研究概述
研究背景
视觉位置识别(VPR)是基于先前访问过的图像地理位置来估计目标图像地理位置的任务。传统方法采用手工特征表征图像,无法有效应对图像视角、光照、季节等复杂外观环境变化。
核心挑战
创新方法
本文提出MRGA-Mix方法,融合多级特征与关系感知全局注意力,构造鲁棒性强且泛化性好的图像全局描述符。
技术亮点
- 充分利用CNN特征提取过程中的多尺度特征
- 使用关系感知全局注意力增强融合特征
- 基于MixVPR构造紧凑鲁棒的图像描述符
- 多重相似性损失函数训练优化
性能表现
94.20%
Pittsburgh250k
Recall@1最高精度
83.81%
Tokyo 24/7
复杂光照变化场景
75.43%
Nordland
季节变化场景
与其他方法性能对比
Pittsburgh250k数据集对比
Tokyo 24/7数据集对比
技术流程
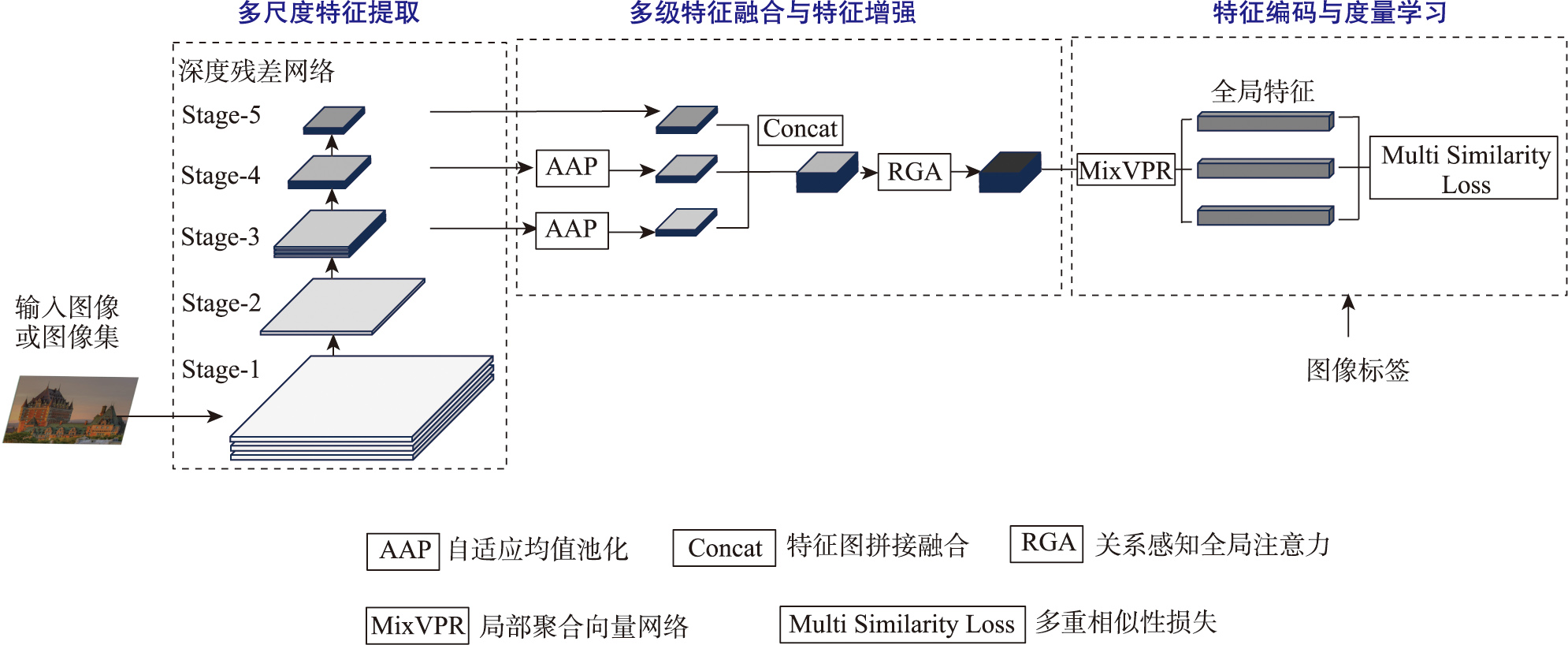
本文VPR方法技术流程
多尺度特征提取
- 基于ResNet18/34骨干网络
- 提取C3、C4、C5三层特征图
- 低层次、中层次、高层次特征
- 保留空间细节和语义信息
RGA特征增强
- 关系感知全局注意力机制
- 空间和通道双重注意力
- 抑制冗余噪声信息
- 增强关键目标特征
MixVPR编码
- 局部聚合向量网络
- 特征混合器处理
- 深度和行投影编码
- 紧凑鲁棒描述符生成
实验结果分析
数据集性能表现
不同VPR方法召回率比较
| 数据集 | MRGA-Mix | MixVPR | ConvAP | CosPlace | 提升幅度 |
|---|---|---|---|---|---|
| Pittsburgh250k | 94.20% | 91.75% | 91.52% | 89.89% | +2.45% |
| Pittsburgh30k | 91.56% | 89.30% | 88.84% | 87.45% | +2.26% |
| SF-XL-Val | 85.15% | 82.70% | 81.25% | 79.80% | +2.45% |
| Tokyo 24/7 | 83.81% | 80.00% | 72.06% | 63.17% | +3.81% |
| Nordland | 75.43% | 72.15% | 68.90% | 65.20% | +3.28% |
| SF-XL-Testv1 | 73.60% | 70.25% | 67.80% | 64.15% | +3.35% |
方法优势
- 在所有数据集上均实现最佳性能表现
- 对复杂环境变化具有强鲁棒性
- 多级特征融合提升表达能力
- 全局注意力机制增强关键特征
性能提升分析
技术细节
多级特征融合策略
低层次特征 (C3)
尺寸大、分辨率高、感受野小,空间细节信息丰富
中层次特征 (C4)
包含较多几何信息,对光照变化具有较好鲁棒性
高层次特征 (C5)
语义信息丰富,能有效克服视角变化
关系感知全局注意力
空间注意力 (RGA-S)
学习空间位置之间的依赖关系,获取空间注意力权重
通道注意力 (RGA-C)
建模通道间关系,增强重要特征通道
全局建模
从全局结构中挖掘特征间空间依赖关系
实验参数配置
输入图像
320×320像素
批处理大小
480
学习率
0.05 (初始)
应用前景与意义
自动驾驶
为自动驾驶车辆提供精确的视觉定位能力,增强在复杂环境下的导航性能
机器人导航
提升服务机器人和无人机的室外环境感知与定位精度
智慧城市
支持智慧城市建设中的视觉监控和位置服务应用
研究贡献与创新
理论贡献
- 提出多级特征融合策略
- 引入关系感知全局注意力机制
- 构建鲁棒的图像全局描述符
实用价值
- 显著提升复杂环境适应性
- 在多个数据集上达到最优性能
- 为实际应用提供技术支撑
研究结论
本文提出的MRGA-Mix方法通过融合多级特征与关系感知全局注意力,成功解决了现有视觉位置识别方法在复杂环境变化下鲁棒性不足的问题。实验结果表明,该方法在6个公开数据集上均取得了最优性能,特别是在具有光照、季节变化的复杂场景中表现突出。
性能领先
在所有测试数据集上达到最佳召回精度
鲁棒性强
对复杂环境变化具有良好适应性
泛化能力
在不同场景下均保持稳定性能