技术概述
核心任务
街景图像视觉位置识别(SV-VPR)是一种基于视觉特征信息的地理位置识别技术,其核心任务是通过分析街景图像的视觉特征,实现对未知地点的地理位置预测和精确定位。
技术挑战
- 昼夜光照差异
- 季节更替特征演变
- 视角偏差处理
- 动态环境适应
技术分类方法
传统手工特征方法
基于SIFT、SURF、HOG等手工设计特征的位置识别技术
深度学习方法
基于CNN和Vision Transformer的自动特征学习方法
视觉语言模型方法
基于VLMs的跨模态语义对齐位置识别技术
技术流程架构
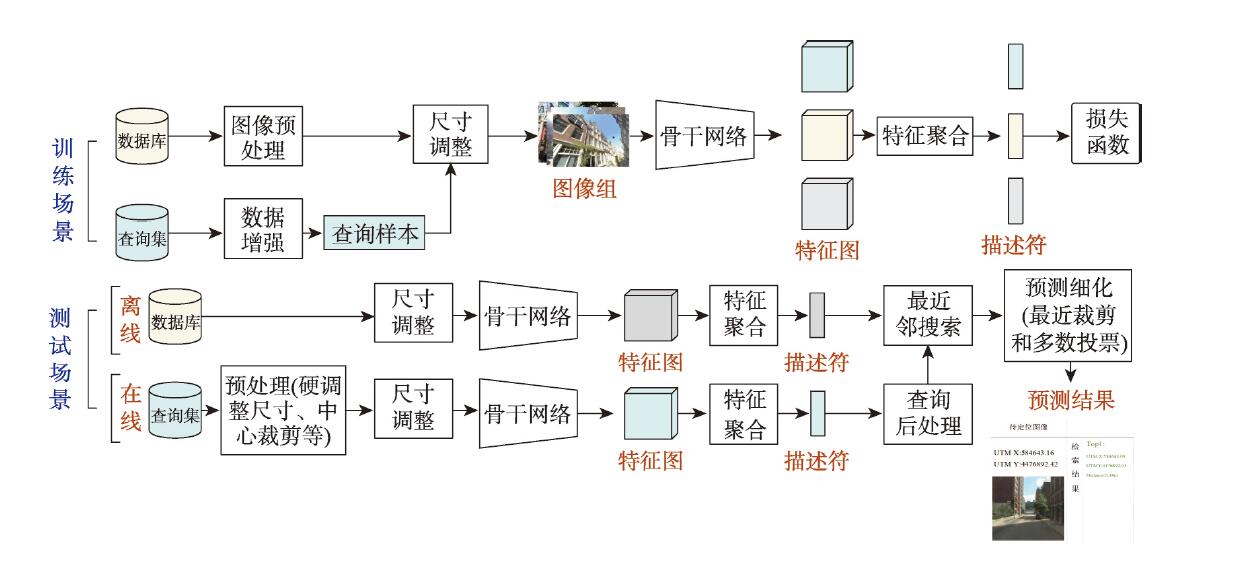
数据准备
构建图像数据库并进行预处理
特征提取
采用骨干网络获取深度特征
检索匹配
最近邻搜索与预测优化
后处理
排序过滤提升结果可靠性
关键技术研究
特征提取技术
- ResNet、VGG等骨干网络
- Vision Transformer架构
- DINOv2自监督学习
- 图神经网络建模
特征表达方法
- 基于池化的聚合方法
- 基于VLAD的聚合方法
- 注意力机制动态聚合
- 多尺度特征融合
相似性度量
- 三元组损失函数
- 多相似性损失
- 负例挖掘技术
- ArcFace损失优化
检索算法
- 最近邻搜索算法
- 投票方案策略
- 单阶段与双阶段检索
- HNSW图索引方法
典型数据集资源
主要VPR数据集对比
| 数据集 | 环境类型 | 查询集/张 | 参考集/张 | 条件变化 | 图片大小(像素) |
|---|---|---|---|---|---|
| Tokyo 24/7 | 户外 | 315 | 75,984 | 光照 | 3264×2448 |
| SF-XL | 城市 | 1,000 | 41.2M | 光照、季节 | 1024×768 |
| Pittsburgh | 城市 | 1,000 | 23,000 | 视角 | 640×480 |
| MSLS | 城市 | 11,000 | 19,000 | 天气、季节 | 640×480 |
| Nordland | 火车视角 | 2,760 | 27,592 | 季节 | 1920×1080 |
评价方法体系
直接评价指标
RecallRate@N
衡量前N个检索结果中包含正确匹配的查询比例
AUC-PR
精度-召回曲线下面积,评估综合性能
AUC-ROC
ROC曲线下面积,衡量分类性能
间接评价指标
特征编码时间
衡量算法特征提取阶段的计算效率
描述符大小
评估算法对存储资源的要求
PCU指标
综合考虑精度和效率的性能评估
未来发展方向
跨区域泛化能力
研究领域自适应、迁移学习和元学习方法,提升模型在未见过场景中的泛化性能。
动态环境适应
构建能实时处理车辆遮挡、行人移动、天气突变等动态干扰的鲁棒模型。
轻量化部署
开发适用于移动设备和边缘计算的轻量化模型,满足实时性和资源受限的要求。
多模态融合
整合视觉、激光雷达、GPS、IMU等多源传感器数据,构建更鲁棒的位置识别系统。
应用价值与前景
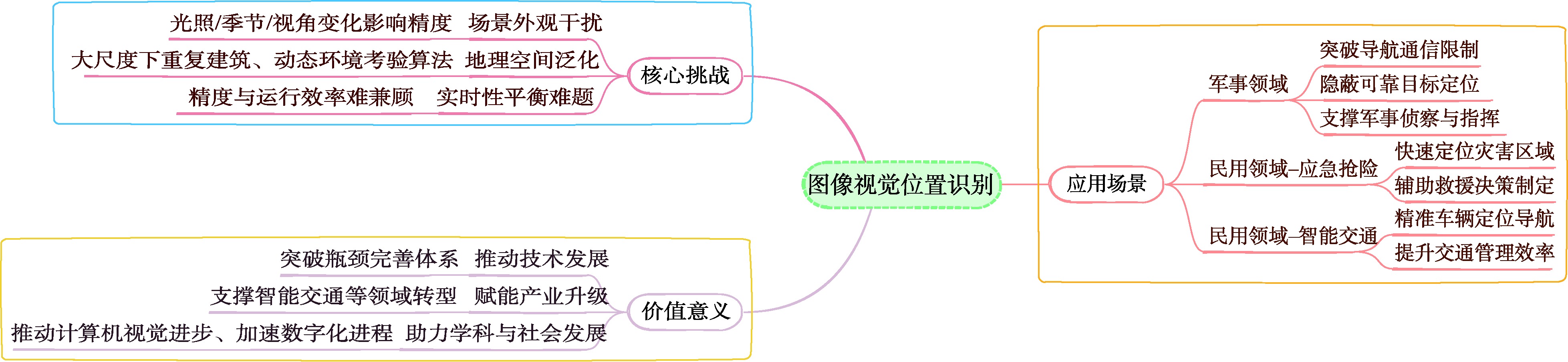
自动驾驶
高精度定位与导航,GPS信号缺失场景下的位置识别
机器人导航
室内外环境的自主导航与定位,SLAM系统优化
安防监控
智能监控系统,异常行为检测与位置追踪
应急救援
灾害现场快速定位,救援路径规划与导航
增强现实
AR场景融合,虚拟信息与真实环境精准叠加
智慧城市
城市管理优化,交通流量监控与分析
当前挑战与解决方案
场景外观变化
光照强度变化、季节更替、视角变换等因素显著影响识别精度
数据质量与标注
高质量标注数据稀缺,大量无标注数据的有效利用仍处于探索阶段
计算资源需求
深度学习模型训练计算资源需求庞大,硬件资源瓶颈制约应用效率
技术发展总结
街景图像视觉位置识别技术作为计算机视觉与地理信息科学的交叉领域,正在经历从传统手工特征向深度学习,再向视觉语言模型的技术演进。随着多模态融合、轻量化部署和跨域泛化能力的不断提升,该技术将在自动驾驶、智慧城市、应急救援等领域发挥越来越重要的作用,为构建智能化社会提供关键技术支撑。