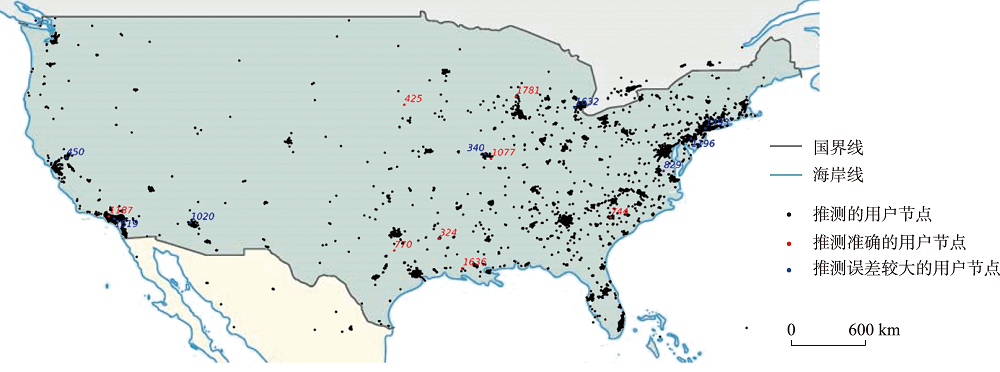
图6 位置推测效果存在差异的用户地理分布情况
表4 位置推测效果存在差异的用户基本信息
| 用户标识 | 编号 | 真实位置(经度,纬度)/(°,°) | 发文数/条 | 社交关系数/条 | 距离误差/km |
|---|---|---|---|---|---|
| USER_542aa1fb | 1493 | (-74.010,40.707) | 63 | 22 | 0.00 |
| USER_7b70c03a | 1632 | (-83.690,42.255) | 38 | 33 | 0.49 |
| USER_af6729de | 340 | (-90.335,38.779) | 22 | 5 | 2.07 |
| USER_49d4be2e | 1619 | (-117.890,33.917) | 72 | 35 | 4.46 |
| USER_f4f9f786 | 1196 | (-75.072,39.940) | 31 | 14 | 7.85 |
| USER_1e0d7389 | 450 | (-121.457,38.487) | 23 | 21 | 13.39 |
| USER_5a99377b | 829 | (-77.107,37.507) | 58 | 41 | 40.17 |
| USER_ccabb575 | 1020 | (-112.239,33.624) | 21 | 35 | 80.84 |
3.2.3 可视化结果
SRGCN希望有相同标签的样本聚集在一起,为了验证模型的学习能力,从GeoText中随机选取5个区域测试模型的性能,并利用t-SNE对这些区域中用户的嵌入表示降至二维并进行可视化。
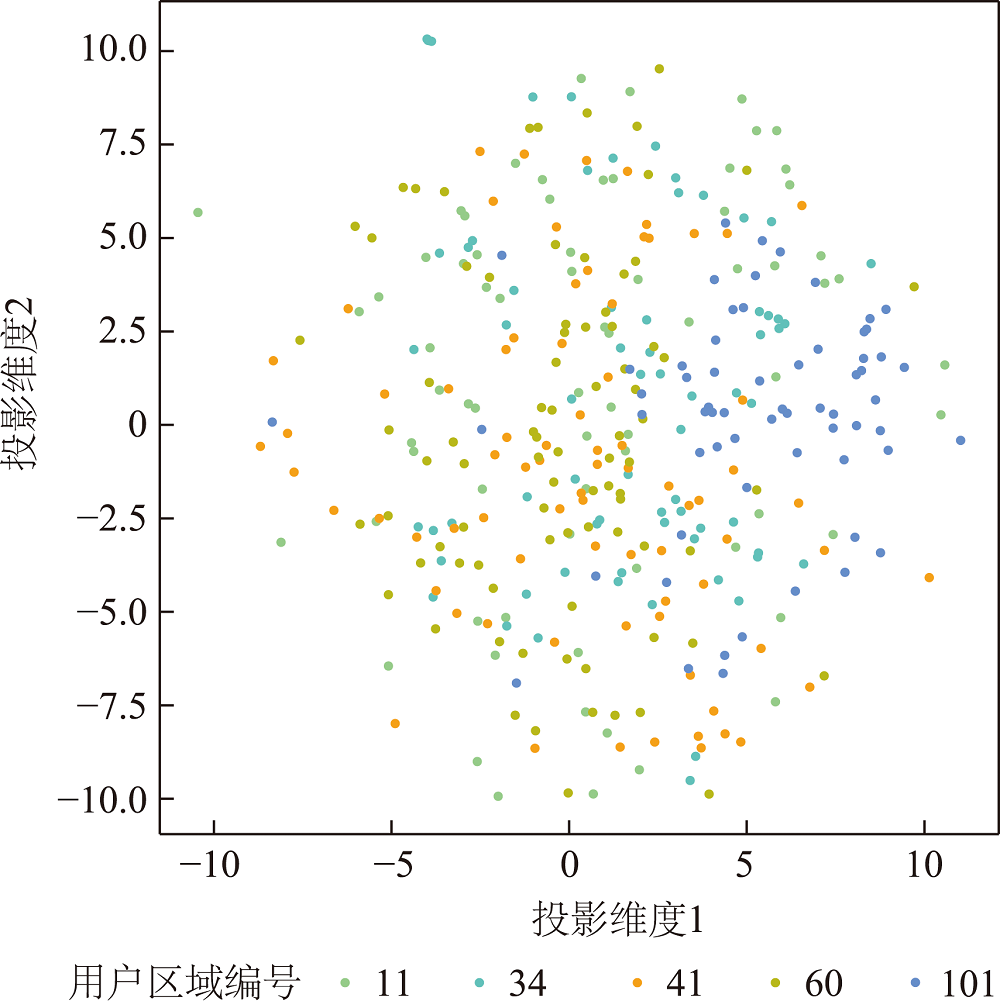
图7 用户嵌入表示二维可视化(原始)
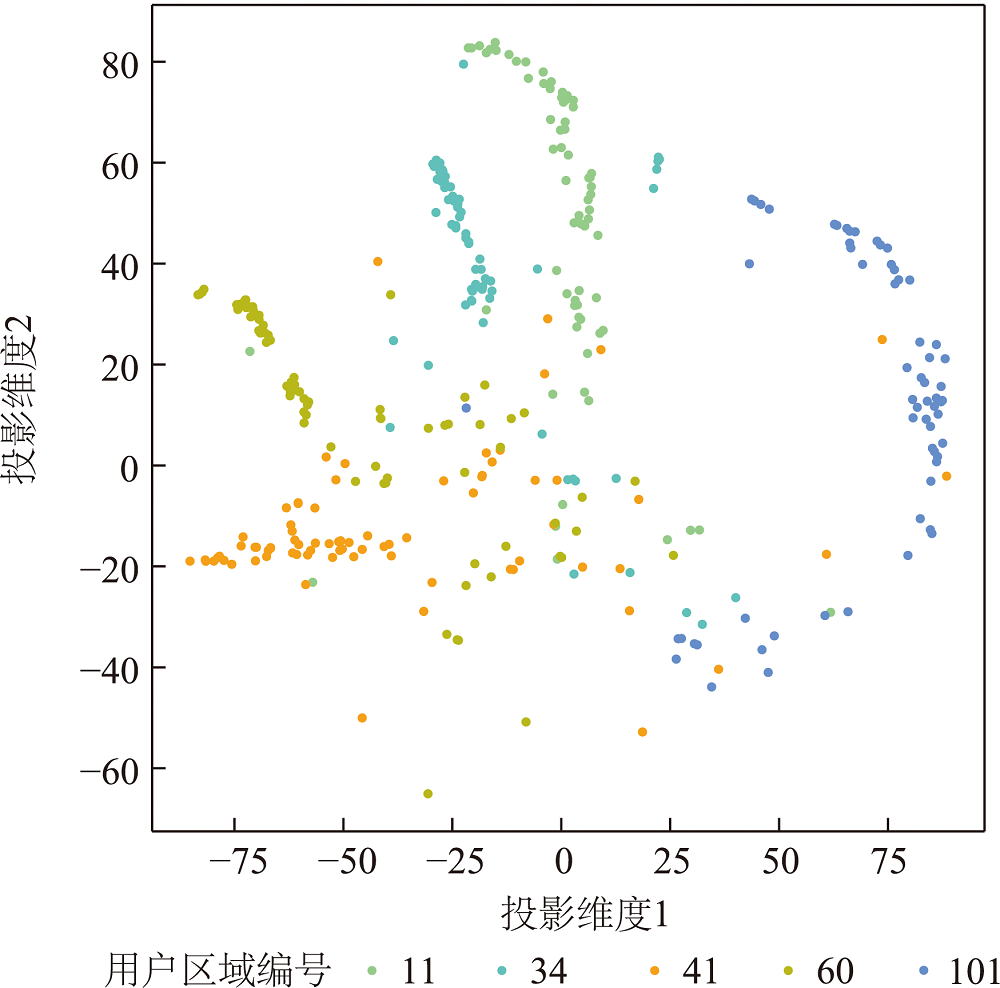
图8 用户嵌入表示二维可视化(训练后)
4. 结语
本文提出了一种基于图神经网络的多视角学习模型SRGCN,融合文本主题和社交网络推测社交网络用户的住所位置。采用TF-IDF提取文本特征,为了解决独立用户位置无法推测的问题,在提及图的基础上提出了一种基于文本主题相似度的孤立用户社交关系图补充方法。
利用GCN对文本特征和网络结构进行联合建模,在Twitter基准数据集上对比了SRGCN、MENET和GCN等方法。此外,还测试了孤立用户关系图对模型的贡献,对用户特征向量进行了可视化。得出的主要结论如下:
- 根据主题相似度为孤立用户建立联系,能够增加可定位用户的比例,提升社交关系图丰富度,进而提高位置推测准确度。
- 结合文本内容和社交网络的SRGCN方法性能优于现有方法,可以深入挖掘文本和网络特征并有效融合。在GeoText数据集上,Acc@161比MENET、GCN高出2.5%、0.97%,平均误差距离分别降低40km、16km。
以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。