大模型空间认知测试框架 SRT4LLM
从空间场景中的空间对象类型、空间关系和Prompt策略三个维度构建测试体系
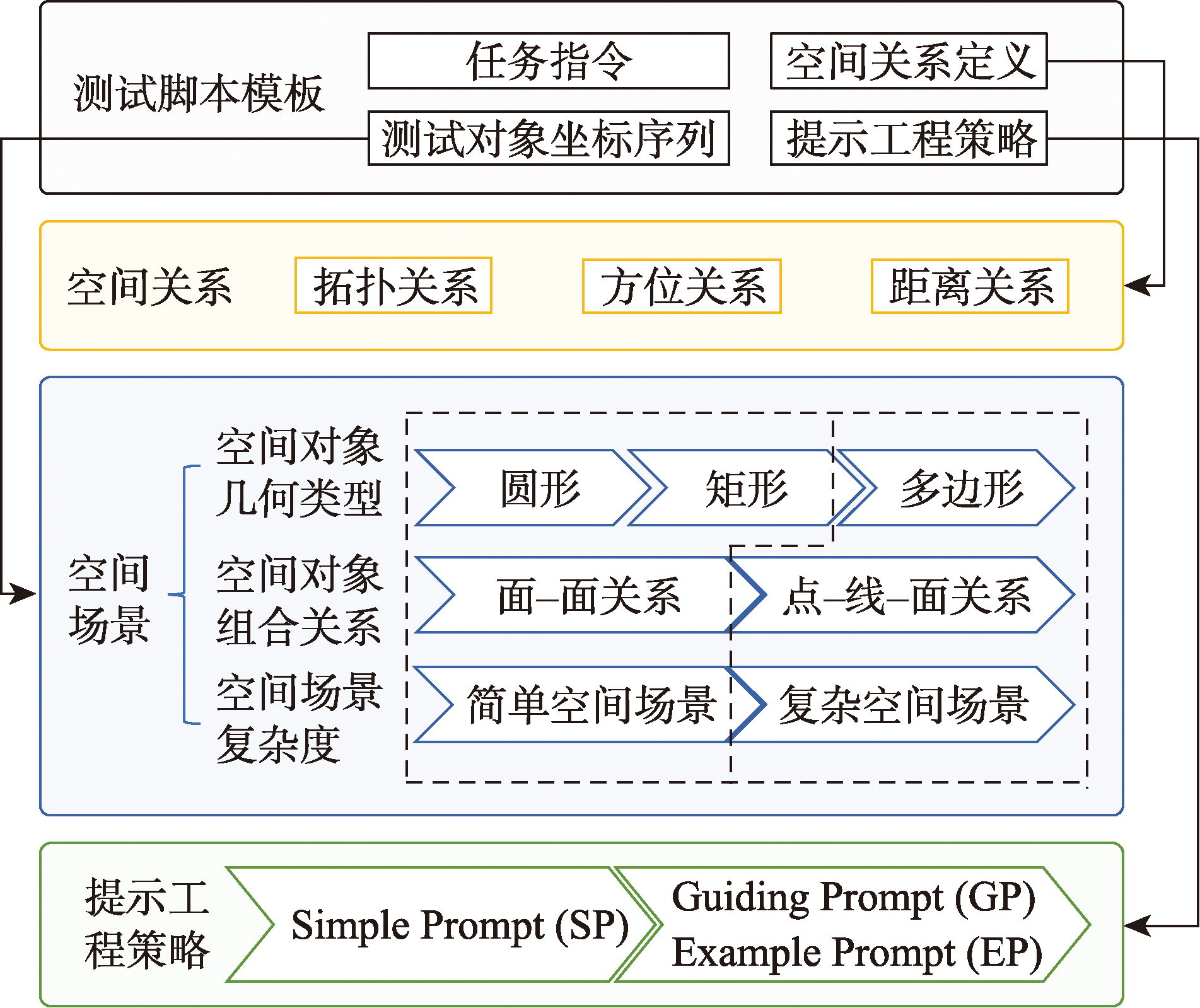
图1 SRT4LLM测试架构
空间关系
涵盖拓扑关系、方位关系和距离关系三类基本空间关系,构成所有复杂空间场景的基础。
- 拓扑关系:RCC-8模型(离散、外接、部分重叠等)
- 方位关系:基于投影的9方位系统(上、下、左、右等)
- 距离关系:单调递增的距离范围划分(近、中、远)
空间场景
包括空间对象的输入方式、空间对象类型的组合方式和空间场景复杂度三个维度,遵循从简单到复杂的设计原则。
- 空间对象几何类型:圆形、矩形和多边形
- 空间关系:面-面关系和点-线-面关系
- 场景布局:垂直、水平和对角线三种布局
提示工程策略
采用三种复杂度渐进的方法,充分挖掘不同大模型的空间认知能力,评估其在不同提示策略下的表现。
- 简单提示(Simple Prompt, SP)
- 引导提示(Guiding Prompt, GP)
- 示例提示(Example Prompt, EP)
提示工程策略与测试流程
设计三种提示工程策略和标准化测试流程,评估大语言模型的空间认知能力
简单提示 (SP)
作为基础的测试,在无额外引导的情况下,主要衡量大模型预训练语料库中空间关系的存量及对空间关系的默认推理能力。
引导提示 (GP)
基于思维链(Chain of Thought, CoT)技术,通过要求大模型在输出最终答案之前,显式输出逐步的推理步骤来增强大模型的推理。简化了思维链的复杂推理过程,针对空间问题加入关键推理要点。
示例提示 (EP)
在SP的基础上引入Few-shot策略,每次测试前提供2个推理示例,以指导大模型生成更优输出。该策略能够强化大模型对空间关系的理解,并减少错误分类。
标准思维链设计

图2 标准思维链prompt模板
测试流程
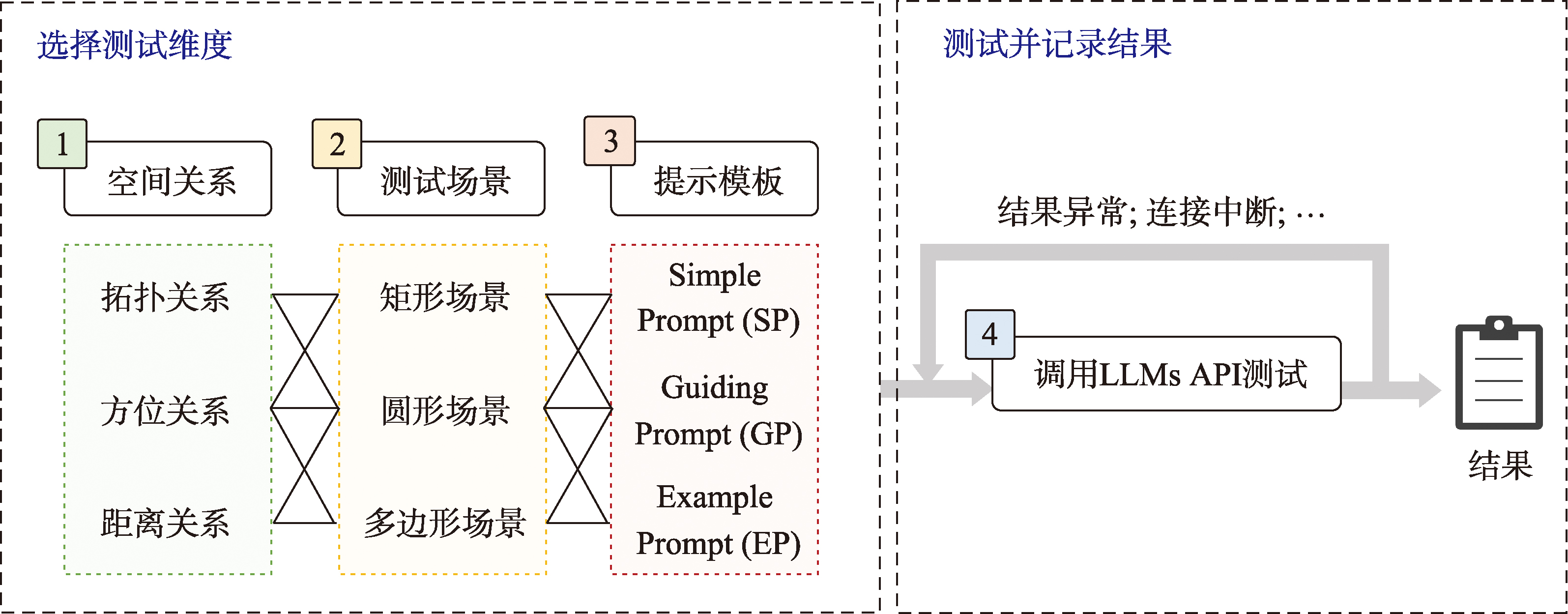
图3 SRT4LLM测试流程
SRT4LLM采用3类Prompt工程策略(SP、GP、EP),针对3类空间对象(圆形、矩形、多边形)进行测试。每类空间对象包含24组场景,对一种空间关系进行24×3×3=216次测试,3种空间关系共进行648次提问。测试在8个大模型上分别调用API自动化执行,若测试过程中出现异常结果或因连接问题导致中断,则重启测试流程,确保数据完整性。最终,测试结果由人工统计正确分类的场景数,并计算正确率。
测试大模型
表1 测试大模型
| 大模型名称及版本 | 发布机构 | 发布时间 | 测试版本号 |
|---|---|---|---|
| ChatGLM3 | 智谱AI | 2023年10月27日 | ChatGLM3-6B |
| ERNIE Bot | 百度 | 2023年3月16日 | ERNIE-Bot-turbo-0922 |
| Gemini | 2023年12月6日 | gemini-pro | |
| GPT-3.5 | OpenAI | 2022年11月30日 | gpt-3.5-turbo |
| GPT-4 | OpenAI | 2023年3月15日 | gpt-4-0125-preview |
| LLaMa2 | Meta AI | 2023年7月19日 | LLaMa2-13B-chat |
| QWEN | 阿里云 | 2023年3月16日 | qwen-max |
| SparkDesk | 科大讯飞 | 2023年5月6日 | sparkv3.5 |
实验结果分析
分析空间场景对象几何形状、提示工程策略对大模型空间认知能力的影响
空间场景对象几何形状影响分析
实验设计涉及不同复杂度的几何场景,包括圆形、矩形和多边形,以逐步增加推理难度。测评结果显示,8个大模型在圆形、矩形和多边形空间场景的3种空间关系判断准确率分别为35.8%、38.8%、53.0%,28.6%、39.7%、51.4%,以及32.6%、37.2%、46.5%。
整体而言,大模型在不同几何场景的表现未出现显著下降,体现了较强的适应性。从8个大模型的测试结果看,除个别大模型在3类空间对象上的准确率有明显波动外,大部分大模型在不同空间对象类型中回答准确率相对稳定,表现出较高的一致性,进一步验证了SRT4LLM能够有效运用于各类空间场景。
提示工程影响分析
本研究采用3种提示工程策略:SP、GP和EP,为大模型提供不同程度的提示信息。测评结果表明,使用SP、GP和EP提示策略时,大模型在3类空间关系判断任务上的平均准确率分别为29.6%、32.3%、35.4%,31.0%、35.8%、47.4%以及44.3%、46.6%、57.3%。
从8个大模型的评估结果看,提示工程对大模型空间认知能力的表现有显著影响。随着提示的复杂性逐步增加,大部分大模型的准确率呈现上升趋势。这一结果表明,恰当的提示工程能够提升大模型的空间认知表现。同时,SRT4LLM能够有效挖掘大模型的空间认知潜力。