研究背景
我国国土面积大、地形复杂多样、气候千变万化,各类地质灾害发生频繁,其中滑坡是发生频率最高、危害最大的地质灾害之一。滑坡易发性评价作为防灾减灾的有效途径,一直是滑坡领域研究的热点问题。基于区域的滑坡编目信息以及影响因子信息,构建滑坡易发性预测模型并实现滑坡易发性等级划分,能够精准高效地预测滑坡灾害的潜在风险并划定危险区域的范围,为防灾减灾工作提供重要的科学依据和决策支撑。
滑坡易发性评价方法
近年来,针对滑坡易发性评价,国内外诸多学者已基于不同理论依据提出多种模型并验证其可行性。目前,易发性评价方法依据发展历程以及评价过程可以分为:知识驱动的定性分析法和数据驱动的机器学习模型定量的方法。
数据驱动的机器学习模型区别于知识驱动模型的主观性,对于数据的相关性以及环境因素依赖性较小,评价过程相对简单且能够更好处理高维复杂数据,其精度显著高于定量分析方法的评价精度,因此,机器学习的定量方法在滑坡易发性评价中运用较为广泛。
负样本选择的挑战
非滑坡负样本是指不会发生滑坡灾害的样本点,无法直接获取。目前常用的负样本选取方法存在随机性强、主观性强等缺点,没有形成统一的模式与标准。
为进一步提升负样本选取质量,有学者提出了易发性法优化非滑坡样本的方法。在机器学习模型建模中,非滑坡负样本的选取质量会对其易发性精度产生较大影响,因此,通过易发性法优化非滑坡样本可以明显提高模型预测精度。
研究意义
怒江洲位于云南西北部,区域内地质灾害频发,且灾害规模较大。准确地开展怒江流域怒江州峡谷段滑坡易发性评价,对区域防灾减灾具有重要的指导意义。为此,本文在提出利用加权信息量模型优化负样本的基础上,选取支持向量机模型、卷积神经网络模和梯度提升决策树模型3种机器学习模型对研究区开展了滑坡灾害易发性评价。在对比不同负样本及不同模型精度的基础上,获取了研究区最优的机器学习模型,实现了研究区滑坡灾害易发性合理分级,探究了研究区易发性的空间分级特征,为该区域滑坡灾害的早期预警提供了重要的技术支持。
研究区概况
怒江发源于青藏高原的唐古拉山并流经云南,纵贯云南省西部,在潞西县流出国境,流入缅甸后改称萨尔温江,是一条较大的国际性河流。怒江流域怒江州峡谷段包括贡山县、福贡县、泸水县的区域,地处98°24′E—99°08′E,25°33′N—28°13′N之间,总面积约10409 km²。
研究区地势北高南低,山高坡陡且起伏较大,海拔高差4371 m。区域内江河发育密集,纵横交错,与特殊的大气环流使该地具有独特的立体气候特征。怒江洲境内降雨时空分布不均,雨季较长,大雨和暴雨持续时间较久。充足降雨导致水土流失严重,土质疏松,地质环境脆弱。
同时,怒江断裂等深大断裂发育,使得岩体受力挤压、破坏,降低了坡体的稳定性,为滑坡灾害的发生提供有利条件,也使得该区域成为云南省地质灾害最严重的地区之一。
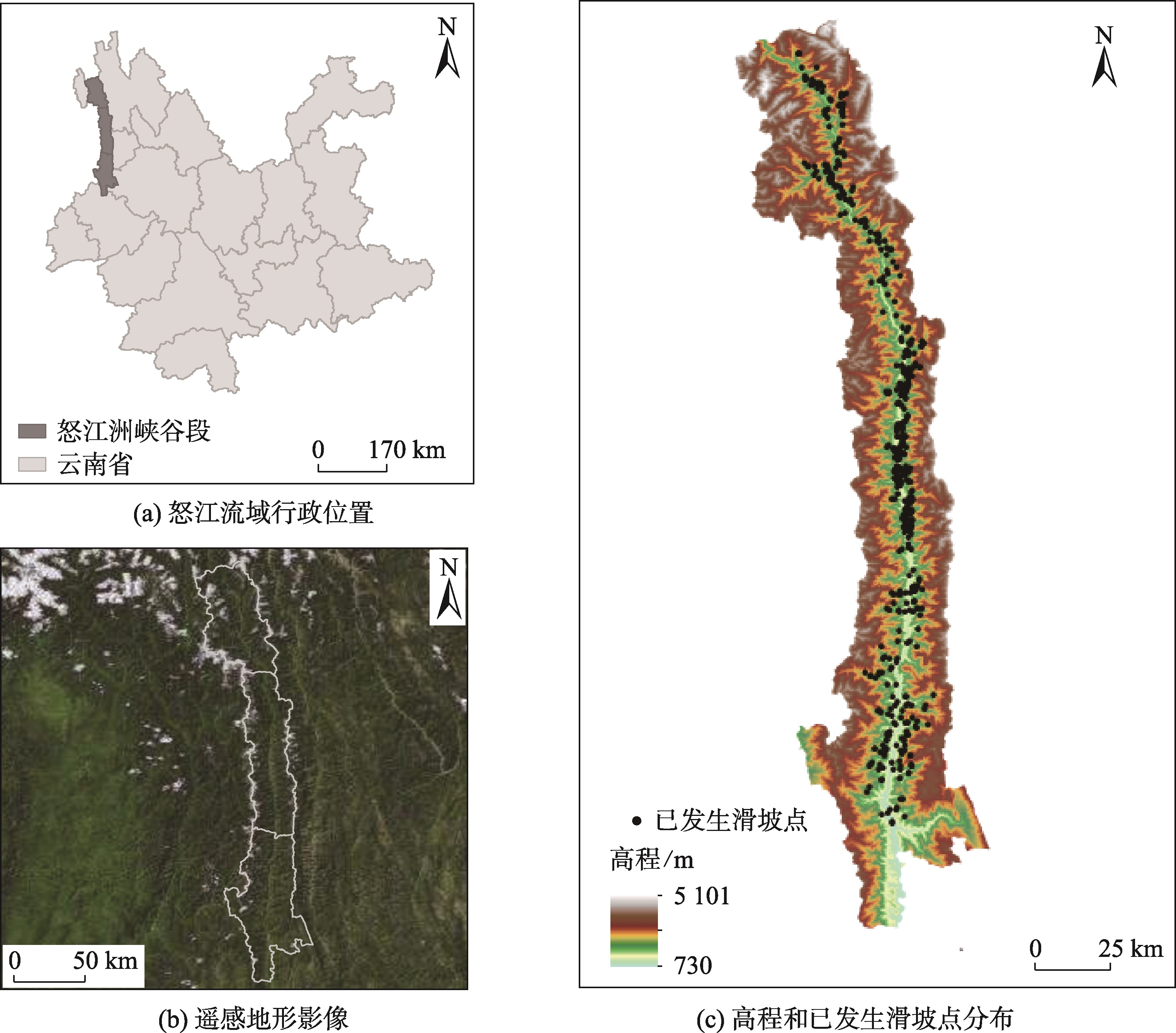
图1 怒江州峡谷段地理概况
研究方法
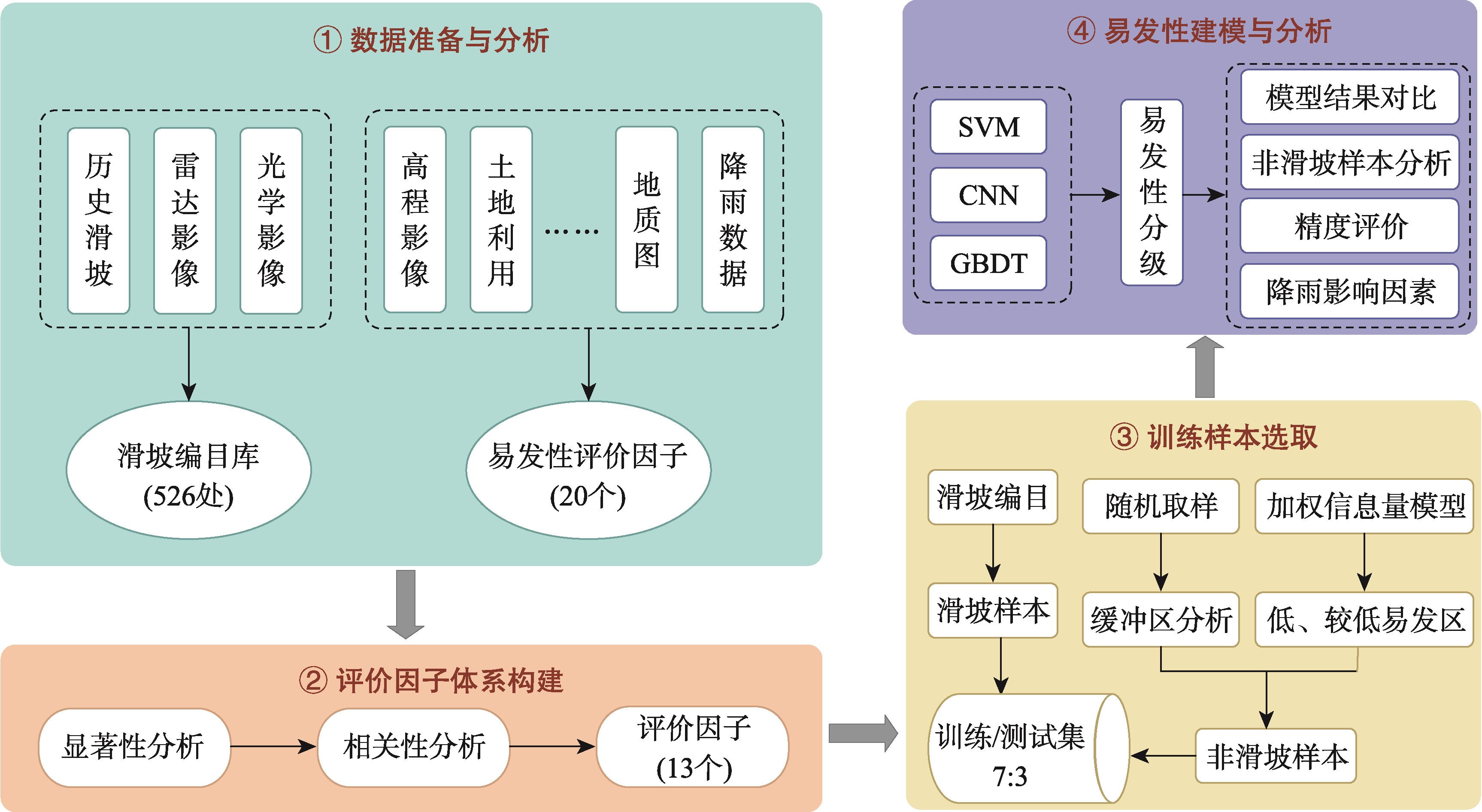
图2 研究技术路线图
本研究的总体技术路线首先收集与整理滑坡易发性分析需要的多源数据,如历史滑坡数据集、雷达影像、高程影像、地质图以及降雨数据等,并从中提取相应的滑坡空间分布信息和滑坡评价因子数据;再利用地理探测器分析与皮尔逊相关系数筛选出对滑坡易发性评价有显著影响且相关性低因子;然后基于加权信息量模型优化负样本与随机选取负样本对比,分别带入SVM、CNN、GBDT模型,进行滑坡易发性预测建模,获得滑坡易发性分级制图;最后开展结果对比与分析。
加权信息量模型
为探究非滑坡样本对易发性建模的影响,本文采用随机取样法与加权信息量模型优化法作对比分析。信息量模型是区域地质灾害评价研究中最常用的方法,利用数理统计的方法计算信息值,来衡量影响因子对地质灾害发育影响的密切程度。
信息量模型缺乏灵活性并对数据的依赖性较强,权重分配未能考虑因子的相对重要性,因此,利用层次分析法对评价指标进行定权是提高信息量模型精确度的重要途径。
机器学习模型
本研究选择了三种机器学习模型进行滑坡易发性评价:
- 支持向量机(SVM):通过寻找最优超平面,将不同类别的样本分开,在震后滑坡方面有较好的识别能力。
- 卷积神经网络(CNN):具有强大的特征提取能力,能够自动学习滑坡与影响因子之间的复杂关系。
- 梯度提升决策树(GBDT):通过集成多个决策树,逐步提高模型性能,在处理非线性关系时表现优异。
滑坡影响因子
本研究选取了13个影响因子,包括:
地形因子
- 高程
- 坡度
- 坡向
- 起伏度
- 曲率
环境因子
- 距河流距离
- 距道路距离
- 土地利用
- 植被覆盖度
气象与地质因子
- 多年年均降雨量
- 岩性
- 距断层距离
- 季节性降雨量
研究结果
1. 负样本优化效果
基于加权信息量模型优化负样本后,三种机器学习模型的评价结果均有显著提升。具体来说:
- SVM模型的滑坡密度提升了0.0103,AUC值升高了0.033
- CNN模型的滑坡密度提升了0.0639,AUC值升高了0.018
- GBDT模型的滑坡密度提升了0.0040,AUC值升高了0.008
这表明基于加权信息量模型优化负样本是合理有效的,能够显著提高滑坡易发性评价的准确性。
2. 机器学习模型比较
在三种机器学习模型中,梯度提升决策树(GBDT)模型表现最为优异,较支持向量机(SVM)模型和卷积神经网络(CNN)模型的精度分别提高了3.8%和1.7%。这表明GBDT模型更适合怒江州峡谷段地区的滑坡易发性评价。
GBDT模型在处理高维特征数据和捕捉特征间的非线性关系方面具有优势,能够更好地适应怒江州峡谷段复杂的地质环境和多样的影响因素。此外,GBDT模型对异常值不敏感,能够处理缺失值,这使其在处理实际地质数据时更具鲁棒性。
3. 降雨因子对滑坡易发性的影响
将2019—2020年的夏、冬季平均月降雨量数据引入梯度提升决策树模型后,研究发现降水对怒江州峡谷段地区的滑坡易发性具有明显影响。具体表现为:
- 夏季高、较高易发区面积明显增大,尤其是南部六库镇和上江镇地区
- 冬季高、较高易发区面积相对减小
- 降雨量的季节性变化导致滑坡易发性的空间分布也呈现出明显的季节性差异
这一结果表明,在进行滑坡易发性评价时,应充分考虑降雨因子的时空变化特征,尤其是在季风气候区,降雨的季节性变化对滑坡易发性的影响更为显著。
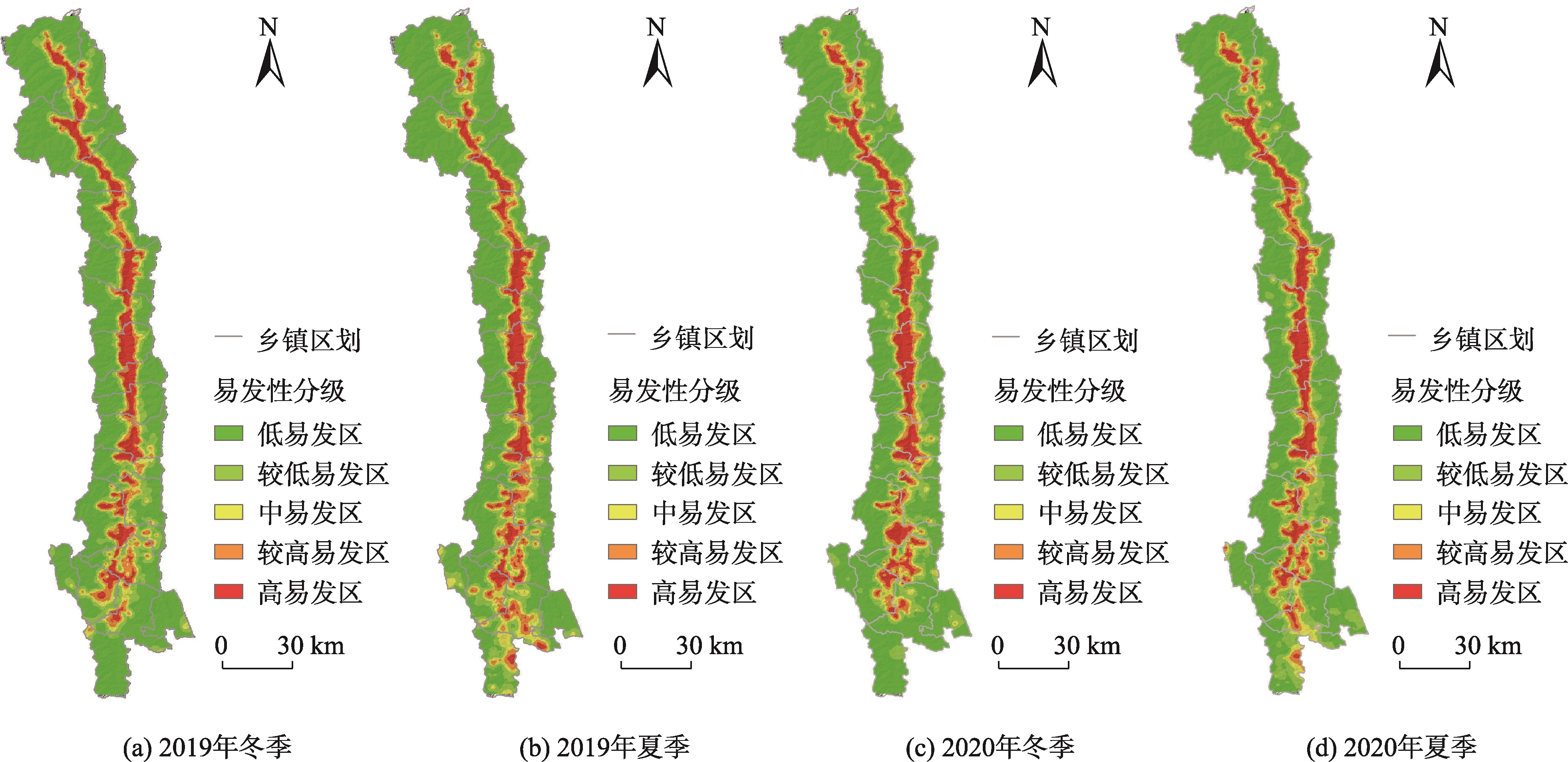
图3 2019—2020年不同降雨条件下易发性分区
关键发现
负样本优化
基于加权信息量模型优化的负样本能显著提高滑坡易发性评价精度
模型选择
GBDT模型在怒江州峡谷段滑坡易发性评价中表现最优
降雨影响
降雨的季节性变化对滑坡易发性分布有显著影响,夏季高易发区面积增大
结论与讨论
负样本优化
基于加权信息量模型优化负样本是合理有效的方法。优化后的负样本能够显著提高各机器学习模型的评价精度,表现为滑坡密度和AUC值的提升。这种方法克服了传统随机选取负样本的随机性和主观性强等缺点。
最优模型
梯度提升决策树(GBDT)模型作为滑坡易发性评价模型最适用于怒江州峡谷段地区的孕灾环境。GBDT模型能够更好地处理复杂的非线性关系,捕捉各影响因子之间的相互作用,从而提供更准确的滑坡易发性评价结果。
降雨影响
降水对怒江州峡谷段地区的滑坡易发性具有明显影响。夏季降雨量增加导致高、较高易发区面积增大,特别是在南部六库镇和上江镇地区。这表明在进行滑坡易发性评价时,应充分考虑降雨的季节性变化。
研究意义与应用价值
未来研究展望
未来研究可从以下几个方面进一步深化:(1)探索更多的负样本优化方法,提高负样本选取的科学性和代表性;(2)结合更多的机器学习模型和深度学习方法,进一步提高滑坡易发性评价的精度;(3)引入更多时间序列的降雨数据和其他动态因子,建立动态滑坡易发性评价模型;(4)将研究方法推广应用到其他地质灾害易发区,验证方法的普适性。