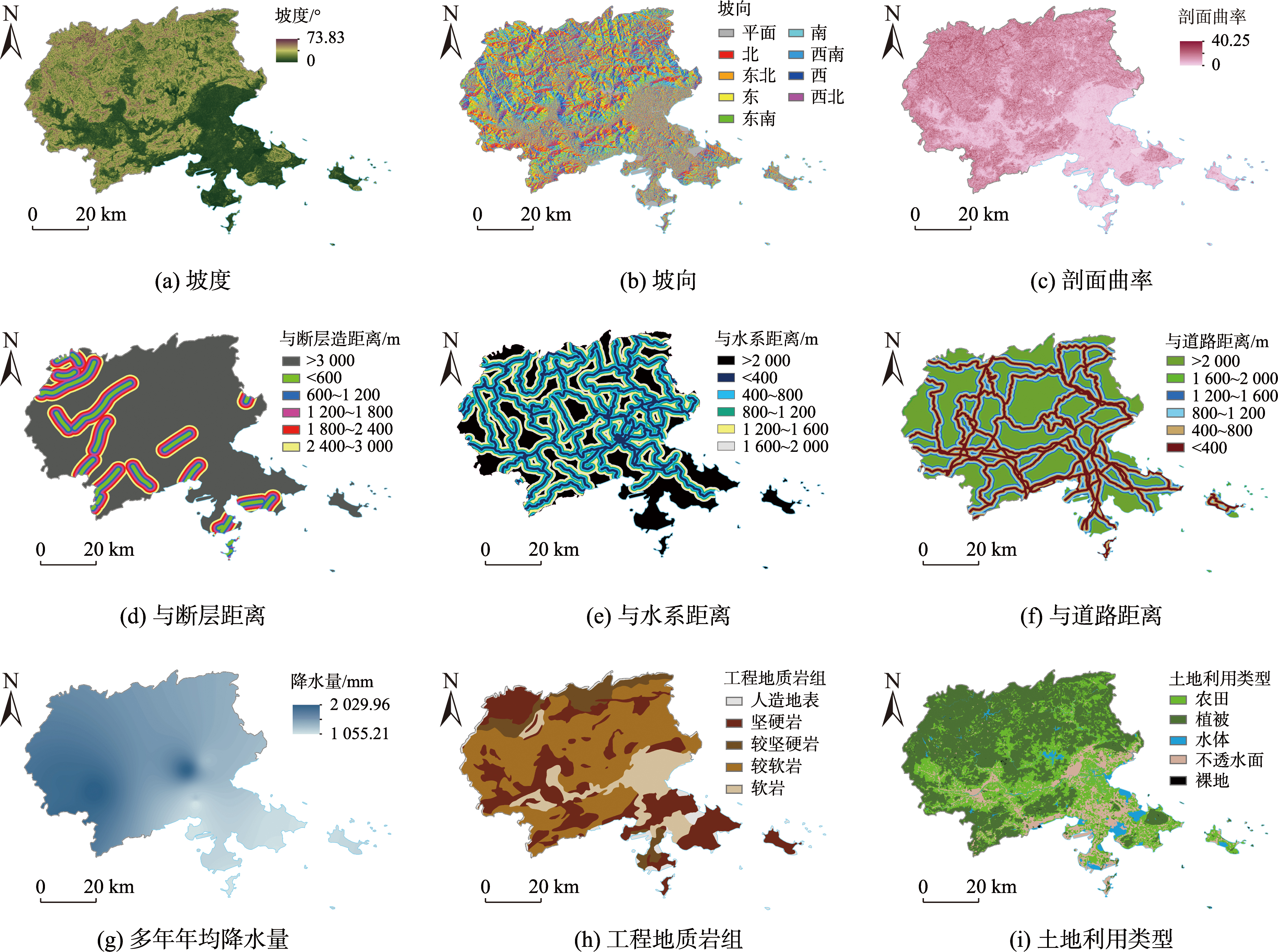
2 研究思路与方法
训练样本采样优化与机器学习结合的滑坡易发性评价方法主要包括滑评价因子的筛选、采样优化样本数据集构建、基于机器学习的滑坡易发性评价模型构建3个部分。

图1 训练样本采样优化与机器学习结合的滑坡易发性评价技术路线
2.1 滑坡评价因子筛选
为提高模型预测的准确性,需要对评价影响因子同时进行相关性与共线性分析,并根据分析结果进行因子筛选,以保证评价因子的相互独立性。采用皮尔逊相关系数衡量因子之间的相关程度,当相关系数绝对值高于 0.4 时,认为因子间存在较高相关性,应予以剔除。共线性分析中,当 TOL 小于 0.10、VIF大于10时认为该因子共线性严重,应予以剔除。
2.2 采样优化训练样本数据集构建
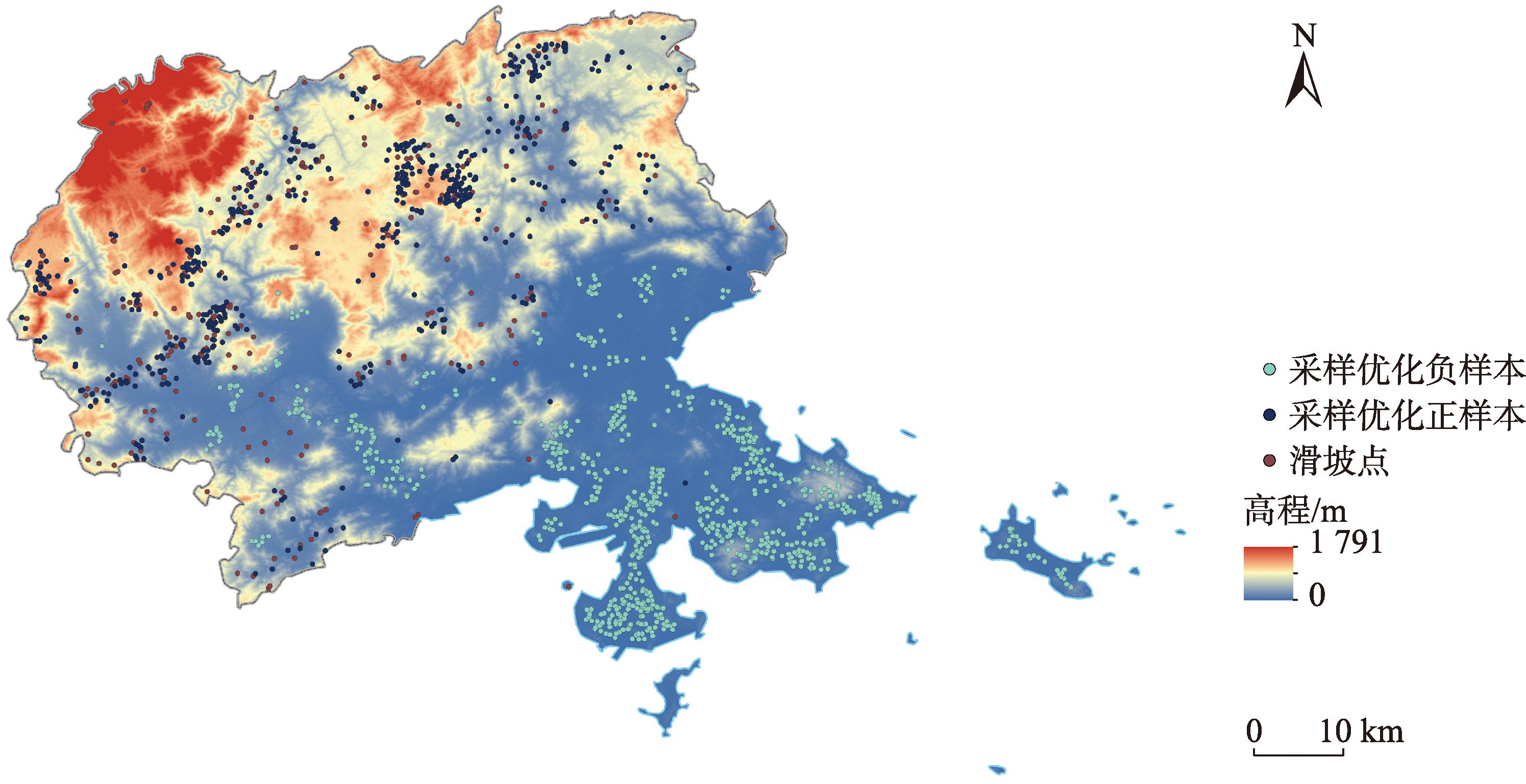
包括两个关键步骤:滑坡正样本数据筛选扩充和滑坡负样本数据客观提取。通过滑坡正样本原型采样方法(PBS)对正样本进行数据扩充,筛选捕捉滑坡发生的关键影响因素,获取更客观、更具代表性的正样本数据集;采用无监督聚类模型对负样本进行客观提取,在保留重要数据空间分布特征的同时降低引入噪声的干扰性,提高负样本数据集的质量。
2.2.1 滑坡正样本数据筛选扩充
筛选扩充滑坡正样本数据可以确保模型能够训练学习更多的滑坡特征信息。采用滑坡正样本原型采样方法(PBS),以滑坡空间分布点数据构建半径为1 km范围的缓冲区作为滑坡多边形,通过频率采集方法在滑坡多边形内提取滑坡正样本原型数据,构建滑坡正样本原型数据集,量化滑坡多边形内的样本数据与滑坡灾害之间的关系,捕捉滑坡发生的关键影响因素。
正样本原型数据集构建流程:
- 对滑坡多边形的每一个评价因子构建评价因子频率直方图
- 将评价因子值位于最大频率区间的像元点作为正样本原型
- 进行地理环境相似度计算
- 根据可信度阈值进行采样,保证正样本数据的客观性与可靠性
组距的建立采用如下经验公式:
bine = 2 × IQRe × n-1/3
式中:bine是评价因子 e 的直方图组距;n 和 IQRe分别是评价因子e的点位数量和四分差。
对各评价因子按照所属数据类型分别进行地理环境相似度计算,分别采用频率比和核密度函数计算离散型和连续型评价因子与滑坡正样本原型数据发生频率之间的函数关系;对各评价因子相似度栅格数据进行计算,获得栅格数据与正样本原型数据的综合评价因子相似度。
2.2.2 滑坡负样本数据客观提取
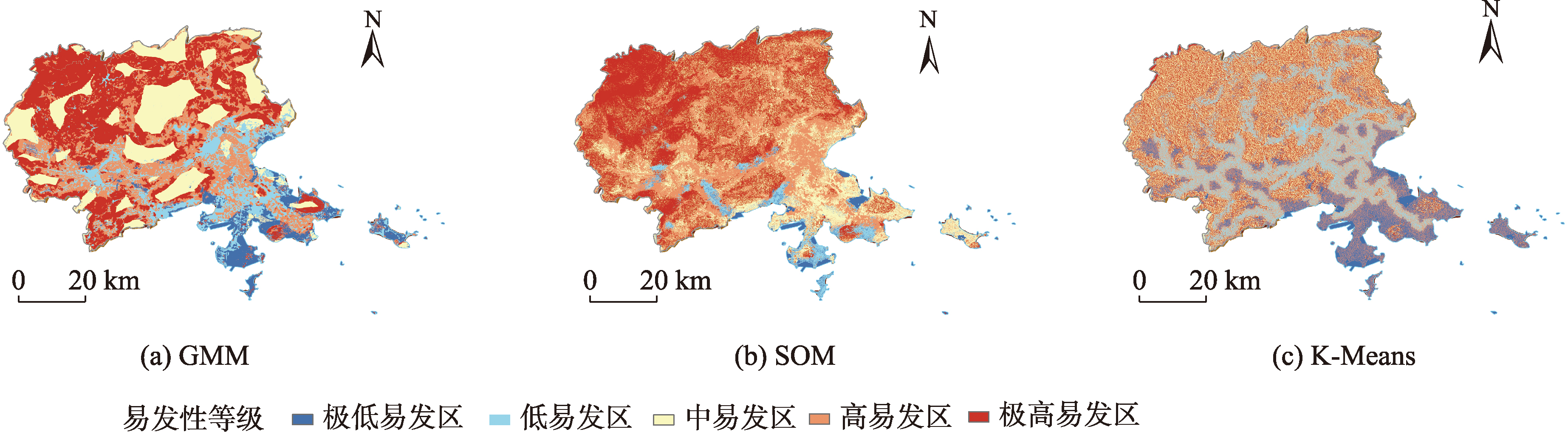
本研究采用无监督聚类效果较好的 K-Means聚类、高斯混合模型与自组织神经网络对滑坡负样本数据进行客观优化提取。通过无监督聚类模型对负样本进行提取,能够得到若干组聚类簇,既反映负样本数据的集中分布情况,又保留滑坡负样本数据的空间分布特征。这种客观提取方法避免了数据欠采样导致的信息丢失,同时在聚类过程中考虑了数据之间的相似性,避免了过采样引入的噪声干扰问题,提高负样本数据集的可信度与客观性。
K-Means聚类
K-Means 聚类是一种结合了聚类和欠采样的机器学习基本算法,在没有先验数据的情况下对原始数据进行预分类,并在完成后验信息后对分类结果进行验证,可以一定程度上克服简单欠采样和过采样的缺点。
高斯混合模型
该方法是一种引入了基于 K-Means 聚类的概率模型,选择具有最高概率值的标签类作为聚类的最终结果。在高斯混合聚类模型(GMM)中,每个高斯模型代表一个类,最终训练的概率是几个高斯模型的加权和。
自组织神经网络
自组织神经网络(SOM)模型是一种无导师、无监督、自组织的学习过程,SOM 的层次结构由输入层和竞争层组成。输入层接收输入样本信息并逐渐将其传递到竞争层,由竞争层对接收到的输入样本信息进行各种比较分析。
2.3 基于机器学习的滑坡易发性评价模型构建
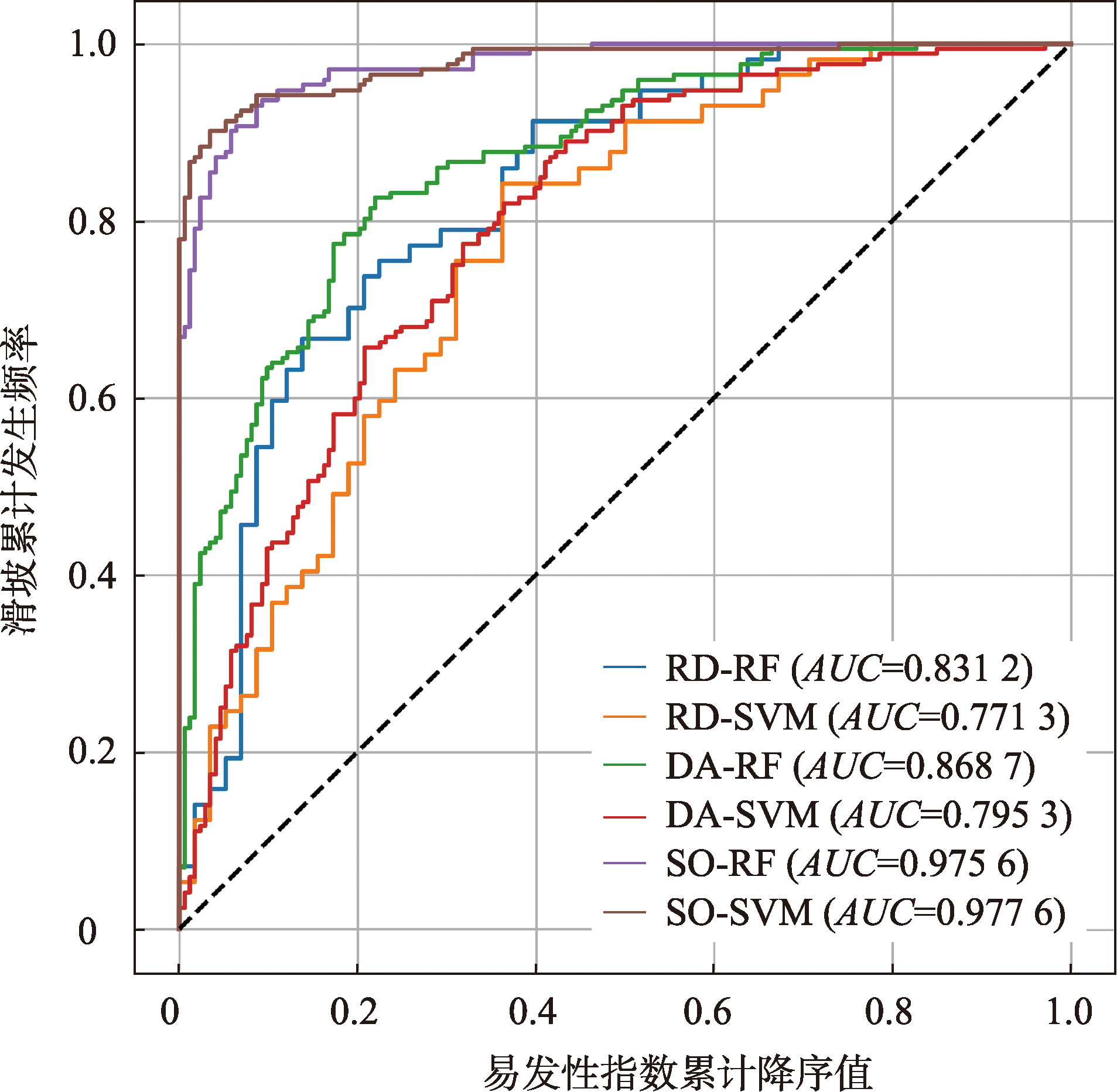
基于筛选后的评价因子组合,结合已知滑坡原始数据集及采样优化的训练样本数据集构成机器学习训练数据集,构建随机森林模型与支持向量机模型,利用网格搜索进行超参数调优,计算区域滑坡易发性指数,再通过ROC曲线对模型预测结果进行精度验证。最后,基于易发性预测结果进行滑坡危险性空间分布特征及其规律分析。
2.3.1 随机森林
随机森林(RF)是 bagging 算法的代表,由 Breiman于 2001年首次提出。它由多个决策树组成,在构建决策树时,对训练数据进行有放回的随机采样(一般选取总样本的 2/3),同时随机选取部分特征进行模型训练。其中,每次未被抽取的剩下 1/3 样本称为袋外数据(Out Of Bag,OOB),其误差可以用来验证模型的拟合性能。
P* ≤ ρ(1 - s²)/s²
式中:ρ为决策树之间的相关度平均值;s为决策树的平均强度。
2.3.2 支持向量机
支持向量机是一种建立在结构风险最小化和 VC 维理论基础之上的经典机器学习算法,对解决滑坡危险性评估存在非线性高维模式识别问题具备独特优势,比其他传统方法具有更好的评估能力与推广能力。
wx + b = 0
式中:w 表示法向量;x 表示超平面上的点;b 表示常数。当 w 和 b 达到最优时,所找到的最优超平面将使得正样本与负样本之间的距离最大。