VoxTNT架构设计
双重Transformer架构的创新融合
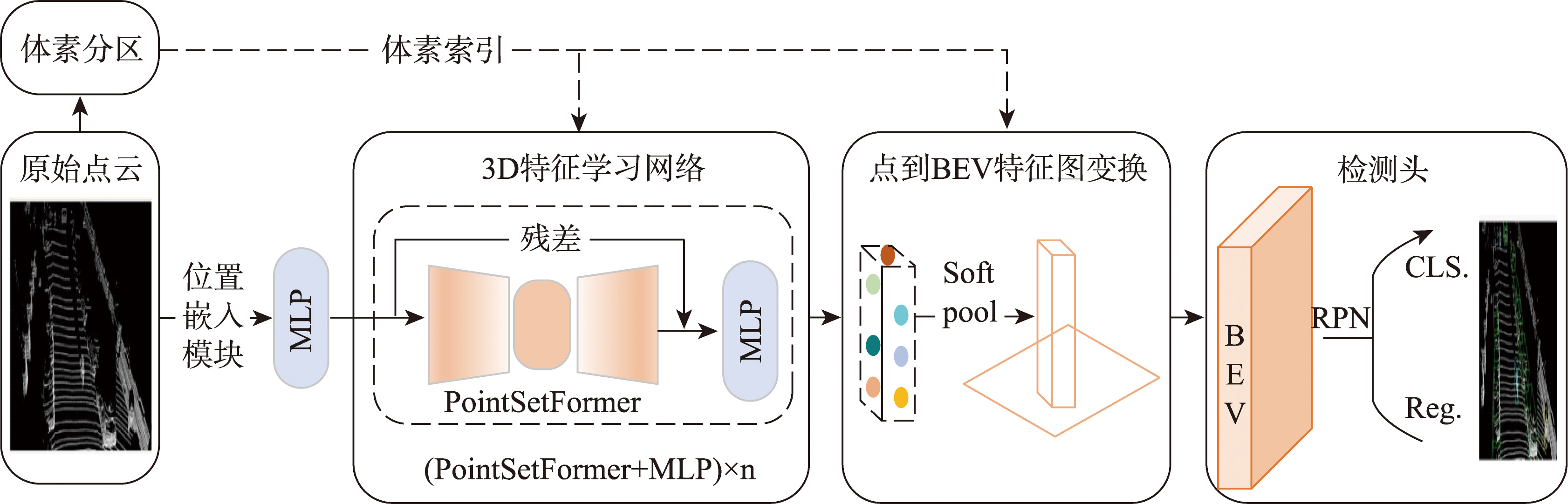
图1 VoxTNT总体框架
体素分区
- 将原始3D点云空间划分为规则体素网格
- 在每个体素网格内采样T个关键点
- 大幅减少点云数量,节省计算开销
PointSetFormer
- 引入诱导集注意力模块(ISAB)
- 通过约简交叉注意力聚合细粒度几何特征
- 突破传统体素均值池化的信息损失瓶颈
VoxelFormerFFN
- 将非空体素抽象为超点集
- 实施跨体素ISAB交互
- 建立长程上下文依赖关系
计算优化
- 全局特征学习从O(N²)压缩至O(M²)
- M<
- 规避复杂Transformer的高计算复杂度