研究摘要
在正常运行的城市路网中,存在一些对路网运行效率有较大影响的路段,这些路段一旦发生拥堵,可能会造成局部路网瘫痪,因此可将其视为关键路段。若能识别出这些关键路段并进行有效管理,便能够缓解整个路网的交通压力,这对于提升城市交通系统的效率和可靠性具有重要意义。
目前对于关键路段的识别已取得了丰富的成果,但在大规模路网(如城市级别)中,现有方法往往无法识别出交通流量较小的局部区域内的相对关键路段。为弥补上述不足,本研究提出了一种基于路段动静态嵌入的两阶段特征学习方法来识别大规模路网中的关键路段。
研究亮点
- 提出了一种基于路段动静态嵌入的两阶段特征学习方法
- 能够识别出大规模路网中的关键路段,以及交通流量较小的局部区域内的相对关键路段
- 基于手机定位数据构建交通语料库,利用自然语言处理技术提取路段特征
- 通过注意力池化和可微分聚类实现特征融合与优化
研究方法
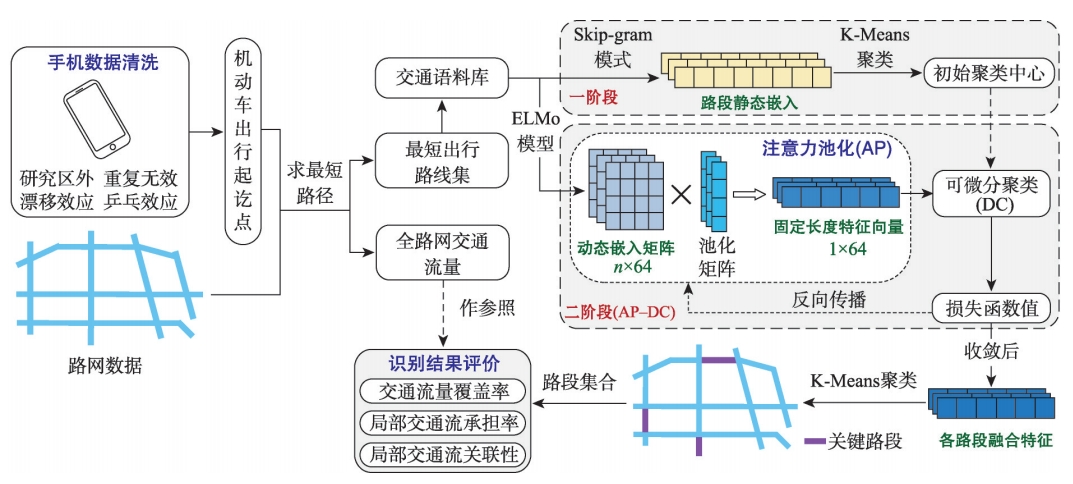
图1:基于路段动静态嵌入两阶段特征学习的关键路段识别方法流程
交通语料库构建
将路网中的路段类比为单词,出行路线类比为句子,通过数字到字母的映射(即 0~a, 1~b, …, 9~j),从而完成交通语料库的构建。
示例: 路段序列"路段123,路段456,路段789"映射为句子"bcd efg hij"
路段静态嵌入
基于 Word2Vec 的 Skip-gram 模式,学习路段在出行路线中的共现关系和顺序关系,生成路段的静态嵌入表示。
特点: 同一路段在不同上下文中出现次数不影响其嵌入表示,因此被视为静态嵌入。
路段动态嵌入
使用 ELMo (Embeddings from Language Models) 模型,根据路段在特定上下文中的使用动态调整其嵌入表示。
优势: 能够捕捉同一路段在不同出行路线(不同上下文环境)中的不同特征。
注意力池化
为路段动态嵌入矩阵中的每个嵌入分配注意力权重,并使用这些权重对矩阵进行加权求和,生成固定维度的特征向量。
作用: 能够根据重要性对不同动态嵌入进行加权整合,避免某种表示过度影响结果。
可微分聚类
将聚类算法与深度学习框架相结合,允许聚类过程在端到端的可微分神经网络中进行训练。
技术创新: 利用 softmax 函数实现软分配,计算每个路段特征向量对各簇的归属概率。
两阶段特征学习
第一阶段基于路段静态嵌入进行聚类,得到初始聚类中心;第二阶段通过注意力池化和可微分聚类,融合静态和动态嵌入,得到最终的路段融合特征。
创新点: 既考虑了路段间的真实连接关系,又反映了各路段在不同出行路线中的多种表示。
评价指标
| 指标名称 | 计算公式 | 含义 |
|---|---|---|
| k阶交通流覆盖率 (CRk) |
CRk = ∑i∈Nk(S)F(i) / ∑i∈VF(i) | 各关键路段及其所有k阶近邻路段的路段集合交通流量占整个路网交通流量的比例 |
| k阶局部交通流承担率 (LFRk) |
LFRk(i) = F(i) / (F(i) + ∑j∈Nk(i)F(j)) | 一个路段交通流量除以其本身加上k阶近邻路段的交通流量总和 |
| 第k阶局部交通流关联性 (LTFk) |
LTFk = ∑u∈Nk(v)(1 - 6×∑i=1n(R(Tiv) - R(Tiu))² / n(n² - 1)) / |Nk(v)| | 单个路段与其第k阶近邻路段交通流量变化的相关性 |
实验结果
研究区域与数据
本研究以福州市三环内路网作为研究区域,采用2023年3月20日的手机定位数据和福州三环内路网数据(2022年,来源于OSM网站)估算全路网交通流量并构建语料库。
手机定位数据融合了GPS、WIFI、蓝牙以及手机传感器等多种技术进行定位,定位误差在5~50 m之间。经数据清洗后,剩下约100万个用户,平均每个用户约有34条记录。
研究区路网数据共有20,433条路段和14,158个节点,通过NetworkX处理后用于计算出行路线。
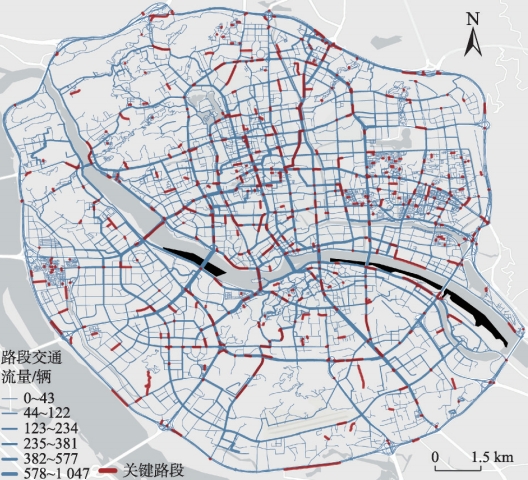
图2:福州市三环内区域11—16时路网交通流量估算
关键路段识别结果
图3:福州市三环内区域路网前3%关键路段识别结果
本研究识别了前3%的关键路段(约613条)。当聚类数为610时,其轮廓系数最高,为0.732。
从识别结果可以看出,关键路段在交通流量较大的区域内分布较多,而交通流量较小的局部区域中也存在一定数量的相对关键路段。
这说明本方法不仅能识别出全路网中交通流量较大的关键路段,还能识别出交通流量较小的局部区域内的相对关键路段。
对比分析
为验证本方法的有效性,将其与Apriori、Node2Vec和Word2Vec方法进行对比,分别计算各方法识别结果的评价指标。
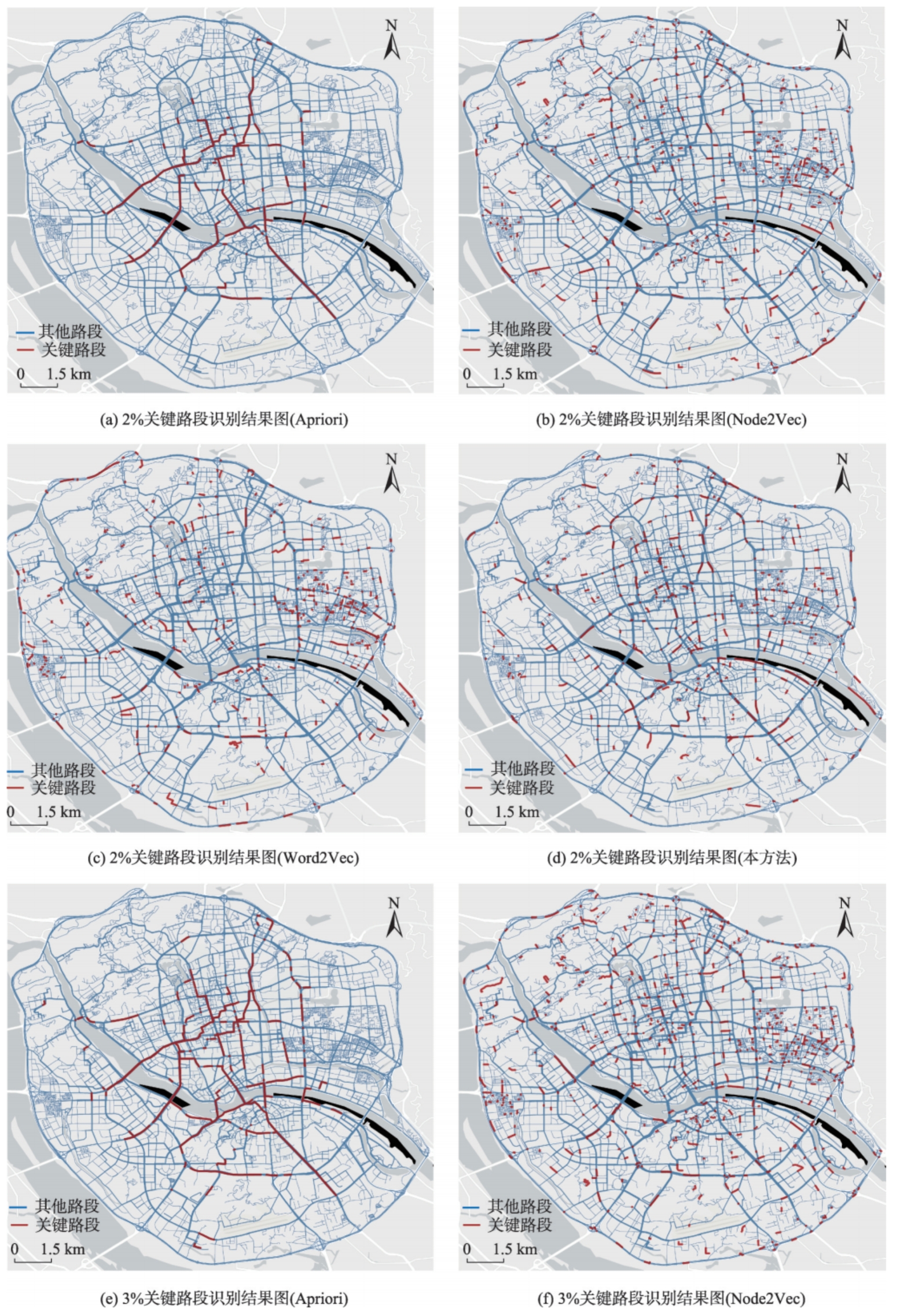
图4:福州市三环内区域路网不同方法关键路段识别结果对比
| 关键路段比例 | 方法 | 交通流覆盖率/% | 局部交通流承担率/% | 局部交通流关联性 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1阶 | 2阶 | 3阶 | 1阶 | 2阶 | 3阶 | 第1阶 | 第2阶 | 第3阶 | ||
| 2% | Apriori | 27.94 | 39.13 | 49.19 | 20.32 | 8.71 | 4.44 | 0.528 | 0.356 | 0.288 |
| Node2Vec | 9.41 | 25.78 | 48.77 | 14.54 | 5.11 | 2.46 | 0.379 | 0.251 | 0.203 | |
| Word2Vec | 8.10 | 21.08 | 38.11 | 18.01 | 6.31 | 2.99 | 0.374 | 0.217 | 0.153 | |
| 本方法 | 19.76 | 38.83 | 59.32 | 20.04 | 8.76 | 4.73 | 0.523 | 0.388 | 0.339 | |
| 3% | Apriori | 38.70 | 50.81 | 59.99 | 20.08 | 8.07 | 4.34 | 0.527 | 0.344 | 0.277 |
| Node2Vec | 15.80 | 41.85 | 71.78 | 14.74 | 5.21 | 2.55 | 0.396 | 0.273 | 0.225 | |
| Word2Vec | 11.44 | 28.62 | 49.87 | 17.82 | 6.34 | 2.97 | 0.382 | 0.213 | 0.156 | |
| 本方法 | 29.05 | 53.76 | 73.44 | 19.89 | 8.24 | 4.56 | 0.519 | 0.375 | 0.319 | |
从对比结果可以看出:
- Apriori算法识别的关键路段大多为彼此相连且交通流量较高的路段,因此在某些指标上的表现更具优势。然而大部分路段相互连接,覆盖范围不够广泛,且基本无法识别交通流量较小区域内的相对关键路段。
- Node2Vec和Word2Vec的结果表现为关键路段更多地分布于路网密度高的区域,这可能是因为它们更关注路段的相对位置和连接关系,而非实际的交通关联。
- 本方法在交通流覆盖率、局部交通流承担率和局部交通流关联性等多个指标上表现优异,特别是在3阶交通流覆盖率和第2、3阶局部交通流关联性方面具有明显优势。
局部区域相对关键路段分布
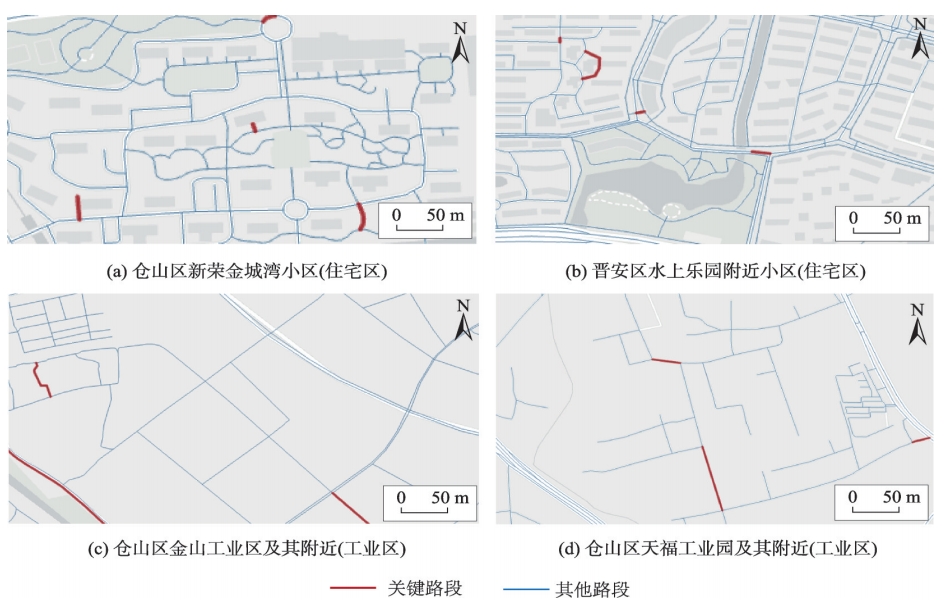
图5:各区域相对关键路段分布示意图
从识别结果可以看出,本方法在交通流量较小的局部区域(如住宅区和工业区)内也能识别出一定数量的相对关键路段,这验证了本方法能够有效识别局部区域中的相对关键路段的能力。
结论与讨论
本研究基于手机定位数据和路网数据获取出行路线集并构建交通语料库,通过自然语言处理方法提取各路段的静态和动态嵌入,并提出一种两阶段特征学习的方法来识别关键路段。主要结论如下:
识别结果的合理性
本文方法所识别的关键路段在空间分布上较其他方法更为合理,在各评价指标的整体表现上也优于其他方法,有力地验证了本文方法识别结果的合理性。
两阶段特征学习的优势
基于AP-DC的两阶段特征学习方法能够为可微分聚类提供稳定的初始聚类中心,降低了在初期陷入局部最优的风险,且能使其更快地收敛到一个合理的解。同时,路段的动态嵌入相较于其静态嵌入能提供更为丰富多样的路段表示。
损失函数的设计
AP-DC的损失函数在保证最小化簇内距离与簇间距离比值的同时,还加入了一个约束聚类中心移动量的项,能在参数优化过程中给聚类中心一定的移动空间,同时还能保持它们相对接近初始聚类中心的状态。
局部关键路段识别能力
本文方法在交通流量较小的局部区域内也可以识别出一定数量的相对关键路段,这可能归因于路段多种动态表示通过注意力池化得到了合理平衡,且融合静态和动态嵌入后的路段特征既考虑了路段间的真实连接关系,又反映了其在不同出行路线中的多种表示。
本研究需要进一步改进的方面包括:
- 进一步结合出租车GPS数据和真实路网监测数据,以获取各出行起讫点间更为精确的实际出行路线信息。
- 扩展至多日数据分析,以挖掘关键路段在不同日期内的变化规律,从而总结出适用于大多数日期的关键路段集合。
- 探讨融合BERT等更先进的自然语言处理模型,以更深入地捕捉路段的动态嵌入。
研究价值
- 提供了一种新的关键路段识别方法,可应用于大规模城市路网
- 能够识别局部区域中的相对关键路段,有助于更全面的交通管理
- 将自然语言处理技术应用于交通数据分析,开拓了交叉学科研究新思路