1 引言
地图综合是对空间数据进行抽象和概括表达的技术和科学。道路网作为社会经济发展和人类活动交流的重要载体,一直备受制图者和使用者的高度关注。随着城市化进程的加快,城市空间信息也发生了更加频繁的变化。这不仅要求城市道路网实时更新,也给道路网自动综合带来了新挑战。道路网自动综合通常包括选取和化简2个关键步骤。在城市环境中,为确保综合后道路网位置的精确性,道路网综合主要体现在其选取上。
道路网选取是指在一定的地图尺度下保留重要道路并删除次要的道路的过程,因此如何衡量道路的重要性成为了道路网选取任务的重中之重。为此,学者们提出了许多特征指标去衡量道路的重要性。早期的研究主要依赖于道路的基本属性,如道路等级、道路宽度、铺面材质以及车道数等。然而,这种方法仅适用于具备完整语义信息的道路网络,同时也忽视了整体道路之间的连通关系。
为克服早期方法的不足,研究人员开始引入道路的几何和拓扑特征。几何特征减少了对语义信息的依赖,而拓扑结构则保证了选取后道路网络的连通性。道路的几何特征包括"长度"、"蜿蜒度"、"路段密度",其中长度和密度通常是主要考虑的几何特征。在拓扑特征中,由于传统道路之间的拓扑关系,例如:相交、相离、相邻等难以量化。近年来的研究通常将路网抽象为复杂网络,借助图论中的指标,如"度"、"接近中心性"以及"中介中心性"等来评估道路的拓扑重要性。
随着位置服务的发展和智能终端的普及,地理大数据也为道路特征提供了新的数据源。交通流量数据和POI(Point of Interest)数据成为道路选取的重要特征项。高密度POI的区域对应人口和交通活动集中区,将其引入选取模型可以更好地揭示城市活动的空间格局。与静态POI相比,交通流量数据不仅能反映城市活动格局,还可以反映道路的实时通行状况,从而动态评估道路网的重要性。
尽管引入更多特征项可以使问题分析更加全面,但高维度特征也增加了模型计算复杂度和数据预处理的负担。现有研究中,不同研究者选择的特征各异,特征的选取往往依赖于主观判断,从而增加了道路网选取的不确定性。
在上述特征项的基础上,道路网选取通常被视为多属性决策问题,即需要对特征项进行赋权并对道路重要性排序。对此,学界提出了多种方案,其中包括准则CRITIC法(Criteria Importance Through Intercriteria Correlation)、熵值法(Entropy Weight Method, EWM)、变异系数法(Coefficient of Variation, CV)的客观赋权方式,以及德尔菲法(又称专家赋权法)层次分析法(Analytic Hierarchy Process, AHP)的主观赋权方式。这些方法从不同角度综合评估道路特征的重要性。然而,其中方法大多依赖专家的经验或特定数据集合,影响了选取的自动化程度。
另一种选取方案是将特征输入机器学习模型进行训练,这种方法避免了赋权问题,但机器学习模型的"黑箱"特性使其可解释性较低,难以深入理解模型决策的依据。基于上述问题,在道路网选取中,特征重要性的定量分析以及对机器学习模型的可解释性是一个值得深入探讨的研究内容。
在机器学习方法中,监督式学习是通过利用带有人工标签的训练数据,使模型学习输入与输出之间的关系,以进行准确预测。如果能对监督式学习进行特征可解释性分析,就能量化人在道路网选取过程中的决策机制,从而解决上述存在的问题。在近期研究中,SHAP作为一种通用的机器学习可解释性框架,逐渐受到研究者的关注。近年来,该方法已在多个方面的地理空间数据模型中证明了其可靠性,如城市气候、出行行为、灾害敏感性以及热死亡率等。因此,本文首次将SHAP框架应用于道路网选取任务中,通过对特征贡献的量化分析,揭示人在道路网选取中的决策机制,并为特征选择和特征赋权这一长期难题提供参考依据。
2 研究方案
本文首先需要将构建好的数据集分别输入到模型和SHAP框架中。经过参数设定后,模型进行训练并输出结果,随后将训练后的结果输入到SHAP框架进行特征分析。
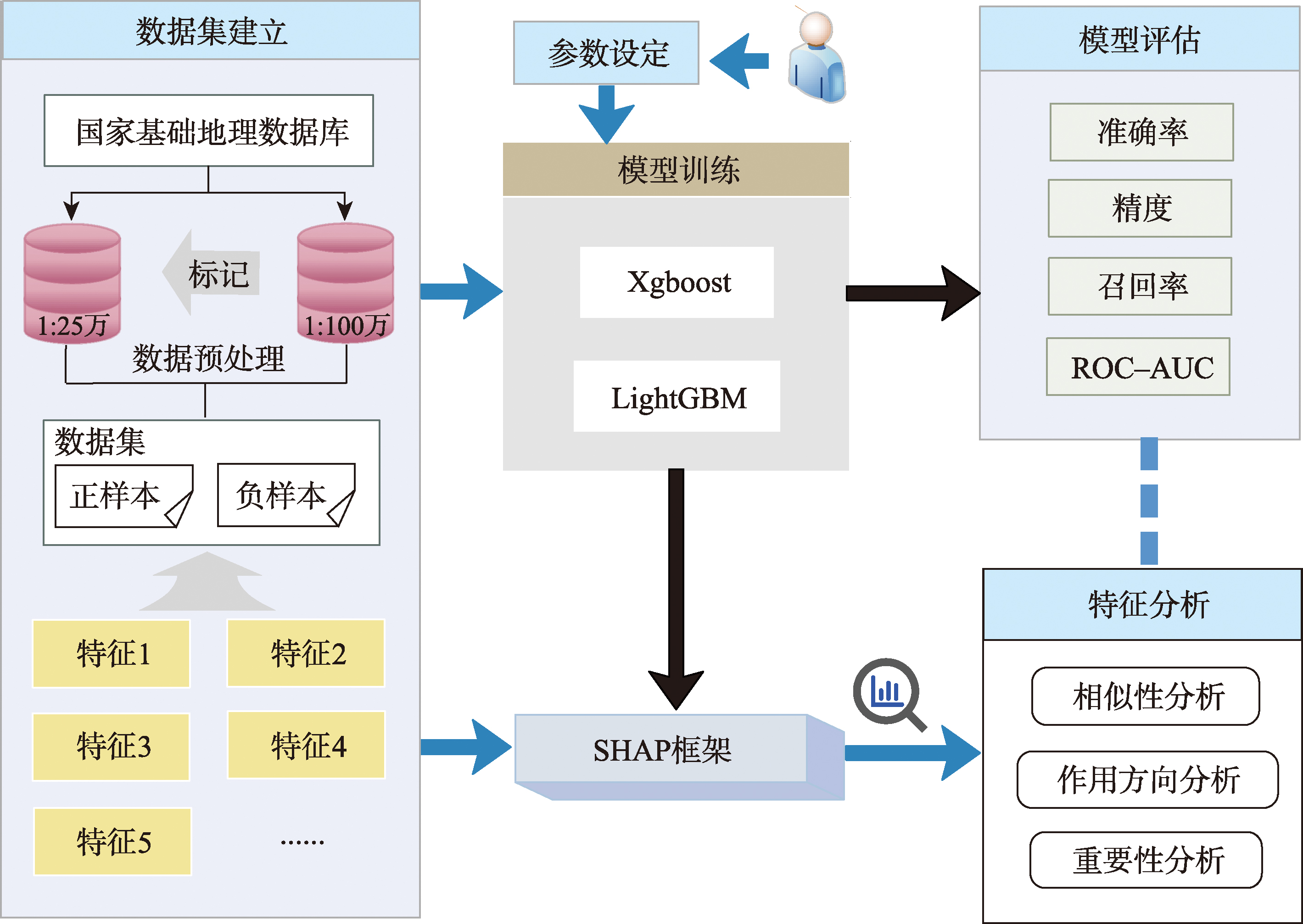
图1 总体研究框架
(1)数据集建立。本文利用国家基础地理数据库中的1:25万矢量道路网数据作为原始数据,1:100万矢量数据作为正例数据,进而将数据划分为正样本和负样本。然后将本文的待评估特征项进行计算,最终完成数据集的建立。
(2)模型选择与评估。本文选择了XGBoost和LightGBM 2个机器学习模型对数据集进行训练,通过参数设定使模型达到收敛。对模型结果进行评价,评价指标包括:准确率、精度、召回率、ROC(Receiver Operating Characteristic)-AUC(Area Under the Curve)值。
(3)SHAP与特征分析。SHAP框架是一种事后解释模型,通过输入样本特征和模型预测结果,解释每个特征对预测的贡献。本文特征分析主要包括特征相似性分析、特征作用方向分析以及特征重要性分析3个维度。
2.1 数据集建立
本文对2004—2024年中道路网选取领域的研究进行了系统梳理,重点分析了31篇发表在核心期刊上的文献中所提及的道路网特征项,相关文献通过CSCD、SCI、EI和SSCI数据库进行检索,检索关键词包括"road network selection"(道路网选取)和"road network generalization"(道路网综合)。
表1 统计中涉及的期刊
| 序号 | 文章数/篇 | 期刊名称 |
|---|---|---|
| 1 | 6 | 测绘学报 |
| 2 | 5 | 武汉大学学报(信息科学版) |
| 3 | 4 | International Journal of Geographical Information Science |
| 4 | 3 | 地球信息科学学报 |
| 5 | 3 | ISPRS International Journal of Geo-Information |
| 6 | 2 | Cartography and Geographic Information Science |
| 7 | 2 | Transactions in GIS |
| 8 | 2 | 测绘科学 |
| 9 | 1 | GeoInformatica |
| 10 | 1 | Computers, Environment and Urban Systems |
| 11 | 1 | International Journal of Applied Earth Observation and Geoinformation |
| 12 | 1 | 地理与地理信息科学 |
2.2 模型选择与评估
在使用机器学习模型解决道路网选取问题时,通常可将其转化为选取与未选取的二分类任务。本文数据选取的尺度跨度较大,导致选取的道路与未选取的道路之间存在明显的不平衡。传统机器学习模型通常依赖均衡的样本分布,难以准确捕捉少数类特征。而XGBoost和LightGBM模型通过内置的不平衡处理机制,能够更关注少数类样本,从而有效缓解这一问题。为探讨不同模型对特征重要性产生的影响,本文采用XGBoost和LightGBM模型进行对比分析。
结合SHAP框架,本文通过3个维度对特征进行分析。
特征相似性:本文采用皮尔森相关系数方法来计算不同特征之间的线性相关程度。通过计算特征值之间的皮尔森相关系数,可以得到一组衡量特征间相似性的数据,通常将其以热力图的方式展示。该方式可以帮助识别特征之间的冗余性,从而避免选择高度相关的特征。
特征作用方向:SHAP值能够揭示每个特征是如何影响模型输出的,即特征值的变化是促使预测结果向正方向(选取)还是负方向(未选取)变化。每个特征的SHAP值反映了该特征对模型预测结果的边际贡献,并且能够表明该贡献是正向的还是负向的。通过对特征作用方向进行可视化,可以清晰地反应某些特征如何推动模型预测该道路是否选取。
特征作用重要性:在机器学习等非线性的模型中,特征的重要性通常通过计算所有样本中某个特征的SHAP值的平均绝对值来量化。平均绝对值越高,说明该特征在模型决策中越重要。在多属性决策等线性的道路网选取模型中,评估特征的重要性则不仅仅依赖于特征的绝对贡献,还需要综合考虑特征作用的方向性,即特征值的增大是否导致选取的贡献度增加。因此本文将特征的特征值与其SHAP值的相似性作为衡量线性模型特征重要性的标准。
3 实验设计及结果分析
3.1 数据预处理
针对上述1:25万和1:100万的所有基础地理数据,实验采用构建道路stroke方法进行处理。在1:25万的道路网中,共生成了4299条stroke,每条stroke可视为一个训练样本。同时,在1:100万的道路网中,共筛选出653条作为正样本,其余未被选中的道路则视为负样本。
实验按照前述方法对基础地理信息进行特征计算,"周边POI数量"和"交通流量"2个特征的计算均需结合多源数据。在计算"周边POI数量"时,本文参考各城市的平均道路红线距离,将以道路为中心30m缓冲区范围内的POI作为实验对象,认为这些POI能显著影响道路网的重要性。对于"交通流量"特征,由于测量数据可能存在一定偏差,一些出租车轨迹点分布在道路周围。因此,需将这些轨迹点投影到最近的路段上。此外,不同数据集中出租车数量和轨迹时间覆盖范围存在差异。为了准确反映不同道路stroke之间交通流量的相对大小,本文对各地区的出租车轨迹数据进行标准化处理,并将处理后的数据整合成一个综合数据集。
最后,为避免不同特征量纲差异对模型的影响,实验中对所有特征的计算结果进行了归一化处理,以确保模型训练数据的一致性。
3.2 模型训练与评估
实验采用XGBoost和LightGBM模型进行对比分析。在模型的超参数设定中,2种模型的学习率设定为0.05,L1正则化系数为3,正样本权重为2,特征采样比例为1。共同参数的统一设定,可以进一步了解模型本身在道路选取任务中的差异性。实验选择80%的数据作为训练集进行训练,最终得到的损失曲线如图4所示。
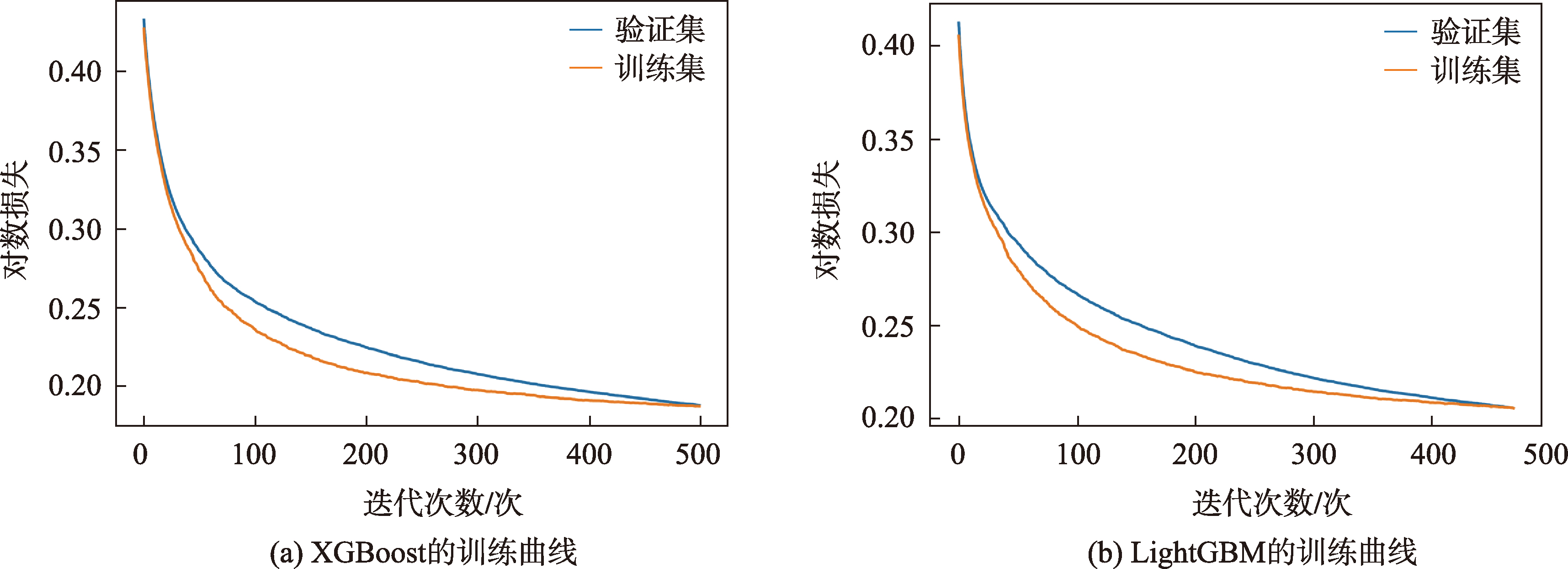
图2 2个模型的训练损失曲线对比
3.3 实验结果验证
为了直观验证本文的权重结果,实验采用多属性赋权方法对道路网进行选取,并将选取结果与国家基础地理数据库中的1:100万标准数据进行对比验证。具体流程为:首先,对各个标准化特征进行加权计算,得到每条道路要素的重要性值。随后,根据标准数据中的要素数量,选取重要性值排名靠前的道路要素。实验分别从4种典型道路网结构中选择了一个代表城市(北京、武汉、南京和成都)的道路网进行可视化展示,图11中左图为实验得到的结果,右图为数据库中的矢量数据。
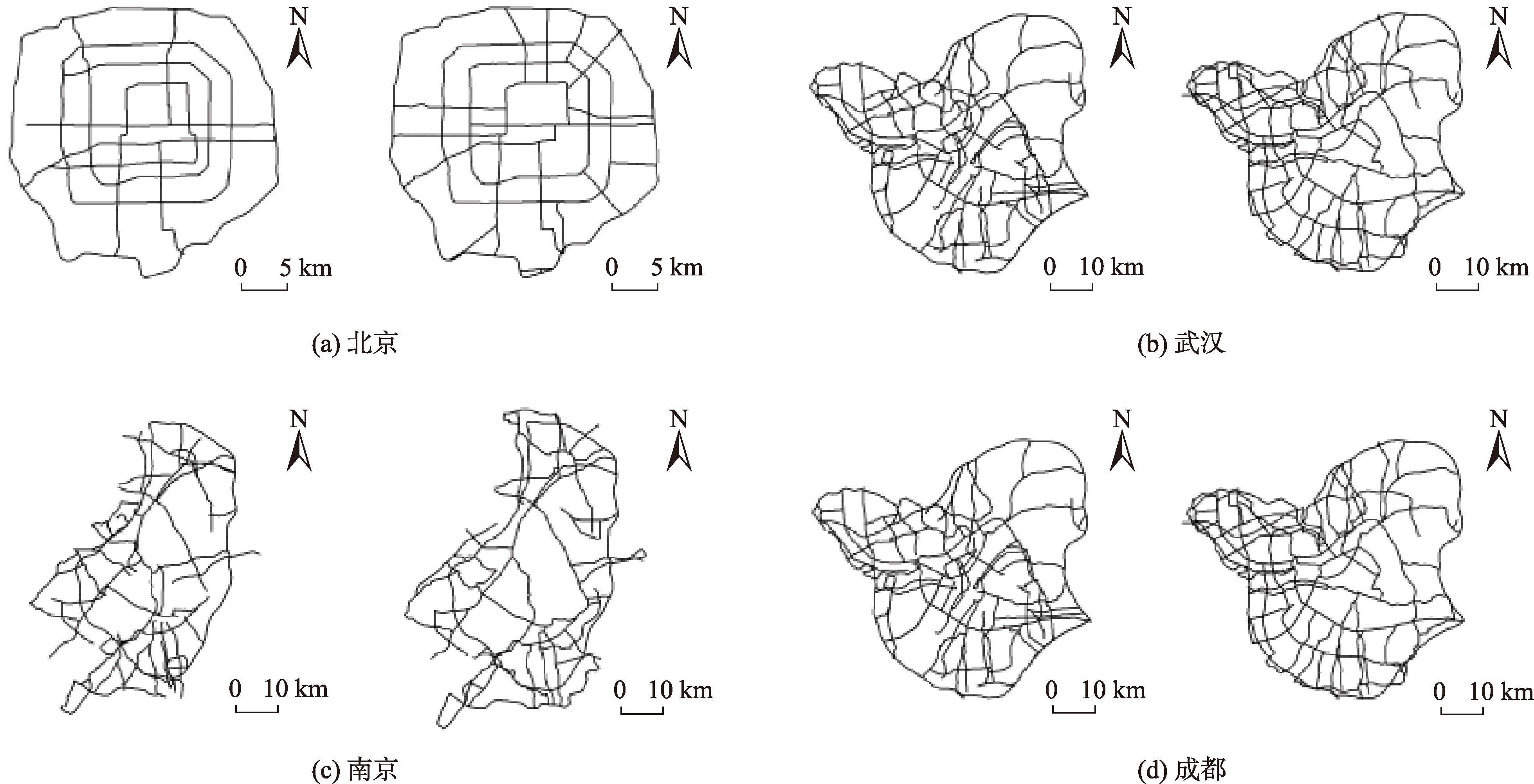
图3 本文选取结果与标准数据的对比
通过观察图11的对比结果可知,本研究提出的方法在城市中心区域显示出较高的道路选取密度。这一现象可能源于本文方法中包含了"交通流量"和"周边POI数量"2项特征,这两项特征在城市核心区域普遍呈现较高数值特征。相较于标准制图数据库中的选取结果,人工制图中通常未将上述动态特征纳入道路选取。在整体结构层面,研究结果与标准数据集表现出较高一致性,有效保持了原始道路网的结构特征。由此证明,在由1:25万到1:100万的道路网选取下,本文得到的特征权重结果具有一定的参考价值。
4 结论与展望
本文将SHAP可解释性框架引入道路网选取任务中的特征分析中,探讨了不同特征在道路网选取过程中的作用方向与重要性,为道路网选取中的核心问题—特征选择和特征赋权,提供了一种新的解决思路。研究从特征相似性、作用方向和特征重要性3个方面,系统分析了特征对模型预测结果的贡献,进而揭示了不同特征在道路网选取中的具体作用。
本研究采用了来自1:25万和1:100万2个比例尺的道路网数据进行分析,涵盖了多个城市的代表性道路网。实验结果表明,在特征相似性方面,拓扑特征之间具有较强的相似性,相关系数大多高于0.6,而"周边POI数量"与其他特征的相似性较弱,相关系数大多低于0.4;在特征作用方向方面,"周边POI数量"和"交通流量"的特征作用方向较为不稳定,而其他特征的高值通常对模型有正向贡献;在特征重要性方面,"等级"是非线性模型中最为关键的特征,其次为"长度"和"交通流量"。在线性模型中,"等级"依然是最重要的特征,其重要性为0.9137,而"度"、"中介中心性"和"接近中心性"的重要性显著上升,其重要分别为0.7809,0.7316以及0.6145。研究进一步基于计算得到的权重对道路网进行选取,并通过与基础地理数据库中的标准结果进行对比验证。结果表明,选取结果与标准数据集高度一致,充分证明了权重的可靠性。
本文采用的训练数据来源于目前公开的矢量地形图数据库,因此,研究得出的结论更适用于地形图中的城市道路网选取。然而本文研究依旧存在一定的局限性,其局限性主要体现在数据获取上。一方面,出租车轨迹数据仅覆盖10个地区,导致实验样本只能利用该10个地区的道路数据。另一方面,由于现有大规模的道路网矢量数据仅公开了1:25万和1:100万2个比例尺,研究的结论可能受限于这2个比例尺下,不一定会适用于在其他比例尺下的选取。未来,可以通过获取更多地区以及更多比例尺的数据来进一步验证和扩展当前结论的普适性。