研究背景与意义
研究挑战
- 现有监督学习方法需要大量标注样本
- 建筑物形状存在人为设计的多样性
- 遥感数据处理中的误差和不规则性
解决方案
- 融合对比学习的自监督特征提取
- 结合迁移学习的监督分类技术
- 显著减少标注数据依赖
CLTM模型架构
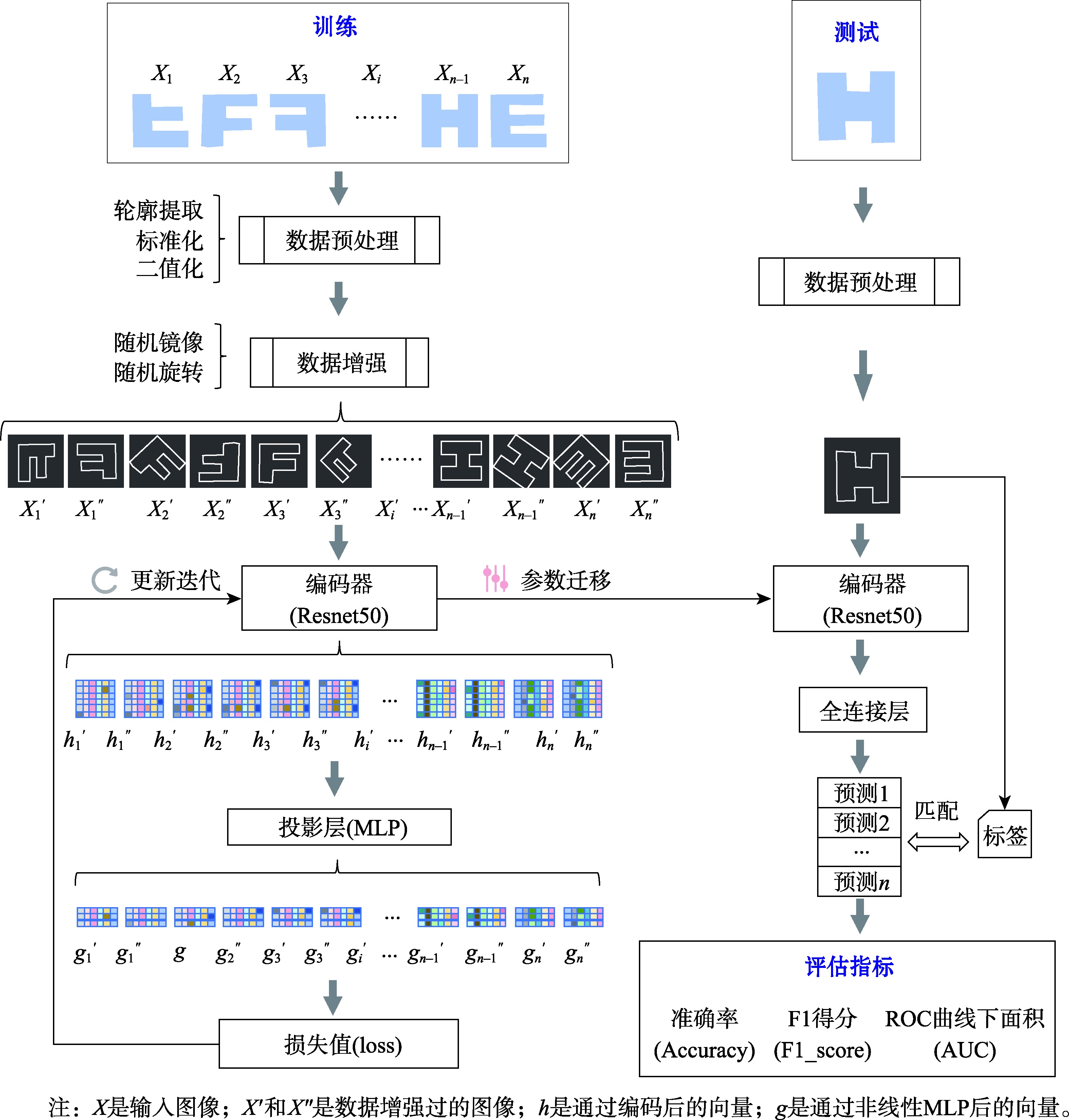
图1 基于对比迁移模型的建筑物形状识别框架
自监督训练阶段
- • 轮廓提取与二值化处理
- • 数据增强策略生成正负样本对
- • ResNet50编码器特征提取
- • NT-Xent损失函数优化
监督测试阶段
- • 迁移预训练权重参数
- • 添加全连接层进行分类
- • 微调模型参数
- • 建筑物形状预测与评估
ResNet50编码器
5阶段分层特征提取,逐步强化图像特征表示能力
NT-Xent损失函数
最大化正样本相似度,最小化负样本相似度
投影层设计
多层感知器实现特征压缩与表示增强
实验数据与设置
数据来源
OSM平台数据
高德开放平台
总计19,535个建筑物样本
数据分布
训练集
14,079个
测试集
5,456个
建筑物形状分类(18类)
C字形
E字形
F字形
H字形
长方形
L字形
圆形
凸字形
凹字形
Y字形
Z字形
π字形
艹字形
丰字形
井字形
正方形
十字形
梯形
实验结果分析
模型性能对比
| 模型 | 准确率 | F1_score | AUC | 标注需求 |
|---|---|---|---|---|
| CLTM (本文) | 93.79% | 0.932 | 0.997 | 无需标注 |
| AlexNet | 93.11% | 0.925 | 0.986 | 需要标注 |
| ResNet50 | 96.10% | 0.961 | 0.997 | 需要标注 |
训练过程可视化
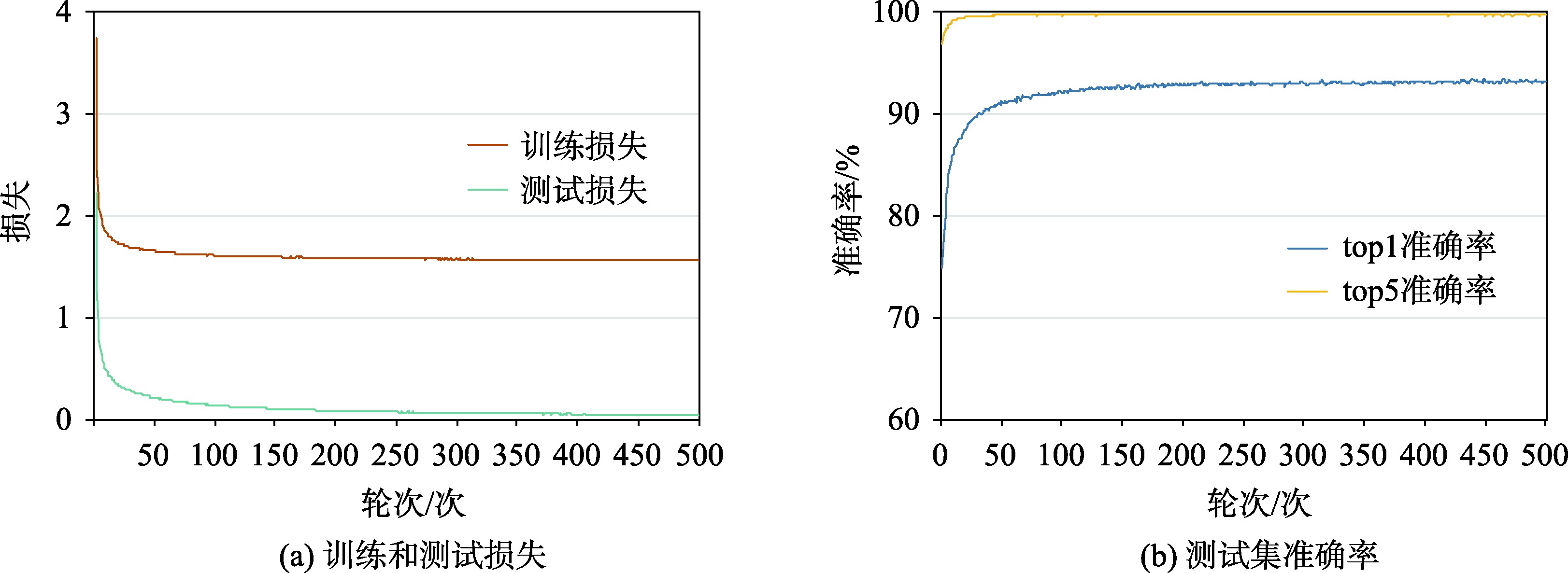
图2 损失和准确率变化趋势
主要贡献与创新
1
无监督特征学习
训练阶段无需样本标签,显著降低数据标注成本
2
对比学习机制
通过正负样本对比,增强同类形状聚集性
3
迁移学习策略
有效利用预训练特征,提升分类性能
4
减少视觉偏差
降低人工视觉偏差影响,提高识别客观性
以上内容由AI自动生成,内容仅供参考。对于因使用本网站以上内容产生的相关后果,本网站不承担任何商业和法律责任。