研究背景
人口数据作为一种基础的地理数据,在地理相关研究中发挥着重要的作用,也常用于城市规划与开发、灾害风险评估与救援、公共卫生安全等领域。随着全球城市化的进程不断推进,城市人口数量激增、城市所面临的资源环境压力日益增强。人口的空间分布状况能直观地反映人类活动,快速准确地获取人口空间分布信息对解决城市资源环境问题至关重要。
传统的人口数据通常通过行政区进行人口普查等统计手段获取,存在更新周期长、可视化和空间分析困难等问题。伴随着GIS、遥感等技术快速发展,人口数据空间化逐渐成为学术界重要的研究方向之一。
人口空间化是基于一定的数学方法将行政单元的人口数据映射到地理格网上,实现信息表达载体的转换,模拟出现实中人口的地理分布。目前,国内外学者就人口空间化开展了诸多研究,并取得丰硕成果。由早期的定性探讨逐渐发展为用半定量或定量的手段来探究人口的空间分布规律。
山地城市地形地貌结构复杂,开发多结合地区的本底条件,依山就势、顺水而建,形成多种多样的组团结构。其人口分布受自然山水条件制约和社会经济发展的驱动,在水平空间和垂直空间都表现出比平原城市更显著的差异性和复杂性。目前,对山地城市的人口空间化研究多侧重于通过多因素融合模型定量描述因子与人口分布的关系,但存在权重确定过程复杂的问题;也有通过对比来分析不同数据集模拟山地城市人口的适宜性,但模拟结果仍存在明显高估和明显低估的区域,并未能准确反映山地城市的人口分布。
研究方法
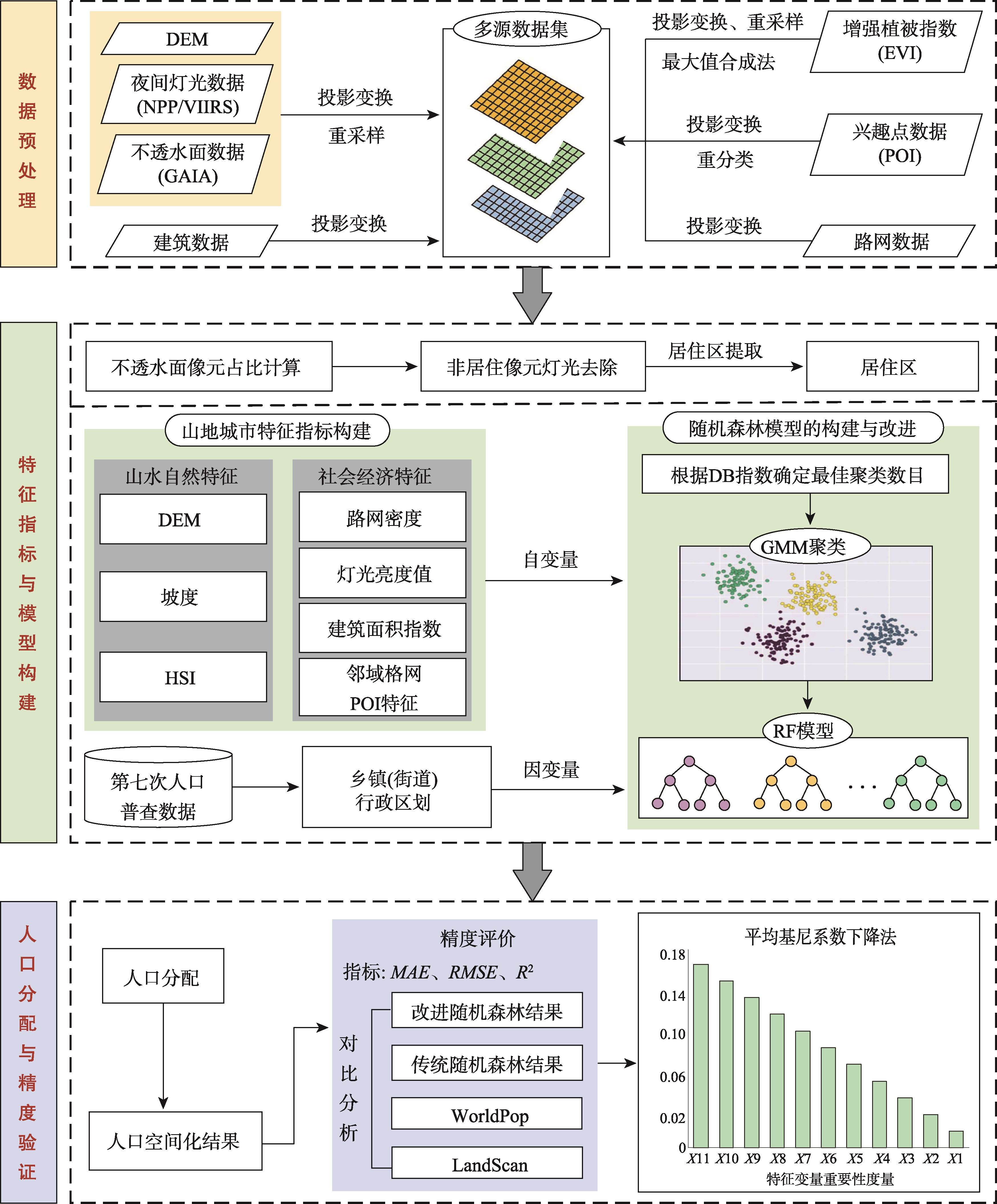
图1:本文方法总体流程
为了提高模型预测精度,准确反映山地城市人口分布情况,本文提出了一种基于居住区识别和改进随机森林的山地城市人口空间化方法。该方法主要包括以下几个步骤:
数据预处理
数据预处理主要包括投影转换与重采样、格网构建、POI(Point of Interest)分类和增强植被指数(Enhanced Vegetation Index, EVI)提取。首先将所有空间数据统一投影为WGS-1984-Albers坐标系。其次,为避免将最小居住单位全部落入同一个格网,参考相关文献,本文以实验区最小乡镇(街道)面积的10%构建格网,即格网大小设置为150 m×150 m。然后,将空间数据重采样到格网大小。
居住区识别与提取
为避免将人口分配到无人居住区,本文参考住房空置的估算模型,将居住区定义为用地类型为不透水面且夜晚可以监测到灯光的区域,并基于夜间灯光数据和不透水面数据进行了居住区识别。
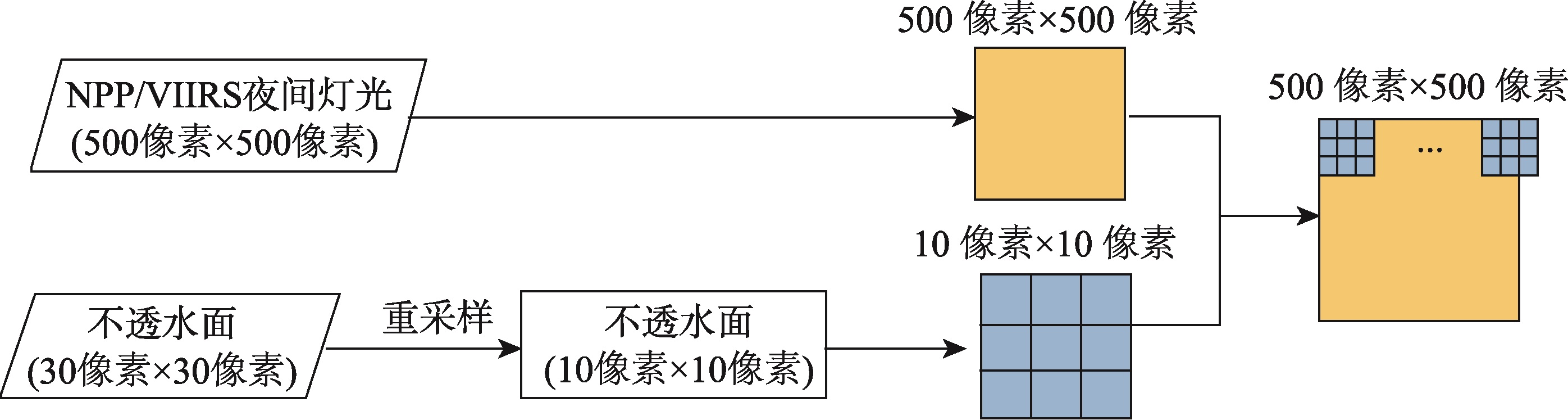
图2:不透水面像元占比计算流程
山地城市特征指标构建
本文构建了山水自然特征和社会经济特征两类指标。山水自然特征包括DEM、坡度和人类居住指数(Human Settlement Index, HSI);社会经济特征包括灯光亮度值、路网密度、建筑面积指数(Building Area Index, BAI)和邻域格网POI特征。
随机森林模型的构建与改进
为减小跨尺度的误差,本文先将各特征变量提取到居住区格网,再汇总到乡镇(街道)单元。以乡镇(街道)的人口密度为因变量,11个特征变量为自变量输入样本。采用GMM聚类算法对输入的特征变量进行聚类处理,利用Bootstrap方法从各簇中分别随机抽取相等数目的数据,形成新的变量数据集,以此替代原始变量数据集进行采样,弥补原始变量数据集不平衡的特点。
人口分配与精度验证
由改进随机森林模型得到的格网人口预测值需要根据实际区域人口数进行总量控制。本文将经过人口分配后的格网人口数汇总到乡镇(街道)尺度,采用平均绝对值误差(Mean Absolute Error, MAE)、均方根误差(Root Mean Square Error, RMSE)和决定系数(R²)3个指标来衡量精度。
实验区概况
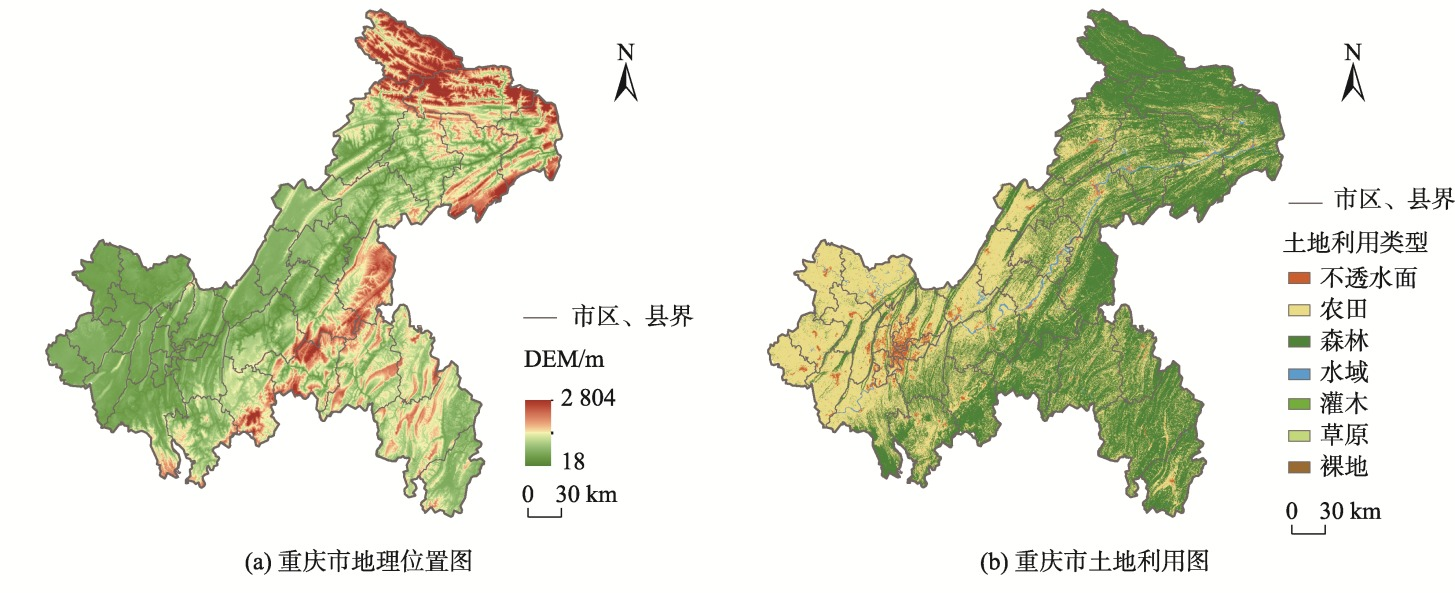
图3:重庆市地理位置及土地利用图
重庆市位于中国的西南部,在105°11′ E—110°11′ E,28°10′ N—32°13′ N之间,总面积8.24万km²,是西南地区和长江上游最大的经济中心城市。重庆市自然资源丰富,地势起伏大,地貌类型多样,素有山城之称。
作为中国西部人口重要的聚居地之一,重庆市人口众多,2023年末常住人口已达到3100多万。其人口主要集中分布在浅山丘陵的中西部地区,而位于大巴山山脉和巫山山脉的东北部地区以及武陵山脉的东南部地区的人口分布较为稀疏。
作为典型的山地城市,重庆市的山地和丘陵占全市总面积的98%,各区县人口规模及密度差异极大。因此,选择重庆市作为实验区域开展人口空间化具有典型性。
实验结果与分析
居住区识别
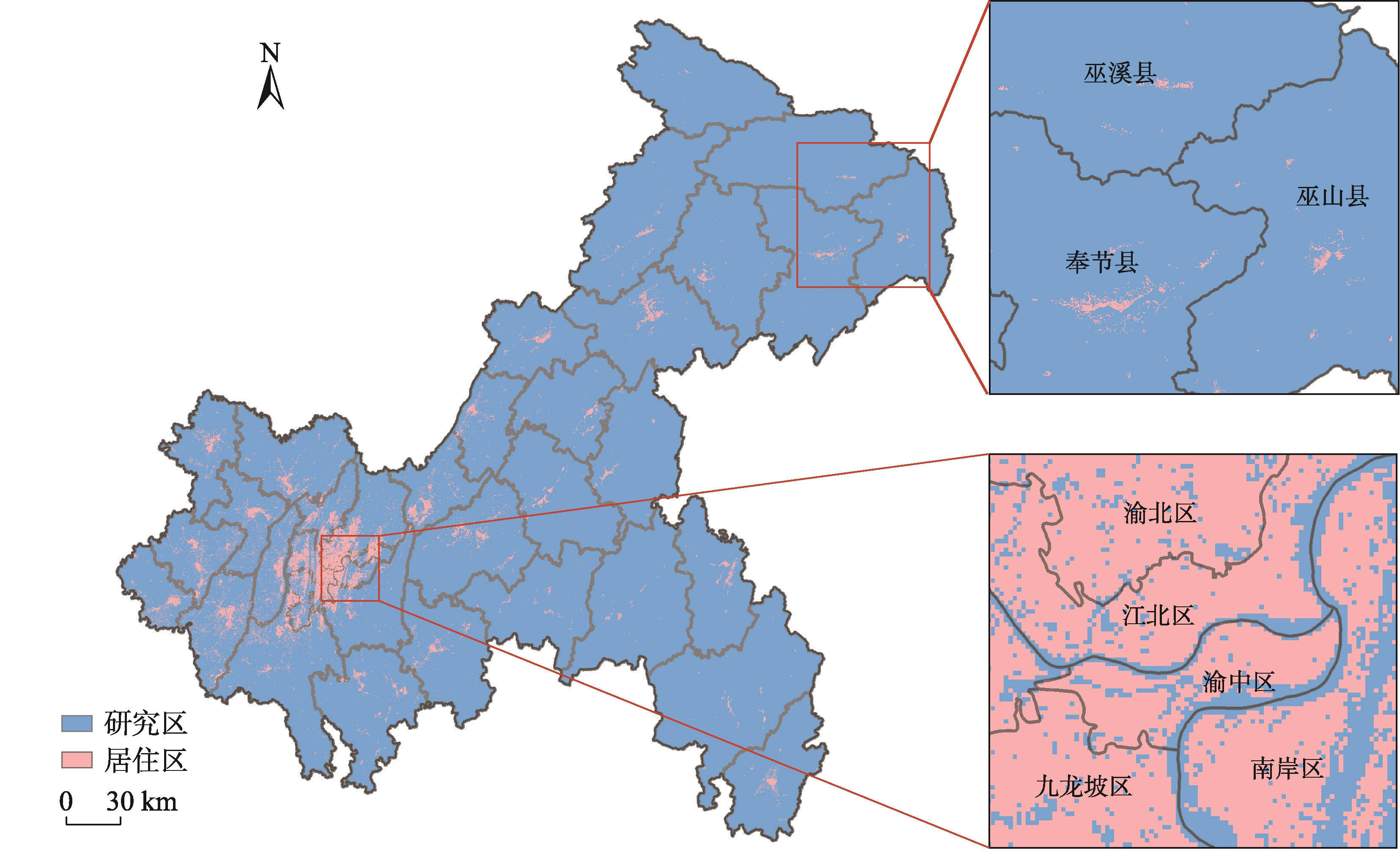
图4:重庆市居住区识别结果
基于夜间灯光数据和不透水面数据对实验区的居住区识别结果如图4所示,其分布呈现明显的空间差异性。将居住区与高程进行叠置分析,可以发现居住区集中分布在地势平缓的浅山丘陵区,随着高程的增加,地势起伏度变大,居住区逐渐减少。
其中,位于政治和经济发展中心的中、西部地区,居住区分布较为密集,且以中部中心城区的居住区分布最广、最集中;北部的居住区主要分布在地势相对平坦的山岭之间;而地形相对崎岖、山体较多,离政治经济中心较远的东北部和东南部区域的居住区分布则较为稀疏,这也与实验区重庆市人口分布现状相符。
核密度带宽验证选取实验
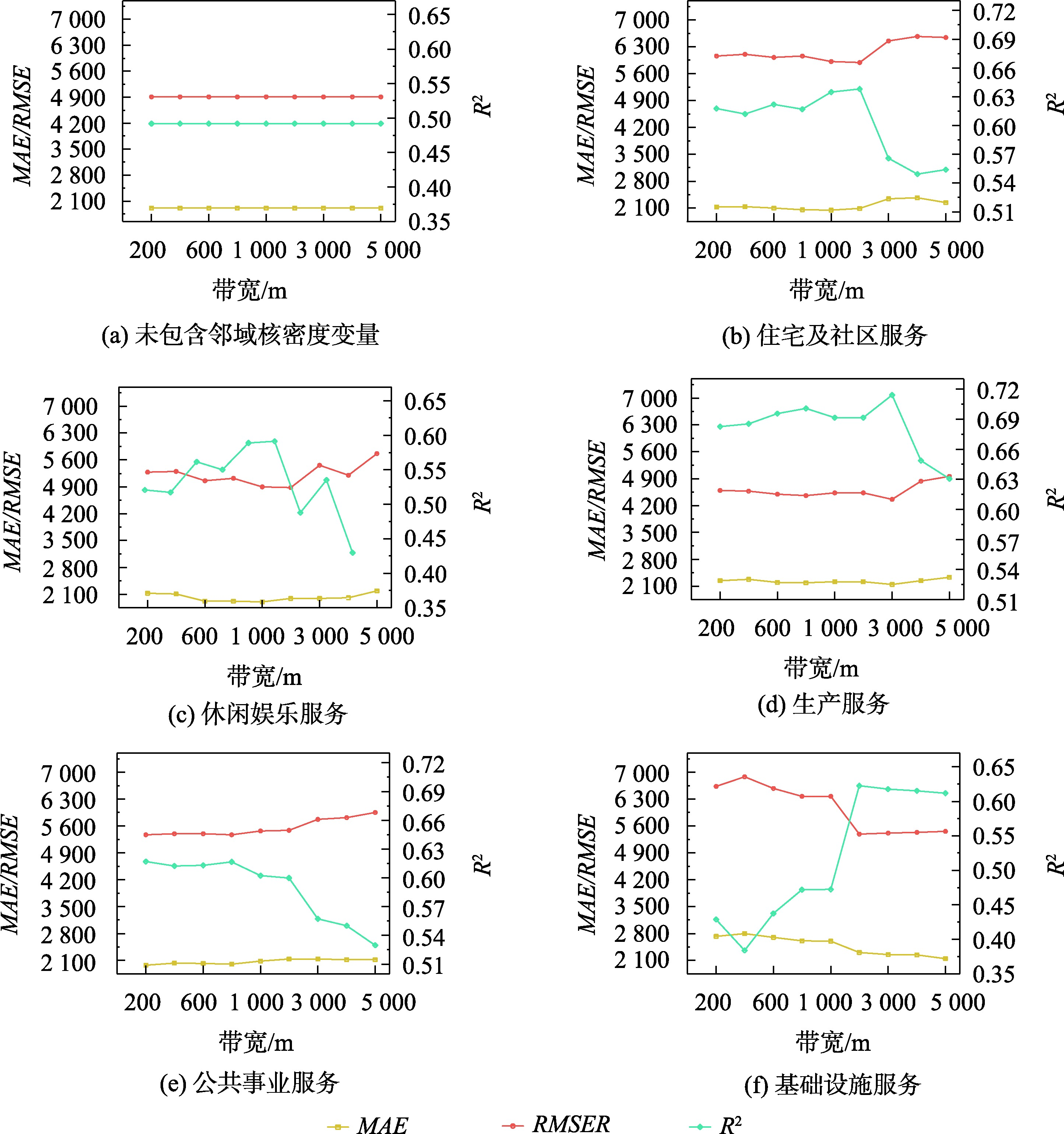
图5:POI带宽选取实验结果
不同类型的POI的服务范围不同,且带宽为核密度估计的主要参数。为选取最佳带宽,提高模型精度,本文通过实验探究了9种不同带宽对模型精度的影响。实验设置的带宽范围为200~5000 m,其中200~1000 m带宽之间的间距为200 m,1000~5000 m带宽之间的间距为1000 m。
由实验结果可知,不同类型的POI的最佳服务范围不同,且在各自的最佳带宽内,各类POI都对模型精度有所提高。最终,各类POI的相对最佳带宽取值分别为:住宅及社区服务选用2 km带宽、休闲娱乐服务选用2 km带宽、生产服务选用3 km带宽、公共事业服务选用1 km带宽,基础设施服务选用5 km带宽。
人口空间化结果
图6:2020年重庆市150 m格网空间分辨率的人口分布
由改进随机森林模型学习及人口分配后得到2020年重庆市150 m格网空间分辨率的人口分布图(图6)。整体来看,重庆市的人口呈现以中部地区集聚,周边多核分布的空间结构。其中,人口主要集中分布在长江、嘉陵江沿岸的中部区域,以渝中区、江北区、渝北区西南部、沙坪坝区东南部和南岸区西部为中心向四周渐次减少;西部区域的人口以多中心的结构分散分布在中部区域周围;北部人口主要分布在平行岭谷区,以开州区、万州区和云阳县的人口较为集中;东北部和东南部人分布稀疏,因为其山体较多,地形崎岖且离经济发展中心的中部较远,人口较少,只有东北部的巫山县和巫溪县、东南部的黔江区和秀山县人口相对较多。
精度验证
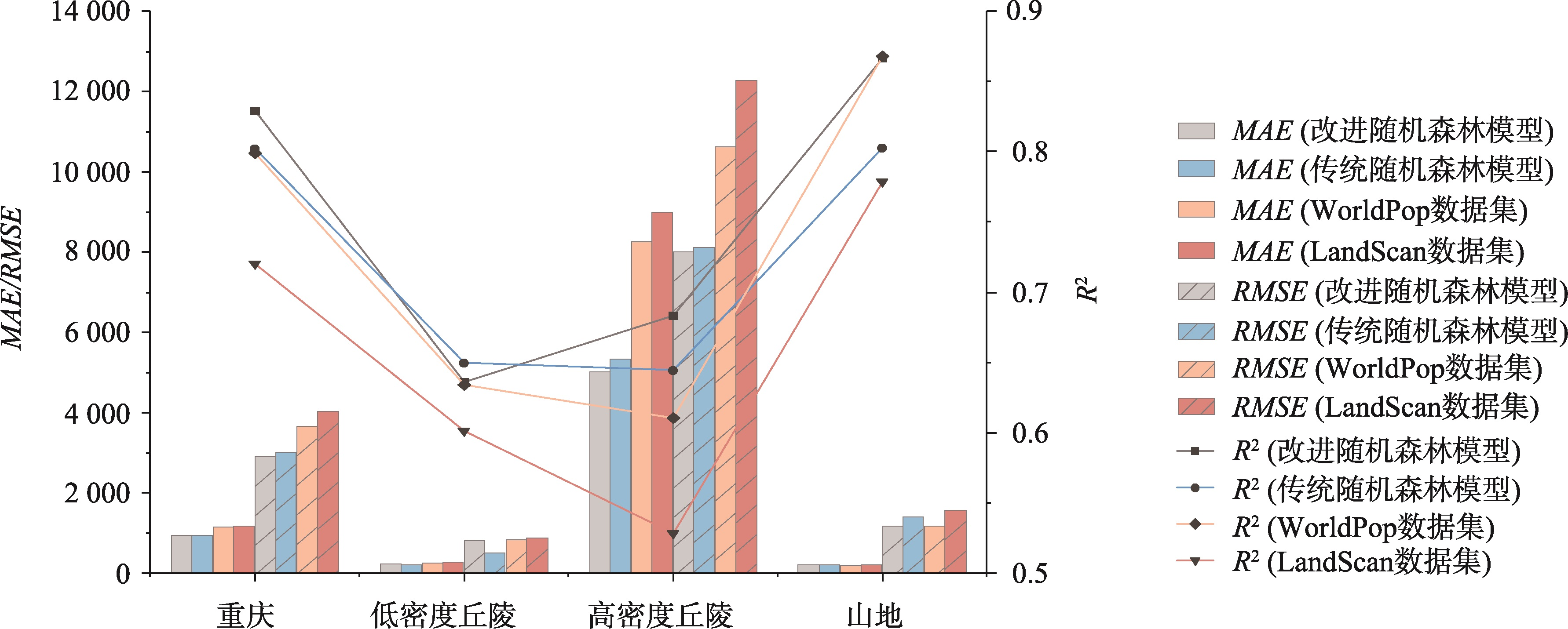
图7:精度检验指标计算结果
由于山地城市人口空间分布与地形密切相关,且对于不同人口的区域,其人口建模特征的空间分布也存在差异,人口空间化结果也会呈现不同的情况。因此,本文基于坡度和人口密度2个指标对实验区进行二次分区。考虑到重庆市特有的山地地形,以坡度25°为阈值,大于25°划为山地,小于25°划为丘陵;在此基础上,以丘陵地区人口密度的平均值为阈值,高于平均值的划分为高密度丘陵,低于平均值的划分为低密度丘陵。
从整个实验区重庆市来看,本文模拟结果的MAE为944.104、RMSE为3090.29、R²为82.9%,其中,MAE和RMSE均低于其余3个数据集,R²均高于其余3个数据集。与传统随机森林模型相比,本文模拟结果的R²增加了2.7%;与WorldPop数据集和LandScan数据集相比,本文模拟结果的MAE分别减少了212.63和35.11,RMSE分别降低了1354.34和524.54,R²分别提高了2.94%和10.91%,说明改进随机森林模型提高了整体的模拟精度。
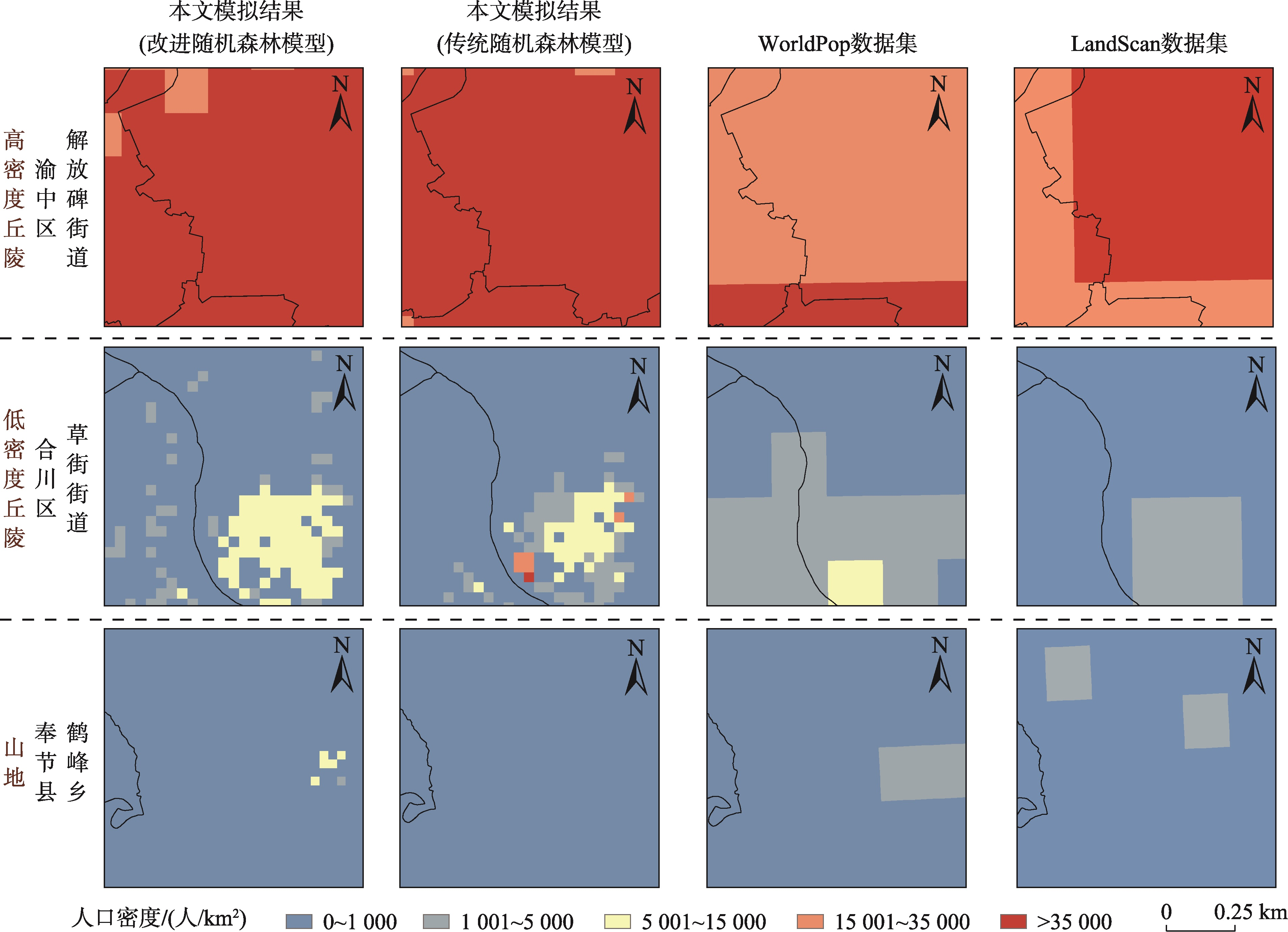
图8:4个数据集在不同分区区域的空间显示效果
为进一步比较不同数据集在不同分区的空间化结果,本文分别选取了高密度丘陵、低密度丘陵和山地的乡镇(街道)进行空间化结果展示,如图8所示,从上到下依次为渝中区解放碑街道、合川区草街街道和奉节县鹤峰乡。整体来看,人口密度的分布趋势在4个数据集中大致一致,但本文相对于WorldPop数据集和LandScan数据集展现了更为丰富的人口密度信息,在不同密度和不同地形的区域反映出更明显的人口分布异质性,同时也减少了人口在非居住区的数量,更加符合山地城市人口的分布情况。
因子重要性排序
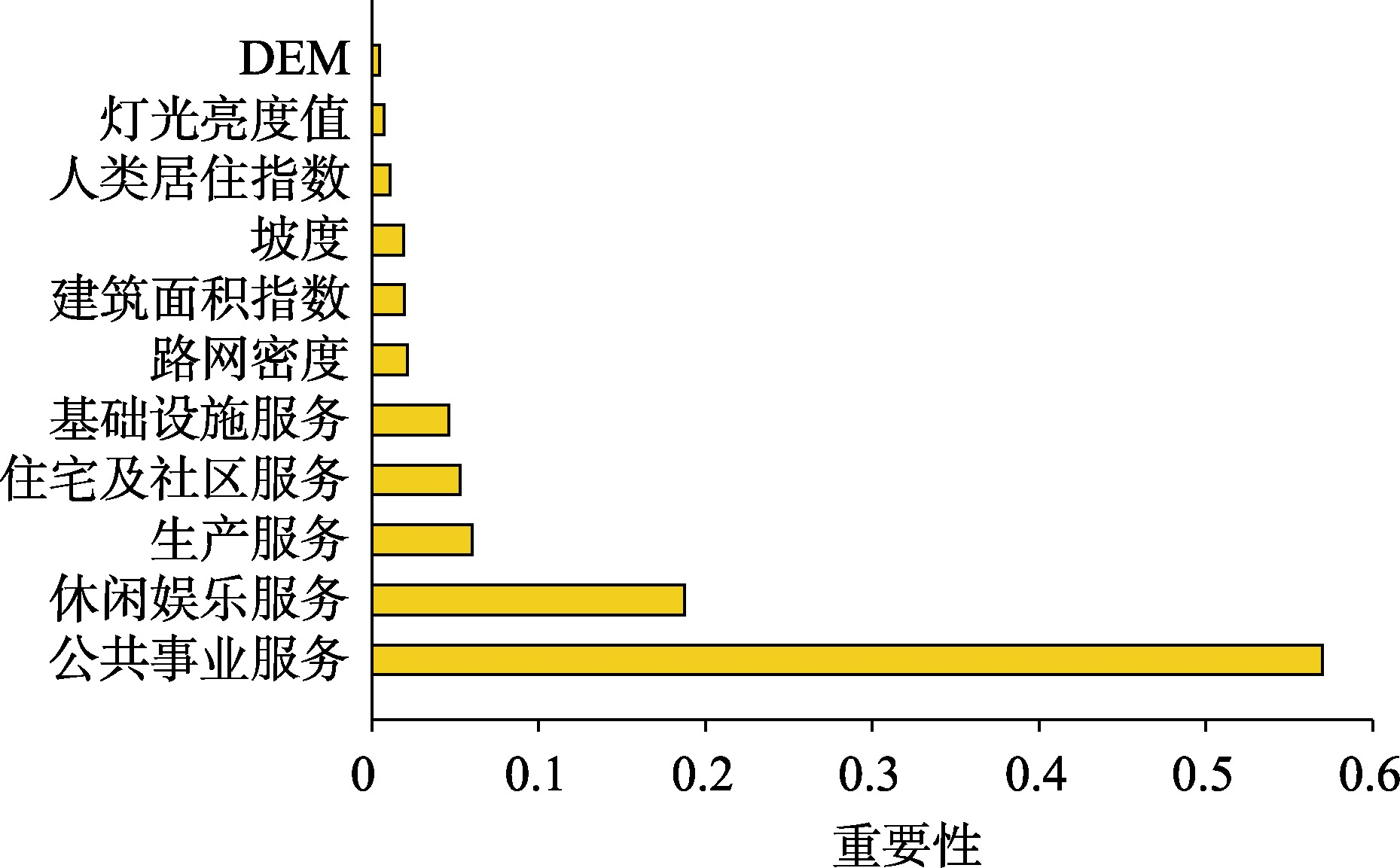
图9:随机森林模型特征变量重要性结果
本文基于随机森林模型的袋外估计值,采用平均基尼系数下降法对特征变量因子的重要性进行度量。得到的值越大,说明该变量因子对随机森林回归的作用越大。
由图9可知,POI是模拟人口分布最重要的特征变量,路网密度、建筑面积指数和坡度对人口分布也具有较为重要的作用。POI与人类活动密切相关,能很好地反映城市内部的人口分布。其中,公共事业服务类和休闲娱乐类的POI最为重要。公共事业服务类POI包括医疗服务和科研教育,休闲娱乐类POI包括购物、体育休闲和旅游,这些都与城市的公共服务发展程度和精神文化建设息息相关。
反映出随着经济发展到一定水平,人们从对基本物质生活的满足过渡到对优良医疗、教育资源的需求和丰富精神生活的追求,并将其作为居住地选择的重要条件。随着城市的快速扩张,城市的道路交通逐步完善,建设用地形成建成区,建筑越来越多,建筑周边设施的逐渐齐全并吸引了人口的集聚。随着迁入居民的增加,为了出行便捷路网会愈加完善,因此路网密度和建筑面积指数是反映人口分布较为重要指标。同时,山地城市的扩张也要考虑地形坡度的影响,因此坡度对人口分布也较为重要。但总的来说,与自然因素相比,社会经济因素与人口分布的相关性更高。
结论与讨论
研究结论
- 本文的居住区识别结果呈现明显的空间差异性,与实验区的人口空间分布特征相符合。由邻域POI带宽实验可知,引入邻域核密度特征提高了模型的精度。
- 本文方法应用于整个实验区,得到的模拟结果精度达到82.9%,与传统随机森林模型模拟结果相比,精度提高了2.7%;与WorldPop数据集和LandScan数据集相比,本文方法的MAE分别减少了212.63和35.11,RMSE分别降低了1354.34和524.54,R²分别提高了2.94%和10.91%。因此,本文方法具有较好的预测效果。
- 与平原城市不同,山地城市的人口主要集中在地势相对平缓的丘陵地区,且围绕地域山水布局特征呈现不同的组团式分布;但在地势起伏较大的山地地区,人口分布又较为稀疏。因此,在山地城市实现准确的人口空间化比平原城市更具复杂性。本文方法应用在实验区的高密度丘陵区和山地地区的精度均高于传统随机森林模型和2个已开放的人口数据集,说明本文方法相较于常规人口空间化方法的有效性。
- 与2个开放的人口数据集相比,本文方法的结果在不同人口密度区和不同地形区表现出更加明显的人口分布异质性特征,展现了更为丰富的人口密度信息。
讨论
尽管本文基于夜间灯光数据和不透水面数据对居住区进行了提取,但是由于方法、数据精度等的限制,本文的居住区主要指用地类型为不透水面且夜晚可以监测到灯光的区域。由于夜间灯光数据的分辨率较低且城市存在职住分离的现象,可能导致城市居住区与灯光区不一定完全重合。因此,后续的研究可以考虑用高分辨率遥感影像结合多源数据识别城市功能区,将工业、商业、学校用地等与居住区做出严格划分,提高数据精度。
另外,本文的改进随机森林模型的精度结果较好,但在低密度丘陵区的模拟精度还是不够理想,后续的研究可采用分区建模的思想,针对不同实验区的地形特征和人口密度进行灵活分区建模,并根据分区特点完善特征变量数据集。