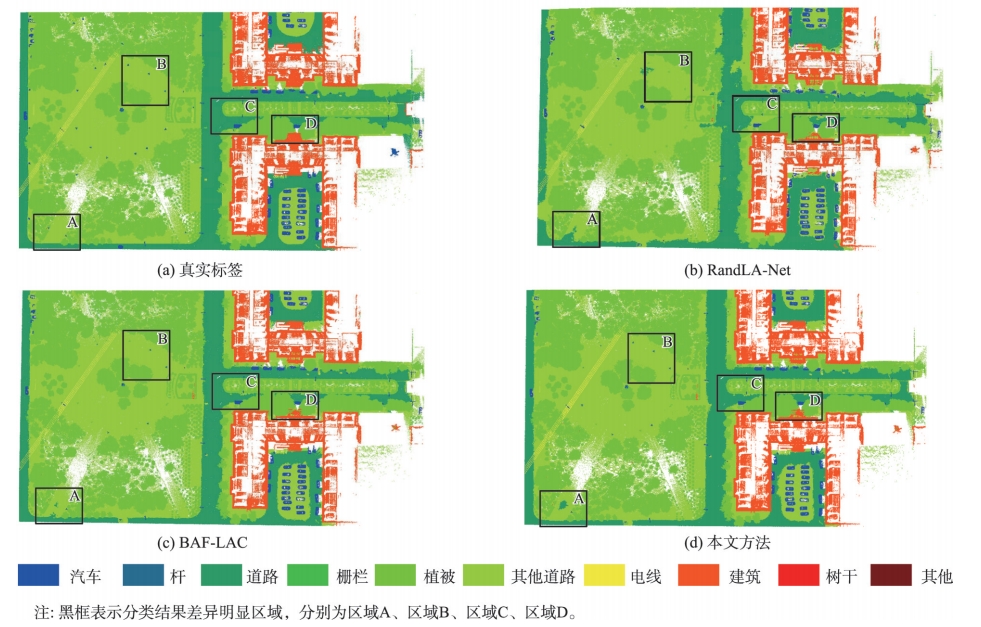
研究方法
技术路线
图1:顾及局部-全局特征多尺度卷积注意力网络的点云地物分类方法技术路线
本文提出的多尺度卷积注意力网络遵循RandLA-Net的主要框架。在编码层,随机采样、多尺度卷积注意力模块和自适应加权池化模块逐层堆叠,其中多尺度卷积注意力模块由局部动态图卷积模块和全局图注意力模块组成。
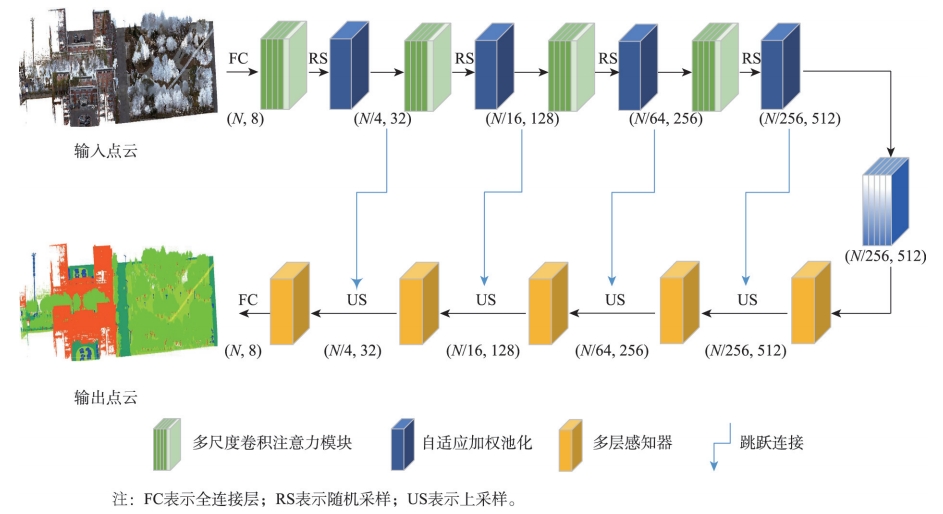
图2:网络整体框架
局部动态图卷积模块
基于中心点和邻域点的位置关系学习一个系数向量自适应生成卷积权重,提出了一种局部动态图卷积方法。
eij = h(Δpi⊕||Δpi||⊕npki)
Wij = exp(-||pi - pij||²/2)
Flocal = MaxPool(h(eij ⊗ Wij))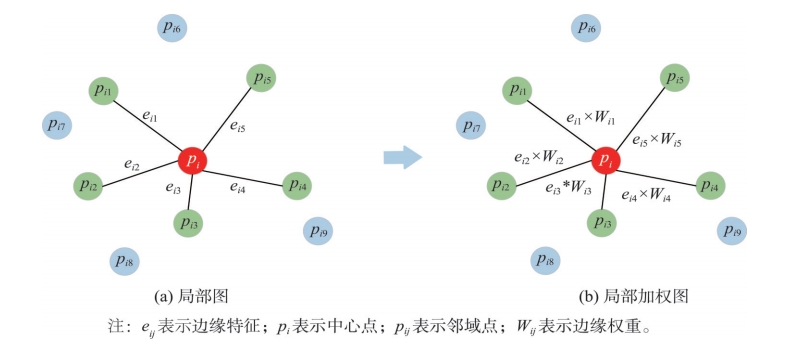
图3:局部加权图
全局图注意力模块
通过构造局部加权图的邻接矩阵并更新每个节点的特征,利用自注意机制计算相邻节点之间的相关性,建立中心点与其邻域点之间的关系以及邻域点之间的依赖关系。
cij = h((ϕ[Δpi⊕Δfi])T ⊗ φ([Δpi⊕Δfi]))
αij = softmax(cij) = exp(cij) / ∑exp(cij)
F′global = ∑αij·h(Fglobal + bi)自适应加权池化
为了有选择地聚合高维特征,同时捕捉点云的局部特征并加强全局特征的聚合,本文在最大池化和平均池化相结合的基础上,加入自适应权重,更充分地学习特征融合后网络在不同池化层中的有价值特征。
wmax = σ(conv1d(MaxPool(Fki),k))
wavg = σ(conv1d(AvgPool(Fki),k))
F͂i = (wavg + wmax)Fki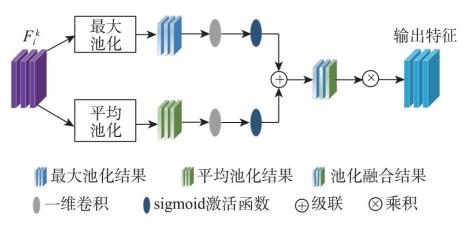
图4:自适应加权池化模块