研究方法
算法框架
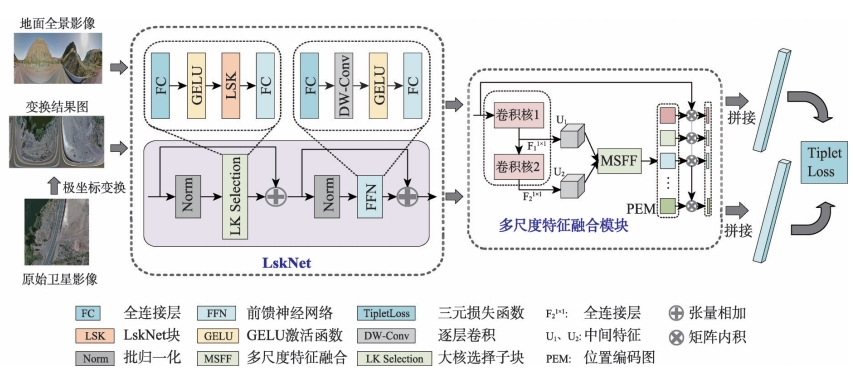
图1 基于多尺度特征聚合的轻量化跨视角图像匹配算法框架
其中:dpos和dneg表示正对和负对之间的余弦相似性;α是用来调整损失梯度的参数,可以控制收敛速度,本文将α设为20。在一个有N对街景影像和卫星影像的批次中,共采样2N×(N-1)个三元组。
跨视角图像匹配与定位是指通过将地视查询影像与带有地理标记的空视参考影像进行匹配,从而确定地视查询影像地理位置的技术。目前的跨视角图像匹配与定位技术主要使用固定感受野的CNN或者具有全局建模能力的Transformer作为特征提取主干网络,不能充分考虑影像中不同特征之间的尺度差异,且由于网络参数量和计算复杂度较高,轻量化部署面临显著挑战。
解决现有跨视角图像匹配技术中多尺度特征处理不足和模型过重的问题,设计一种轻量化且高精度的匹配定位方法。
提出基于多尺度特征聚合的轻量化跨视角匹配定位方法,使用LskNet提取特征,并设计多尺度特征聚合模块生成全局描述符。
在VIGOR、CVUSA和CVACT数据集上取得优异性能,同时模型参数量和计算量显著降低,仅为现有最优方法的34.36%和23.70%。
跨视角图像匹配面临的主要挑战:
本文提出的多尺度特征聚合模块核心优势:
随着科技的飞速进步,全球导航卫星系统(GNSS)已深刻地改变了人类的日常生活模式,在社会各领域中扮演着不可或缺的角色。然而GNSS信号易受环境和电磁信号干扰的特点使它无法完全满足复杂场景下定位、导航等服务的需要,因此,研究GNSS拒止或干扰环境下的高效地理定位技术具有重要意义。
近年来,由于卫星影像和航拍图像覆盖范围广且易于获取,基于跨视角图像匹配的地理定位技术逐渐引起人们的关注。基于跨视角图像匹配的地理定位技术,是指通过一定的算法框架,在预先构建的带有地理信息的参考空视图像数据库中,匹配并识别与查询图像(无人机、卫星、地面图像等)最为相似的参考图像,从而获得查询图像地理位置的技术。
由于拍摄视角不同,卫星影像与地面全景图像之间存在显著的域差距,这包括物体的外观以及空间布局之间的差异。具体而言,地面全景图像中主要包含建筑物、植被等目标的侧面信息;而卫星影像主要从目标区域的俯视视角拍摄,获取的主要是屋顶、树冠等地物的上表面信息。
目前大多数的跨视角图像匹配研究都集中在视角转换以及全局特征提取方法上,忽略了影像中特征的差异性以及模型的资源消耗问题,具体而言,这些问题可以概括为以下3个方面:
针对上述问题,本文充分考虑影像中的多尺度特征以及模型部署时的硬件资源消耗问题,设计了一种面向地面全景影像和卫星影像的多尺度特征聚合轻量化跨视角图像匹配与定位方法。
图1 基于多尺度特征聚合的轻量化跨视角图像匹配算法框架
其中:dpos和dneg表示正对和负对之间的余弦相似性;α是用来调整损失梯度的参数,可以控制收敛速度,本文将α设为20。在一个有N对街景影像和卫星影像的批次中,共采样2N×(N-1)个三元组。
包含35,532对训练图像和8,884对测试图像,是跨视角匹配领域使用最广泛的公共数据集之一。
提供了35,532对图像用于训练,8,884对图像用于验证,卫星图像使用谷歌地图API下载。
包含105,214张全景影像和90,618张卫星影像,全景影像不是严格在卫星影像的中心位置采集,更符合实际应用场景。
| 算法 | R@1 (%) | R@5 (%) | R@10 (%) | R@1% (%) | Hit Rate (%) |
|---|---|---|---|---|---|
| GeoDTR | 56.51 | 80.37 | 86.21 | 99.25 | 61.76 |
| GeoDTR+ | 59.01 | 81.77 | 87.10 | 99.07 | 67.41 |
| TransGeo | 61.48 | 87.54 | 91.88 | 99.56 | 73.09 |
| SAIG-D | 65.23 | 88.08 | - | 99.68 | 74.11 |
| Sample4Geo | 77.86 | 95.66 | 97.21 | 99.61 | 89.82 |
| 本文算法 | 79.00 | 95.65 | 97.18 | 99.77 | 93.96 |
由实验结果可知,本文算法在VIGOR数据集上的R@1、R@5、R@10、R@1%召回率分别达到79.00%、95.65%、97.18%、99.77%,在R@1上的召回率优于其他跨视角图像匹配方法,相比于TransGeo、SAIG-D和Sample4Geo算法分别高出17.52%、13.77%、1.14%。对于Hit Rate指标,本文算法达到93.96%,比目前精度最高的Sample4Geo提高4.14%。
| 算法 | R@1 (%) | R@5 (%) | R@10 (%) | R@1% (%) |
|---|---|---|---|---|
| SAFA | 89.84 | 96.93 | 98.14 | 99.64 |
| DSM | 91.93 | 97.50 | 98.54 | 99.67 |
| L2LTR | 94.05 | 98.27 | 98.99 | 99.67 |
| TransGeo | 94.08 | 98.36 | 99.04 | 99.77 |
| GeoDTR+ | 95.40 | 98.44 | 99.05 | 99.75 |
| Sample4Geo | 98.68 | 99.68 | 99.78 | 99.87 |
| 本文算法 | 98.64 | 99.50 | 99.67 | 99.85 |
由实验结果可知,本文算法在CVUSA数据集上的R@1、R@5、R@10、R@1%召回率分别达到98.64%、99.50%、99.67%、99.85%,R@1召回率仅比Sample4Geo低0.04%,高于其他几种算法3.21%以上。根据实验数据,本文提出的算法在显著减少模型参数和计算量的同时,能够达到与当前先进算法几乎相同的精度。
| 算法 | R@1 (%) | R@5 (%) | R@10 (%) | R@1% (%) |
|---|---|---|---|---|
| SAFA | 81.03 | 92.80 | 94.84 | 98.17 |
| DSM | 82.49 | 92.44 | 93.99 | 97.32 |
| CDE | 83.28 | 93.57 | 95.42 | 98.22 |
| L2LTR | 84.89 | 94.59 | 95.96 | 98.37 |
| GeoDTR+ | 87.61 | 95.48 | 96.52 | 98.34 |
| Sample4Geo | 90.81 | 96.74 | 97.48 | 98.77 |
| 本文算法 | 91.43 | 96.90 | 97.69 | 98.92 |
由实验结果可知,本文算法在CVACT数据集上的R@1、R@5、R@10、R@1%召回率分别达到91.43%、96.90%、97.69%、98.92%,均高于其他算法。对于R@1召回率,本文算法相比于SHE、GeoDTR+、Sample4Geo,分别高出6.68%、3.82%、0.62%,达到目前领先精度。
| 算法 | CVUSA | VIGOR | ||||||
|---|---|---|---|---|---|---|---|---|
| 参数量/M | 共享权重 | 计算量/GFLOPs | R@1/% | 参数量/M | 共享权重 | 计算量/GFLOPs | R@1/% | |
| 本算法 | 28.85 | × | 9.41 | 98.64 | 30.09 | × | 16.05 | 79.00 |
| TransGeo | 44.92 | × | 11.34 | 94.08 | 45.18 | × | 25.96 | 61.48 |
| Sample4Geo | 87.57 | √ | 30.50 | 98.68 | 87.57 | √ | 67.71 | 77.86 |
| L2LTR | 195.91 | × | 44.16 | 94.05 | × | × | × | × |
为了减少模型的参数量和计算复杂度,本算法将大卷积核分解,同时使用了大量的逐层卷积,通过表中的实验数据可知,本文模型在参数量与计算成本上显著低于其他算法。相比于TransGeo、Sample4Geo、L2LTR算法,本文算法在CVUSA数据集上的参数量分别降低了16.07、58.72、167.06 M,计算复杂度分别降低了1.93 GFLOPs、21.09 GFLOPs、34.75 GFLOPs。
| R@1 (%) | R@5 (%) | R@10 (%) | R@1% (%) | Hit Rate (%) | |
|---|---|---|---|---|---|
| 单个大卷积核 | 77.12 | 94.42 | 96.38 | 99.75 | 92.10 |
| 卷积核分解 | 79.00 | 95.65 | 97.18 | 99.77 | 93.96 |
由表中数据可知,将单个大卷积核分解成一系列相对较小的逐层卷积后,模型的R@1匹配精度从原来的77.12%提升到79.00%,Hit Rate指标从92.10%提升到93.96%,这证明了卷积核分解在生成图像全局特征描述符中的作用。
| 算法 | VIGOR | CVUSA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1% | R@1 | R@5 | R@10 | R@1% | ||
| 基线模型 | 65.52 | 89.99 | 93.69 | 99.66 | 97.04 | 99.26 | 99.47 | 99.88 | |
| 基线模型+MixVPR | 72.74 | 92.52 | 95.13 | 99.69 | 97.34 | 99.38 | 99.57 | 99.86 | |
| 基线模型+SAFA | 77.87 | 95.19 | 97.02 | 99.77 | 98.19 | 99.50 | 99.66 | 99.84 | |
| 本算法 | 79.00 | 95.65 | 97.18 | 99.77 | 98.64 | 99.50 | 99.67 | 99.85 | |
实验结果表明,多尺度特征聚合模块的引入带来了显著的性能提升,相比于基线模型、MixVPR、SAFA,本文算法在VIGOR数据集上的R@1精度分别提升了13.48%、6.26%、1.13%,在CVUSA数据集上分别提升了1.60%、1.30%、0.45%,进一步验证了该模块在跨视角图像匹配任务中的有效性。
为了进一步探索本文模型在提取卫星影像和地面全景影像的特征时所关注的区域,本研究使用Grad-CAM来显示图像中对于图像特征编码贡献较大的区域。

图2 可视化结果
对于地面全景影像,本文网络着重关注影像中的道路信息以及建筑物信息,而很少关注如天空等对于匹配任务贡献度较低的背景区域,这与人眼进行跨视角匹配时所关注的区域相吻合。在卫星影像中,当道路等关键信息被树木遮挡或与周围建筑在视觉特征上相近时,本文网络依然能够将注意力集中在道路等关键匹配要素上,这表现出本文模型在困难场景下进行影像匹配的优势。
本文针对跨视角图像匹配任务中多尺度特征和空间布局信息的提取、聚合,以及模型的轻量化问题,设计了一个基于多尺度特征聚合的轻量化跨视角图像匹配与定位方法,首先使用LskNet提取影像特征,然后设计了一个多尺度特征聚合模块,将影像特征聚合为全局描述符。
在该模块中,本文将一个大卷积核分解为2个连续的相对较小的逐层卷积,显著减少了模型的参数量并将影像的多尺度特征整合成位置编码图,最后使用位置编码图将影像特征聚合为全局描述符。
本文算法在VIGOR、CVUSA和CVACT 3个公开数据集上的R@1召回率分别达到79.00%、98.64%、91.43%,在VIGOR和CVACT数据集上均为当前最高精度。此外,本文算法在保证模型匹配精度的同时,大大减少了模型的参数量和计算量,相比于Sample4Geo,本文算法在VIGOR数据集上的参数量从87.57 M下降到30.09 M,计算量从67.71 GFLOPs下降到16.05 GFLOPs,计算量仅为Sample4Geo的23.7%,大大减少了模型部署对硬件的要求。
本文方法虽然在目前的公开跨视角图像匹配数据集中取得了一定的成果,但仍有一些问题需要优化:
* 以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。